









14. CheckPoint
1. 适用场景
自定义Spark应用程序特别复杂,从初始RDD到整个应用完成有很多步骤,比如超过20个Transformation操作,而且整个应用运行的时间也特别长,比如1-5小时。
2. 为什么
对于特别复杂的Spark应用,很有可能需要重复使用某个RDD,若因为节点故障,导致先前持久化过的数据丢失,当再一次使用到该RDD时,就可能又要重新计算一次数据。=>容错性很差。
3. 功能:容错 与 高可用
对于某个复杂的RDD Chain,若其中某些 “关键的/后面会反复使用的” RDD可能因为节点故障导致持久化数据丢失,便可以对该RDD格外启动CheckPoint机制,尽量读取既存数据而减少计算次数,实现容错和高可用。
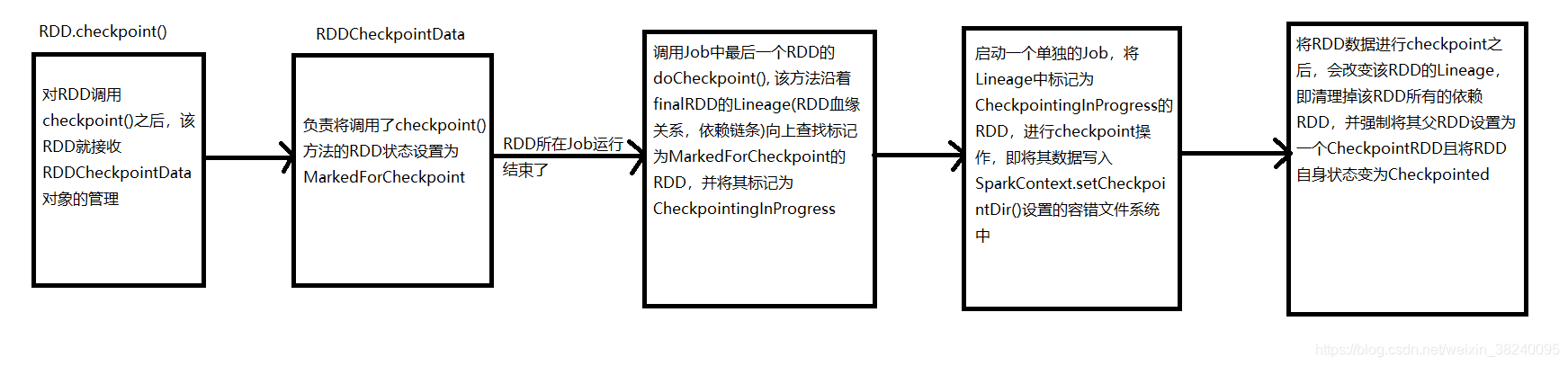
4. 原理
- 首先调用SparkContext.setCheckPointDir()设置一个容错的文件系统的目录,比如HDFS。
- 对某RDD.checkpoint()之后,该RDD就接受RDDCheckpointData对象的管理。它负责将调用了checkpoint()方法的RDD状态设置为MarkedForCheckPoint。
- RDD所处的Job运行结束后,调用Job中最后一个RDD的doCheckpoint(),该方法沿着finalRDD的Lineage(RDD血缘关系,依赖链条)向上查找标记为MarkedForCheckPoint的RDD,并将其标记为CheckpointingProgress。
- 启动一个单独的Job,将Lineage中标记为CheckpointingProgress的RDD进行checkpoint操作,即将其数据写入SparkContext.setCheckpointDir()设置的容错文件系统中。
- 将RDD数据进行checkpoint之后,会改变该RDD的Lineage,即清理掉该RDD所有的依赖RDD,并强制将其父RDD设置为一个CheckpointRDD且将RDD自身状态变为Checkpointed。
- 实现Checkpoint后,若后来某个Task又调用该RDD的iterator(),就实现了高容错机制,即使RDD的持久化数据丢失或者压根没有持久化,但依然可以通过readCheckpointOrCompute()优先从该RDD的父RDD——CheckpointRDD中读取来自外部文件系统的数据。
5. Checkpoint和持久化(persist/cache)的区别?
- 最主要的区别在于:
持久化只是将数据保存在BlockManager中,但是RDD之前所有的Lineage保持不变。而Checkpoint执行结束后,RDD已经没有之前所谓的前置依赖了,只有一个强行被设置的CheckpointedRDD(截断),即Checkpoint之后,RDD的Lineage发生了改变。 - 其次:
持久化的数据丢失的可能性更大,磁盘或内存故障。而Checkpoint通常是保存在容错好、高可用的文件系统如HDFS中,完全丢失的可能性非常低。
6.建议
通常建议,对需要Checkpoint的RDD,使用persist(StorageLevel.DISK_ONLY),该RDD计算之后,就直接将其持久化至磁盘,然后再进行Checkpoint操作时,将直接从磁盘上读取RDD的数据,并Checkpoint到外部文件系统即可,不需要重新计算一次RDD,这种Checkpoint效率就高得多。
7.源码
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but is available for implementors of custom
* subclasses of RDD.
*/
final def iterator (split : Partition, context: TaskContext): Iterator[ T] = {
// 若storageLevel不为NONE,也就是之前持久化过该RDD,那么就不会去直接从父RDD执行算子计算新RDD的partition
// 优先尝试使用CacheManager去获取持久化的数据
if (storageLevel != StorageLevel.NONE) {
getOrCompute( split, context)
} else {
// 否则,尝试从ChkPoint的持久化中获取
computeOrReadCheckpoint( split, context)
}
}
/**
* Compute an RDD partition or read it from a checkpoint if the RDD is checkpointing.
*/
private[spark] def computeOrReadCheckpoint (split : Partition, context: TaskContext): Iterator[ T] =
{
if (isCheckpointedAndMaterialized) {
//调用父RDD(CheckpointRDD)的iterator(),其实最终就是从外部文件系统中读取数据
firstParent[ T]. iterator( split, context)
} else {
compute(split, context)
}
}















 6544
6544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









