







大数据之电商分析系统(一)
一:项目介绍
本项目来源于企业级电商网站的大数据统计分析平台, 该平台以 Spark 框架为核心, 对电商网站的日志进行离线和实时分析。该大数据分析平台对电商网站的各种用户行为( 访问行为、购物行为、广告点击行为等)进行分析,根据平台统计出来的数据, 辅助公司中的 PM(产品经理)、数据分析师以及管理人员分析现有产品的情况, 并根据用户行为分析结果持续改进产品的设计,以及调整公司的战略和业务。最终达到用大数据技术来帮助提升公司的业绩、营业额以及市场占有率的目标。
本项目使用了 Spark 技术生态栈中最常用的三个技术框架, Spark Core、SparkSQL 和 Spark Streaming,进行离线计算和实时计算业务模块的开发。实现了包括用户访问 session 分析、页面单跳转化率统计、热门商品离线统计、广告流量实时统计4 个业务模块。通过合理的将实际业务模块进行技术整合与改造, 该项目几乎完全涵盖了 Spark Core、Spark SQL 和 Spark Streaming 这三个技术框架中大部分的功能点、知识点,学员对于 Spark 技术框架的理解将会在本项目中得到很大的提高。
二:项目框架
1. 项目整体框架
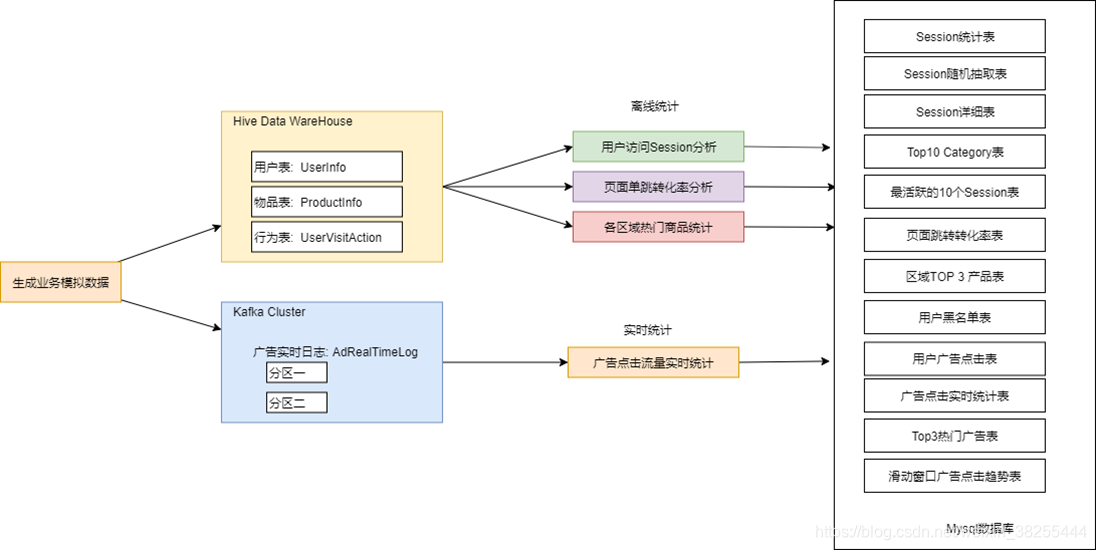
本项目分为离线分析系统与实时分析系统两大模块。
在离线分析系统中,我们将模拟业务数据写入 Hive 表中,离线分析系统从Hive 中获取数据,并根据实际需求(用户访问 Session 分析、页面单跳转化率分析、各区域热门商品统计) 对数据进行处理,最终将分析完毕的统计数据存储到MySQL 的对应表格中。
在实时分析系统中,我们将模拟业务数据写入 Kafka 集群中, 实时分析系统从 Kafka broker 中获取数据, 通过 Spark Streaming 的流式处理对广告点击流量进行实时分析,最终将统计结果存储到 MySQL 的对应表格中。
-
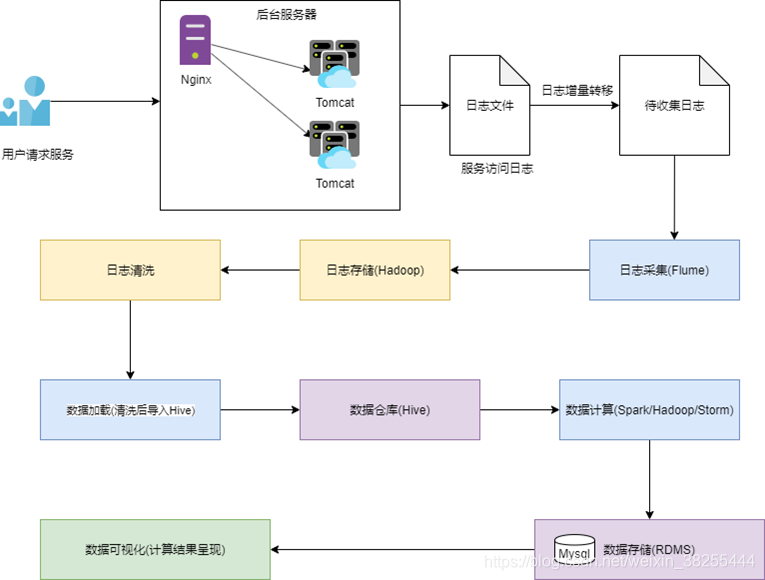
离线日志采集流程
-
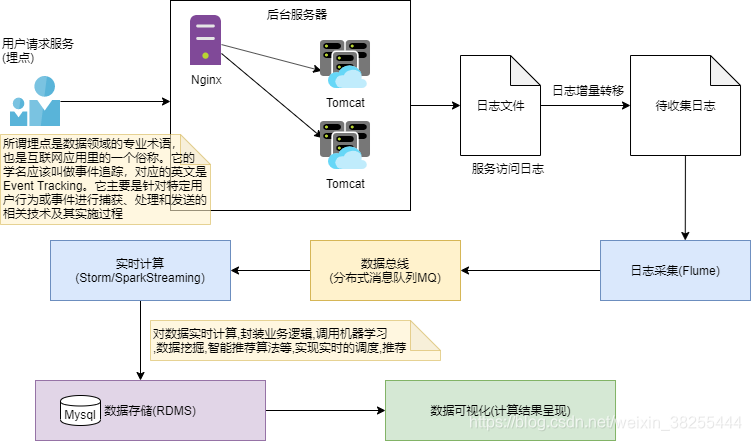
实时日志采集流程
-
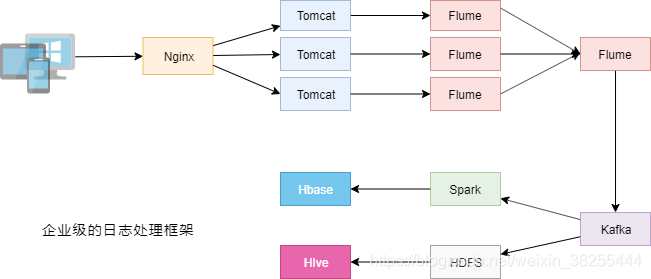
离线/实时日志采集框架
三:数据分析
-
离线数据分析
用户访问行为表(user_visit_action) —>存放网站或者 APP每天的点击流数据,就是用户对网站/APP 每点击一下, 就会产生一条存放在这个表里面的数据。
用户基本信息表(user_info) ----->是一张普通的用户基本信息表;这张表中存放了网站/APP 所有注册用户的基本信息.
商品信息表(product_info) ----->是一张普通的商品基本信息表; 这张表中存放了网站/APP所有商品的基本信息。
-
在线数据分析
程序每 5 秒向 Kafka 集群写入数据
格式 : timestamp province city userid adid
四、项目需求分析
-
用户访问session统计
用户在电商网站上, 通常会有很多的访问行为,通常都是进入首页, 然后可能点击首页上的一些商品,点击首页上的一些品类,也可能随时在搜索框里面搜索关键词,还可能将一些商品加入购物车,对购物车中的多个商品下订单,最后对订单中的多个商品进行支付。用户的每一次操作,其实可以理解为一个 action,在本项目中,我们关注点击、搜索、 下单、 支付这四个用户行为。
用户 session, 是在电商平台的角度定义的会话概念, 指的就是, 从用户第一次进入首页, session 就开始了。 然后在一定时间范围内, 直到最后操作完( 可能做了几十次、甚至上百次操作),离开网站, 关闭浏览器,或者长时间没有做操作, 那么 session 就结束了。以上用户在网站内的访问过程, 就称之为一次 session。 简单理解, session就是某一天某一个时间段内, 某个用户对网站从打开/进入, 到做了大量操作,到最后关闭浏览器。的过程,就叫做 session。session 实际上就是一个电商网站中最基本的数据和大数据。那么面向消费者/用户端的大数据分析( C 端), 最基本的就是面向用户访问行为/用户访问 session 的分析。该模块主要是对用户访问 session 进行统计分析,包括 session 聚合指标计算、 按时间比例随机抽取 session、 获取每天点击、 下单和购买排名前 10 的品类、 并获取 top10 品类中排名前 10的 session。该模块可以让产品经理、数据分析师以及企业管理层形象地看到各种条件下的具体用户行为以及统计指标,从而对公司的产品设计以及业务发展战略做出调整。主要使用 Spark Core 实现。- 页面单跳转换率统计
该模块主要是计算关键页面之间的单步跳转转化率,涉及到页面切片算法以及页面流匹配算法。该模块可以让产品经理、数据分析师以及企业管理层看到各个关键页面之间的转化率,从而对网页布局,进行更好的优化设计。主要使用SparkCore实现。
-
区域热门统计
该模块主要实现每天统计出各个区域的 top3 热门商品。 该模块可以让企业管理层看到电商平台在不同区域出售的商品的整体情况, 从而对公司的商品相关的战略进行调整。主要使用 Spark SQL 实现。
-
广告流量实时统计
网站 / app 中经常会给第三方平台做广告,这也是一些互联网公司的核心收入来源;当广告位招商完成后,广告会在网站 / app 的某个广告位发布出去,当用户访问网站 / app 的时候, 会看到相应位置的广告, 此时, 有些用户可能就会去点击那个广告。我们要获取用户点击广告的行为,并针对这一行为进行计算和统计。
用户每次点击一个广告以后,会产生相应的埋点日志;在大数据实时统计系统中,会通过某些方式将数据写入到分布式消息队列中( Kafka)。日志发送给后台 web 服务器( nginx), nginx 将日志数据负载均衡到多个Tomcat 服务器上, Tomcat 服务器会不断将日志数据写入 Tomcat 日志文件中,写入后,就会被日志采集客户端(比如 flume agent)所采集,随后写入到消息队列中( kafka),我们的实时计算程序会从消息队列中( kafka)去实时地拉取数据,然后对数据进行实时的计算和统计。
这个模块的意义在于, 让产品经理、高管可以实时地掌握到公司打的各种广告的投放效果。以便于后期持续地对公司的广告投放相关的战略和策略,进行调整和优化;以期望获得最好的广告收益。该模块负责实时统计公司的广告流量, 包括广告展现流量和广告点击流量。 实现动态黑名单机制, 以及黑名单过滤; 实现滑动窗口内的各城市的广告展现流量和广告点击流量的统计; 实现每个区域每个广告的点击流量实时统计;实现每个区域 top3 点击量的广告的统计。主要使用 Spark Streaming 实现。
五:项目需求具体实现
-
Session各范围访问步长、访问时长占比统计
需求一要统计出符合筛选条件的 session 中,访问时长在 1s3s、4s6s、7s9s、10s30s、30s60s、1m3m、3m10m、10m30m、30m 以上各个范围内的 session占比;访问步长在 13、46、79、1030、30~60、60 以上各个范围内的 session占比,并将结果保存到 MySQL 数据库中。
在计算之前需要根据查询条件筛选 session,查询条件比如搜索过某些关键词的用户、访问时间在某个时间段内的用户、年龄在某个范围内的用户、职业在某个范围内的用户、所在某个城市的用户,发起的 session。找到对应的这些用户的 session,并进行统计, 之所以需要有筛选主要是可以让使用者, 对感兴趣的和关系的用户群体,进行后续各种复杂业务逻辑的统计和分析,那么拿到的结果数据,就是只是针对特殊用户群体的分析结果;而不是对所有用户进行分析的泛泛的分析结果。比如说,现在某个企业高层,就是想看到用户群体中, 28~35 岁的,老师职业的群体, 对应的一些统计和分析的结果数据,从而辅助高管进行公司战略上的决策制定。
session 访问时长,也就是说一个 session 对应的开始的 action,到结束的 action,之间的时间范围;还有,就是访问步长,指的是,一个 session 执行期间内,依次点击过多少个页面,比如说,一次 session,维持了 1 分钟, 那么访问时长就是 1m,然后在这 1 分钟内,点击了 10 个页面, 那么 session 的访问步长,就是 10.
比如说,符合第一步筛选出来的 session 的数量大概是有 1000 万个。那么里面,我们要计算出,访问时长在 1s~3s 内的 session 的数量,并除以符合条件的总 session数量( 比如 1000 万),比如是 100 万/1000 万,那么 1s~3s 内的 session 占比就是 10%。依次类推,这里说的统计,就是这个意思。
这个功能可以让人从全局的角度看到,符合某些条件的用户群体,使用我们的产品的一些习惯。比如大多数人,到底是会在产品中停留多长时间, 大多数人,会在一次使用产品的过程中,访问多少个页面。那么对于使用者来说, 有一个全局和清晰的认识。
-
Session随机抽取
在符合条件的 session 中,按照时间比例随机抽取 1000 个 session这个按照时间比例是什么意思呢?随机抽取本身是很简单的,但是按照时间比例,就很复杂了。比如说,这一天总共有 1000 万的 session。那么我现在总共要从这 1000 万 session 中,随机抽取出来 1000 个 session。但是这个随机不是那么简单的。需要做到如下几点要求:首先,如果这一天的 12:00~13:00 的 session 数量是 100万,那么这个小时的 session 占比就是 1/10,那么这个小时中的 100 万的 session,我们就要抽取 1/10 * 1000 = 100 个。然后再从这个小时的 100 万 session 中,随机抽取出 100 个 session。以此类推,其他小时的抽取也是这样做。
这个功能的作用,是说,可以让使用者,能够对于符合条件的 session,按照时间比例均匀的随机采样出 1000 个 session,然后观察每个 session 具体的点击流/行为, 比如先进入了首页、然后点击了食品品类、然后点击了雨润火腿肠商品、然后搜索了火腿肠罐头的关键词、接着对王中王火腿肠下了订单、最后对订单做了支付。
之所以要做到按时间比例随机采用抽取,就是要做到,观察样本的公平性。
抽取完毕之后,需要将 Session 的相关信息和详细信息保存到 MySQL 数据库中。
数据源解析:
Session聚合数据 :AggrInfo 和 Session用户访问数据 UserVisitAction
-
Top10热门品类
在符合条件的 session 中,获取点击、下单和支付数量排名前 10 的品类。
数据中的每个 session 可能都会对一些品类的商品进行点击、下单和支付等等行为, 那么现在就需要获取这些 session 点击、下单和支付数量排名前 10 的最热门的品类。也就是说,要计算出所有这些 session 对各个品类的点击、下单和支付的次数, 然后按照这三个属性进行排序,获取前 10 个品类。
这个功能,很重要,就可以让我们明白, 就是符合条件的用户, 他最感兴趣的商品是什么种类。这个可以让公司里的人, 清晰地了解到不同层次、不同类型的用户的心理和喜好。计算完成之后, 将数据保存到 MySQL 数据库中。
数据源解析:
用户访问数据表: UserVisitAction
-
Top10热门品类Top10活跃Session****统计
对于排名前 10 的品类,分别获取其点击次数排名前 10 的 session。
这个就是说, 对于 top10 的品类, 每一个都要获取对它点击次数排名前 10 的session。
这个功能,可以让我们看到,对某个用户群体最感兴趣的品类, 各个品类最感兴趣最典型的用户的 session 的行为。计算完成之后,将数据保存到 MySQL 数据库中。
数据源解析:
用户访问数据表: UserVisitAction
需求1-4的具体代码实现
UserVisitSessionAnalyze
package com.ityouxin.session
import java.util.{Date, UUID}
import com.ityouxin.commons.conf.ConfigurationManager
import com.ityouxin.commons.constant.Constants
import com.ityouxin.commons.model.{UserInfo, UserVisitAction}
import com.ityouxin.commons.utils.{DateUtils, NumberUtils, ParamUtils, StringUtils, ValidUtils}
import com.ityouxin.session.DataModel.{SessionAggrState, SessionDetail, Top10Category, Top10Session}
import com.ityouxin.session.UserVisitSessionAnalyze.{getClickCategoryIdCountRDD, getOrderCategoryIdCountRDD, getPayCategoryIdCountRDD}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Dataset, SaveMode, SparkSession}
import net.sf.json.JSONObject
import org.apache.spark.storage.StorageLevel
import scala.collection.mutable
import scala.collection.mutable.{ArrayBuffer, ListBuffer}
import scala.util.Random
object UserVisitSessionAnalyze {
def main(args: Array[String]): Unit = {
//初始化sc
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("UserVisitSessionAnalyze")
//初始化SparkSession
val spark = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
//获取sc
val sc: SparkContext = spark.sparkContext
//根据配置工具类ConfigurationManager来获取config,获取任务配置
val jsonStr = ConfigurationManager.config.getString("task.params.json")
//将获取到的配置String转换成json格式,便于传递
val taskParm: JSONObject = JSONObject.fromObject(jsonStr)
//查询user_visit_action表中的数据(按照日期范围)
val userVisitActionRDD: RDD[UserVisitAction] = getActionRDDByDateRange(spark,taskParm)
//println(userVisitActionRDD.collect().mkString("/r/n"))
//将用户行为信息转换为k-v元组
val sessionidActionRDD: RDD[(String, UserVisitAction)] = userVisitActionRDD.map(uva => {
(uva.session_id, uva)
})
//缓存数据
sessionidActionRDD.persist(StorageLevel.MEMORY_ONLY)
//聚合解析写个方法进行分组、计算等操作
val sessionAggrInfoRDD: RDD[(String, String)] = aggregateBySession(spark,sessionidActionRDD)
//println(sessionidActionRDD.collect().mkString("\r\n"))
/*
进行下一步操作,计算步长和时长,累加更新session访问数、session访问时长范围、session访问步长范围,需要用到累加器进行对数据得叠加
*/
//创建一个累加器,进行计算每个excultor中的数据计算
val sessionAggrStateAccumulator = new SessionAggrStateAccumulator
//累加器需要注册,才能使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









