






转自知乎
这货就是基于 SE-Net [5]中的 Squeeze-and-Excitation module 来进行进一步拓展
具体来说,文中把 channel-wise attention 看成是教网络 Look 'what’;而spatial attention 看成是教网络 Look 'where',所以它比 SE Module 的主要优势就多了后者
------------------------------------
我们先看看 SE-module:
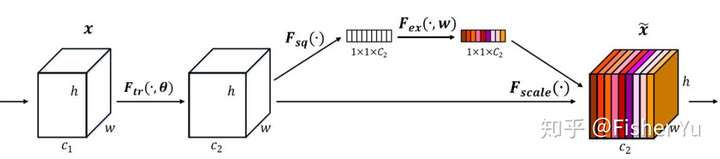 SE-module
SE-module
流程:
-
将输入特征进行 Global AVE pooling,得到 11 Channel
-
然后bottleneck特征交互一下,先压缩 channel数,再重构回channel数
-
-----------------------------------
再看看 CBAM :
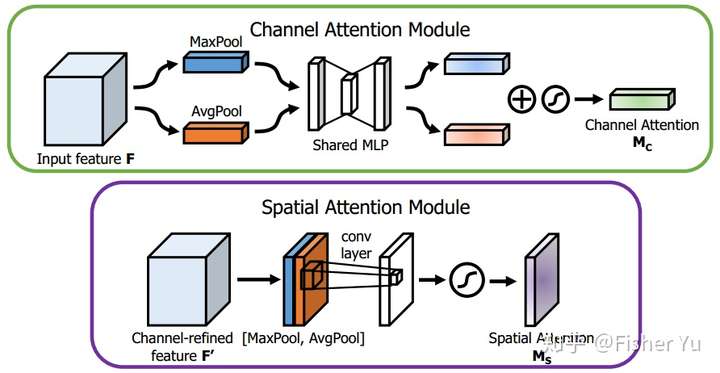 CBAM
CBAM
Channel Attention Module,基本和SE-module 是一致的,就额外加入了 Maxpool 的 branch。在 Sigmoid 前,两个 branch 进行 element-wise summation 融合。
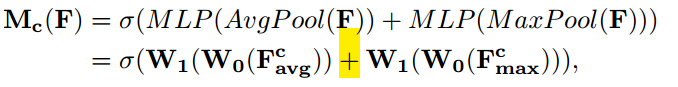
Spatial Attention Module, 对输入特征进行 channel 间的 AVE 和 Max pooling,然后 concatenation(并联),再来个7*7大卷积,最后 Sigmoid
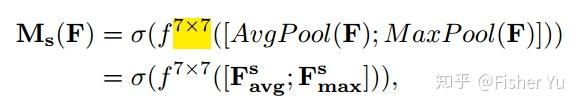
CBAM 特别轻量级,也方便在端部署,也可再cascade(串联)一下temporal attention,放进 video 任务里用~~
CDANet把Self-attention的思想用在图像分割,可通过long-range上下文关系更好地做到精准分割。
主要思想也是上述文章 CBAM 和 non-local 的融合变形:
把deep feature map进行spatial-wise self-attention,同时也进行channel-wise self-attetnion,最后将两个结果进行 element-wise sum 融合。
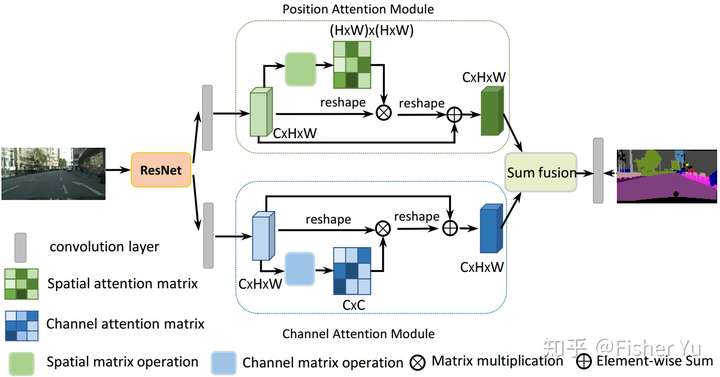 Dual Attention Network[6]
Dual Attention Network[6]
这样做的好处是:
在 CBAM 分别进行空间和通道 self-attention的思想上,直接使用了 non-local 的自相关矩阵 Matmul 的形式进行运算,避免了 CBAM 手工设计 pooling,多层感知器 等复杂操作。
[6]CDANet:Jun Fu et al., Dual Attention Network for Scene Segmentation, 2018
[5]Momenta, Squeeze-and-Excitation Networks,2017















 2497
2497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









