







1 什么是调度延时
在实际业务中,大多数情况下,线程都不是一直占着 cpu 在运行的。在读写文件,收发网络数据时,可能会阻塞,阻塞就会进入睡眠,触发调度;在线程等待锁的时候,也可能会触发睡眠进而触发调度,释放 cpu;有时候,线程里边还会显式调用 sleep() 进行睡眠,这样也会让出 cpu。
以线程 sleep() 为例,比如我们睡眠时间是 1ms。理想情况下,线程睡眠 1ms 之后就应该一点不差的开始执行。但是实际情况不是这样的,线程睡眠 1ms 之后,往往不能立即被执行,而是会延时一段时间。从线程被唤醒,到线程被真正执行的这段时间就是延迟执行的时间,这段时间就被称作调度延时。
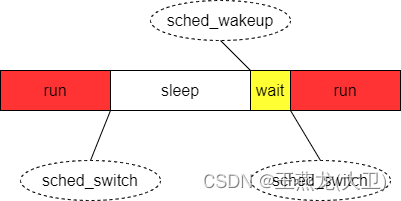
大部分应用的运行时序如下图所示。run 表示线程正在运行,sleep 表示线程在睡眠,wait 表示线程睡眠结束了,但是还没有被执行,处于等待状态。调度延时就是下图中 wait 持续的时间。
![]()
为什么会产生调度延时呢,为什么线程不能按我们预期的时序,在精确睡眠 1ms 之后就立即投入运行呢 ?
(1)cpu 还被占用着
当任务加入到运行队列中的时候,如果当前 cpu 还被其它任务占用着,那么刚唤醒的任务就不能立即运行,需要等当前的任务执行完毕之后,新任务才能被执行。
(2)需要在运行队列中排队
linux 中往往运行着很多应用,线程的个数远远大于 cpu 的个数。这样一个 cpu 核上就需要运行多个线程,多个线程就需要在运行队列中排队,交替执行。在运行队列中排队等待的时间也是调度延时的时间。
2 观测调度延时的方法
2.1 sched tracepoint
2.1.1 sched tracepoint 介绍
linux 内核提供了一个内核观测工具 tracepoint。关于 tracepoint,可以参考如下博客。
[linux][观测] ftrace,kprobe,tracepoint 入门
简单来说,tracepoint 就是内核在一些关键位置进行了埋点,当这些关键事件发生的时候,会打印一些信息。比如在内存管理方面,有 kmalloc 相关的埋点,在申请内存或者释放内存的时候,可以打印一些信息;在 tcp 协议栈中也有一些埋点,当 tcp 发生重传的时候,或者收到 rst 报文的时候,也可以打印对应的信息;在调度方面,当线程睡眠的时候以及线程被唤醒放入运行队列的时候,也可以打印信息。
tracepoint 在默认情况下是没有打开的,因为 tracepoint 会打印日志,多多少少会对性能产生影响。tracepoint 作为一种调试工具或者观测工具,当我们对某些事件感兴趣的时候,可以把对应的事件打开。
如下是调度相关的两个 tracepoint,sched_switch 和 sched_wakeup。当发生线程调度的时候,会触发 sched_switch 事件,当有线程被唤醒放入运行队列的时候,会触发 sched_wakeup 事件。
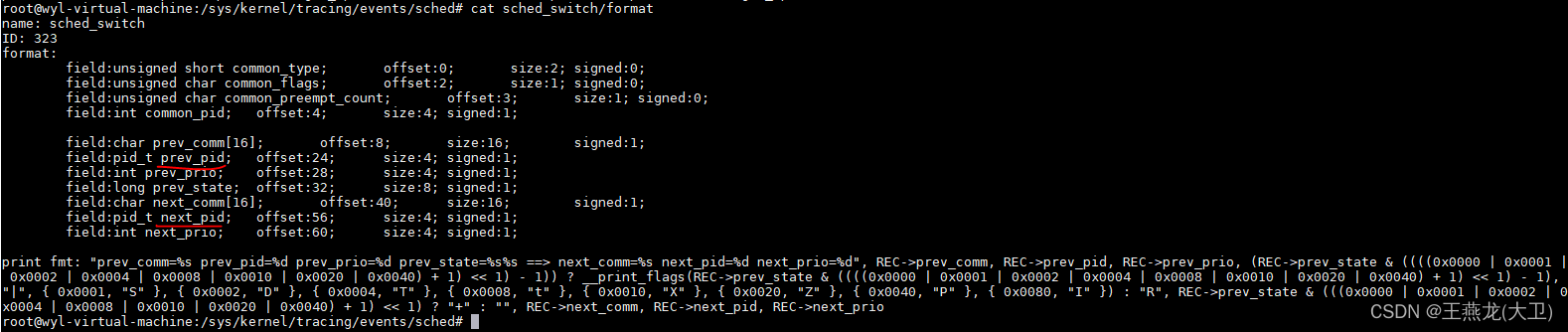
sched_switch 事件:
sched_switch 是当有线程切换的时候触发的事件。如下是当 sched_switch 触发的时候,打印的日志的格式,从前一个线程切换到下一个线程,可以看到主要的两个信息是 prev_pid 和 next_pid,prev_pid 是切换之前的线程 id,next_pid 是切换之后,下一个要运行的线程 pid。
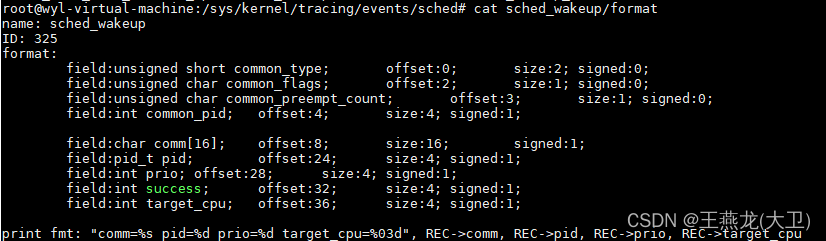
sched_wakeup 事件:
sched_wakeup 是当有线程从睡眠态被唤醒,将线程放到运行队列的时候触发的事件。如下图所示,主要的信息包括 pid,表示唤醒的是哪个任务,target_cpu 表示这个线程唤醒之后放到了哪个 cpu 上。
sched tracepoint 是观测调度延时的基础,本文后边介绍的内核模块的方式以及 perf sched 方法,工作基础也是 sched tracepoint。
2.1.2 使用 sched tracepoint
从上边的分析可以看出来,当线程被唤醒的时候会触发 sched_wakeup 事件;当线程真正被执行的时候会触发 sched_switch 事件,并且这个时候 sched_switch 打印信息中的 next_pid 是我们关心的 pid。打印日志中包含事件发生的时间,我们通过 sched_switch 和 sched_wakeup 的时间差,就可以计算出来调度延时。
使用如下代码作为观测的代码,代码中是一个 while(1) 死循环,死循环中睡眠 100ms。也就是每 100ms 调度一次。
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main() {
while (1) {
usleep(100 * 1000);
}
return 0;
}
使能 sched_wakeup 和 sched_switch:
echo 1 > sched_wakeup/enable
echo 1 > sched_switch/enable
日志保存在 trace 文件中,查看 trace 文件内容,并过滤我们进程名,可以看到相关的打印。下图中用红线标注的信息,第一行是 a.out 被唤醒的事件,第二行是 a.out 被真正执行的事件。从左侧的时间可以看出来 wakeup 的时间是 7489.500015,a.out 被真正执行的时间是 7489.500073,时间单位是秒,所以可以计算出来,这次调度延时是 58μs。

默认情况下,打开这两个事件之后,系统中所有进程发生调度的时候,都会打印日志。而在实际使用中,我们有时候只关心自己的应用。如何只打印我们关心的进程的信息呢 ? 可以通过 tracepoint 中的 filter 来实现。
如下两个命令,当 16489 这个线程被唤醒的时候,会打印信息;当 sched_switch 事件发生的时候,并且下一个要执行的线程是 16489 的时候,会打印信息。这样打印出来的两条信息,时间之差就是 16489 这个线程的调度延时。
echo "pid == 16489" > sched_wakeup/filter
echo "next_pid == 16489" > sched_switch/filter
如下所示,设置过滤器之后,trace 中的信息不再需要过滤,打印的日志均是 a.out 相关的。

2.2 通过内核模块来使用 sched tracepoint
直接使用 /sys/kernel/tracing/events/ 中的目录,通过修改配置文件的方式,打印了 wakeup 和 switch 的时间戳,但是要计算调度延时,还需要我们进行计算。
如下代码是一个内核模块,在内核模块中直接计算出了调度延时,使用更加灵活。内核模块介绍如下:
(1)my_param_ops
这是一个 callback 类型的参数。安装内核模块之后,在 /sys/module/sched_latency/parameters 下可以看到这个参数,通过 cat 和 echo 命令可以读取或修改这个参数的值。当通过 echo 修改参数的值的时候,就会调用函数 notify_param(),这样修改函数的时候调用内核模块中的函数,我们就可以在函数中捕捉一些信息,比较灵活。

(2)tracepoint_probe_register(), tracepoint_probe_unregister()
通过函数 tracepoint_probe_register() 可以向 tracepoint 中插入一个回调函数,这样当事件发生时就会调用这个回调函数。
tracepoint_probe_unregister() 操作与 tracepoint_probe_register() 相反。
(3) trace_sched_wakeup_hit(),trace_sched_switch_hit()
这两个函数分别是 wakeup 和 switch 两个事件发生的时候调用的回调函数。对于不同的内核版本来说,函数的入参可能是有区别的,如果要确定具体的形参列表,可以到文件夹 kernel/trace/ 中的相关文件中去确认。sched_switch 可以在 trace_sched_switch.c 中确认,sched_wakeup 可以在文件 trace_sched_wakeup.c 中确认。
(4)for_each_kernel_tracepoint()
这个是内核中的一个函数,可以遍历内核中的 tracepoint。内核中的一个 tracepoint 用一个结构体 struct tracepoint 来表示。本文中查找了 sched_wakeup 和 sched_switch 这两个 tracepoint。
/**
* for_each_kernel_tracepoint - iteration on all kernel tracepoints
* @fct: callback
* @priv: private data
*/
void for_each_kernel_tracepoint(void (*fct)(struct tracepoint *tp, void *priv),
void *priv)
{
for_each_tracepoint_range(__start___tracepoints_ptrs,
__stop___tracepoints_ptrs, fct, priv);
}
EXPORT_SYMBOL_GPL(for_each_kernel_tracepoint);// sched_latency.c
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
#include <linux/tracepoint.h>
#include <linux/timekeeping.h>
#include <linux/sched.h>
unsigned long long sched_wakeup_ts_ns = 0;
unsigned long long sched_switch_ts_ns = 0;
unsigned long long max_sched_latency = 0;
unsigned long long min_sched_latency = 10000000;
unsigned long long avg_sched_latency = 0;
unsigned long long get_timestamp_ns(void) {
struct timespec64 ts;
ktime_get_real_ts64(&ts);
return timespec64_to_ns(&ts);
}
int target_pid_int = 0;
int notify_param(const char *val, const struct kernel_param *kp) {
int res = param_set_int(val, kp);
if (res != 0) {
printk("set cb param failed\n");
return 0;
}
printk("target pid is %d\n", target_pid_int);
return 0;
}
const struct kernel_param_ops my_param_ops = {
.set = ¬ify_param,
.get = ¶m_get_int,
};
module_param_cb(target_pid_int, &my_param_ops, &target_pid_int, S_IWUSR | S_IRUSR);
static struct tracepoint *target_tp = NULL;
static void probe_tracepoint(struct tracepoint *tp, void *priv) {
char *n = priv;
if (strcmp(tp->name, n) == 0) {
printk("found tracepooint: %s\n", n);
target_tp = tp;
}
}
static struct tracepoint *find_tracepoint(const char *name) {
for_each_kernel_tracepoint(probe_tracepoint, (void *)name);
return target_tp;
}
static void trace_sched_wakeup_hit(void *__data, struct task_struct *p) {
if (target_pid_int <= 0) {
return;
}
if (p->pid != target_pid_int) {
return;
}
sched_wakeup_ts_ns = get_timestamp_ns();
printk("hit sched wakeup, pid = %d\n", target_pid_int);
}
static void trace_sched_switch_hit(void *__data, bool preempt,
struct task_struct *prev, struct task_struct *next) {
if (target_pid_int <= 0) {
return;
}
if (next->pid != target_pid_int) {
return;
}
static unsigned long long switch_to_count = 0;
static unsigned long long total_latency = 0;
sched_switch_ts_ns = get_timestamp_ns();
unsigned long long latency = sched_switch_ts_ns - sched_wakeup_ts_ns;
if (latency > max_sched_latency) {
max_sched_latency = latency;
}
if (latency < min_sched_latency) {
min_sched_latency = latency;
}
switch_to_count++;
total_latency += latency;
avg_sched_latency = total_latency / switch_to_count;
if (0 == switch_to_count % 100) {
printk("start --------------------------------\n");
printk("pid: %d\n", target_pid_int);
printk("total switch to count: %llu\n", switch_to_count);
printk("total sched latency: %llu\n", total_latency);
printk("max sched latency: %llu\n", max_sched_latency);
printk("min sched latency: %llu\n", min_sched_latency);
printk("avg sched latency: %llu\n", avg_sched_latency);
printk("end --------------------------------\n");
}
}
static int __init sched_latency_init(void) {
int ret;
target_tp = NULL;
struct tracepoint *tp = NULL;
tp = find_tracepoint("sched_wakeup");
if (!tp) {
printk("scheddebug, not find sched_wakeup\n");
return 0;
}
ret = tracepoint_probe_register(tp, trace_sched_wakeup_hit, NULL);
if (ret) {
printk(KERN_ERR "scheddebug, failed to register tracepoint probe\n");
return ret;
}
target_tp = NULL;
tp = NULL;
tp = find_tracepoint("sched_switch");
if (!tp) {
printk("scheddebug, ot find sched_switch\n");
return 0;
}
ret = tracepoint_probe_register(tp, trace_sched_switch_hit, NULL);
if (ret) {
printk("scheddebug, failed to register tracepoint probe\n");
return ret;
}
printk("scheddebug, sched latency module loaded\n");
return 0;
}
static void __exit sched_latency_exit(void) {
target_tp = NULL;
struct tracepoint *tp = NULL;
tp = find_tracepoint("sched_wakeup");
if (!tp) {
printk("scheddebug, not find sched_wakeup\n");
return;
}
tracepoint_probe_unregister(tp, trace_sched_wakeup_hit, NULL);
target_tp = NULL;
tp = NULL;
tp = find_tracepoint("sched_switch");
if (!tp) {
printk("scheddebug, not find sched_switch\n");
return;
}
tracepoint_probe_unregister(tp, trace_sched_switch_hit, NULL);
printk("scheddebug, Tracepoint example module unloaded\n");
}
module_init(sched_latency_init);
module_exit(sched_latency_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("wyl");
MODULE_DESCRIPTION("use sched_wakeup and sched_switch to get shced latency");
Makefile:
obj-m += sched_latyency.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
模块安装之后,我们可以将感兴趣的线程的 pid 写入模块参数中。打印信息如下,包括调度次数,以及最大调度延时,最小调度延时以及平均调度延时。如下打印信息统计到,最大调度延时为 793μs,最小为 21μs,平均调度原始为 237μs。

2.3 perf sched
(1)perf sched record
这个命令可以记录系统的调度信息。执行一段时间之后,使用 ctrl c 停掉 perf,记录的数据会保存到 perf.data 中。
(2)perf sched script
perf sched script 可以查看 perf.data 中记录的原始信息。如下图所示,可以看到 perf sched 记录的信息,这些信息是基于 tracepoint 中的事件,在其中可以看到 sched_wakeup,sched_switch,sched_stat_runtime 这些日志。
| sched_wakeup | 线程从睡眠态到唤醒时的事件,任务加到运行队列中 |
| sched_switch | 当发生任务调度时的事件,选择一个新的任务来执行 |
| sched_stat_runtime | 记录线程运行的时间 |

(3)perf sched latency --sort max
perf 内部的工具,可以在基础日志上进行统计分析,分析每个进程最大调度延时,平均调度延时这些关键信息。

(4)perf sched timehist
wait time 是线程上次 sched out 到这次 sched in 的时间;sch delay,调度延时,从唤醒到真正执行的这段时间;run time,线程实际运行的时间。

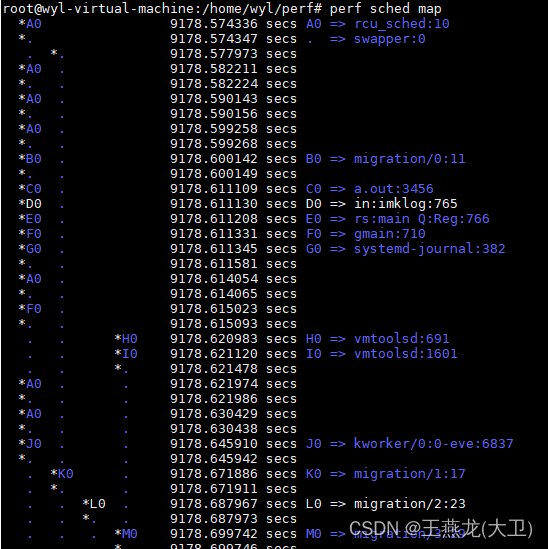
(5)perf sched map
显示 cpu 上发生的事件。
如下图所示,左边 4 列分别表示每个 cpu,前边带 * 表示这个 cpu 上发生了线程调度;用一个 . 来表示,说明 cpu 处于空闲状态。
3 发现调度延时高时怎么排查
(1)确认问题现象
通过上边介绍的工具,可以查看到调度延时增大的时候确切的时间以及发生在哪个核上。
(2)观察 cpu 使用情况和负载情况
使用 top 命令可以观察到 cpu 使用情况和负载信息。如果 cpu 使用率很高或者负载很高的话,那么说明系统的压力比较大了,出现延时增大是难以避免的情况。
平均负载超过 cpu 核的个数,说明负载偏高了。
cpu 总体使用率超过 100%,说明 cpu 使用率也偏高了。
(3)通过 /proc/interrupts 以及 /proc/softirqs 查看中断情况
是不是某个中断的处理次数在快速增长,cpu 都用来处理中断了。
top 命令也可以查看到每个 cpu 的中断和软中断使用情况。
(4)/proc/sched_debug
这个文件中可以查看每个 cpu 的运行队列以及负载情况。















 3362
3362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









