







 本文深入解析Word2Vec中的Skip-Gram模型,介绍如何通过给定单词预测与其共现的其他单词的概率,并详细阐述模型的网络结构、损失函数及训练过程。此外,还介绍了用于优化计算效率的Hierarchical Softmax和Negative Sampling方法。
本文深入解析Word2Vec中的Skip-Gram模型,介绍如何通过给定单词预测与其共现的其他单词的概率,并详细阐述模型的网络结构、损失函数及训练过程。此外,还介绍了用于优化计算效率的Hierarchical Softmax和Negative Sampling方法。
word2vec skip gram 直观理解
- 目标
根据给定的单词预测与该单词同处一个窗口内其他每个单词出现的概率 - 目标损失函数:
针对每个窗口内非target word 的context word,构建
C ( θ ) = − ∑ w i ∑ c = 1 C l o g p ( w O , c ∣ w I ) C(\theta) = - \sum_{w_i}\sum_{c=1}^Clogp(w_O,c | w_I) C(θ)=−wi∑c=1∑Clogp(wO,c∣wI)损失函数并利用最大似然估计进行求解。
- 网络结构
第一层为输入的单词one-hot向量,维度为1xV,V代表词表中所有词的个数。
中间为隐层,神经元个数代表了压缩后每个词向量的维数N,常见个数有100,200,300。
隐层和输入层间的矩阵V维度为VxN,待学习完成后,每一行的向量对应着词表中每个词作为target词时的词向量。
隐层和输出层间的矩阵N维度为NxV,待学习完成后,每一列的向量对应着词表中每个词每个词作为context 词时的词向量。
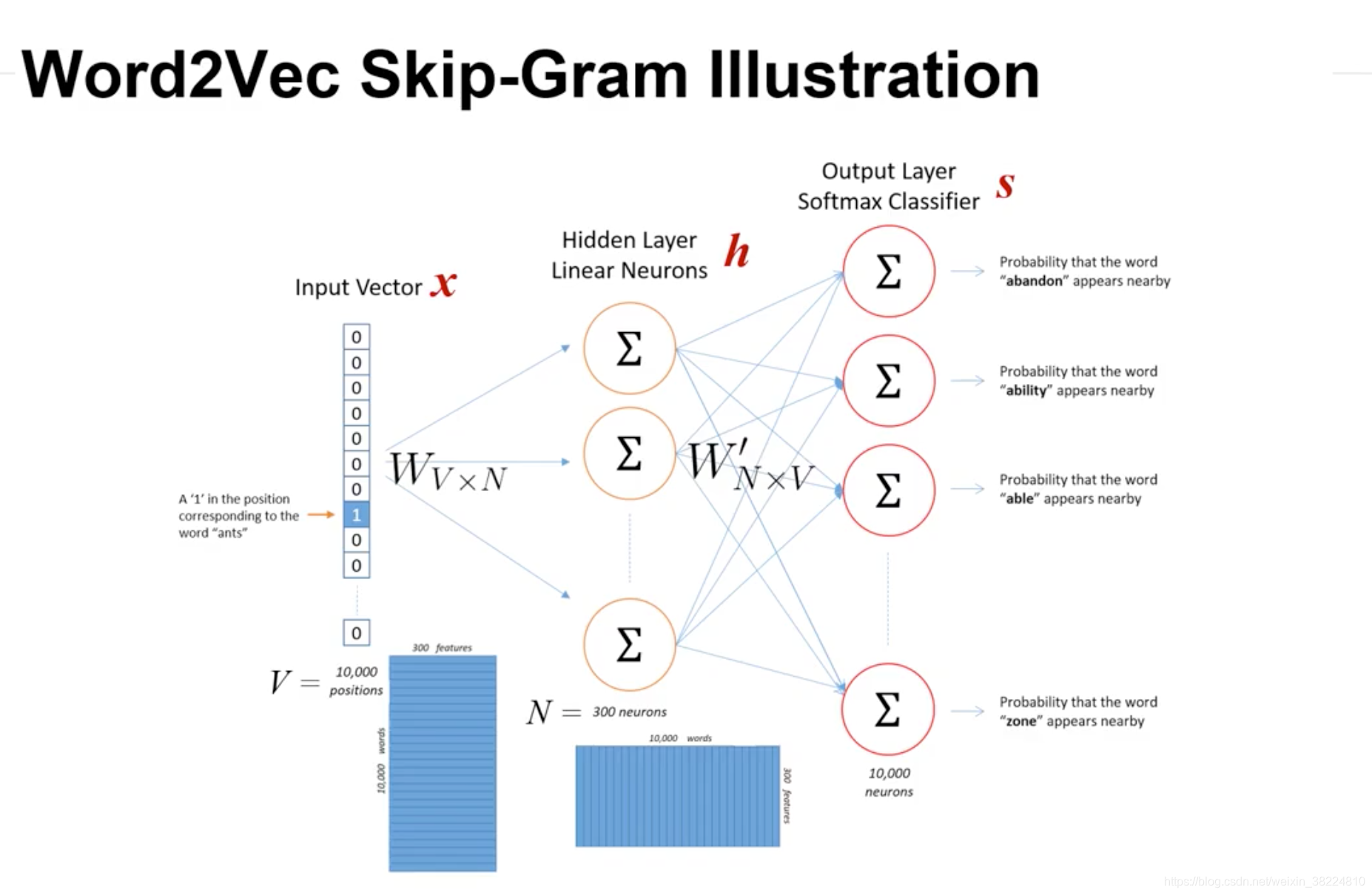
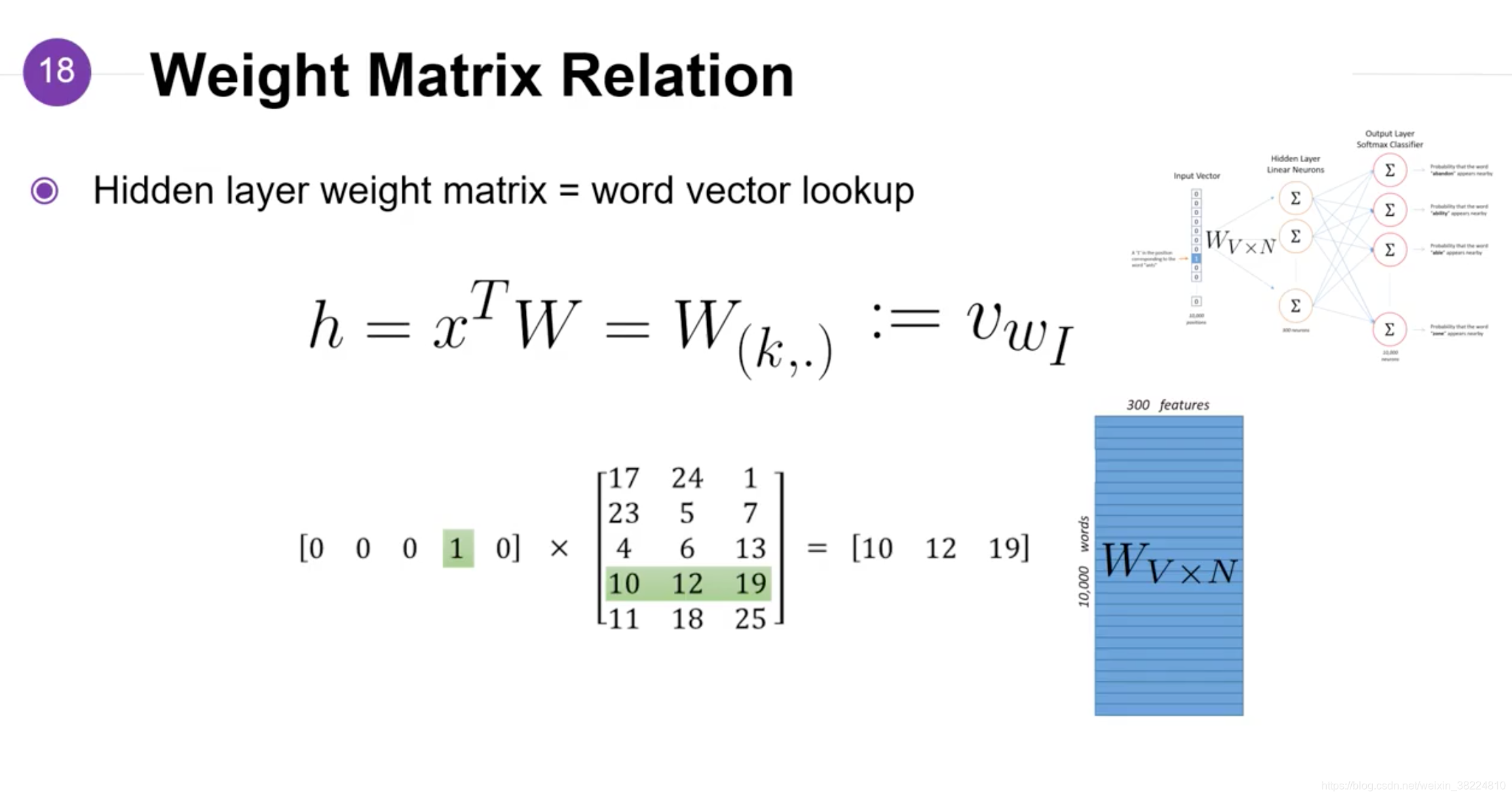
- 隐层权重矩阵V
我们用h代表输入词的one-hot向量x和V矩阵点积之后的结果,对应V矩阵中的第k行,x中等于1的那行为k,k的取值范围是整个词表的大小V。
- 隐层权重矩阵N
wj为窗口内任意一个context词,其向量 v w j ′ v'_{w_j} v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









