










总述:
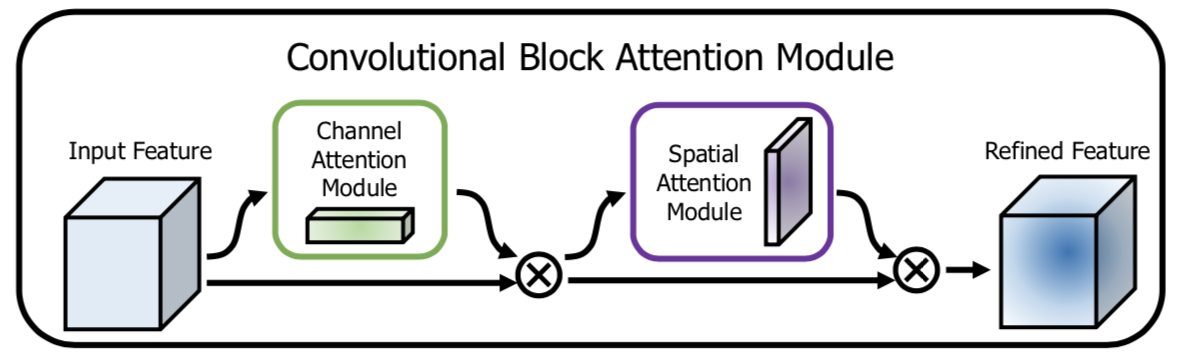
对于卷积神经网络生成的feature map,CBAM从通道和空间两个维度计算feature map的attention map,然后将attention map与输入的feature map相乘来进行特征的自适应学习。CBAM是一个轻量的通用模块,可以将其融入到各种卷积神经网络中进行端到端的训练。
也就是说由于CBMA模块输入和输出的featuremap大小是一致的,因此可用于网络的各层。

class ChannelAttentionModule(nn.Module):
def __init__(self, channel, ratio=16):
super(ChannelAttentionModule, self).__init__()
#使用自适应池化缩减map的大小,保持通道不变
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Conv2d(channel, channel // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(channel // ratio, channel, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x))
maxout = self.shared_MLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
#map尺寸不变,缩减通道
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, channel):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(channel)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out















 5529
5529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









