







🔥作者:雨晨源码🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目案例
💕💕文末获取源码
文章目录
本次文章主要是介绍基于hadoop+spark+大数据+机器学习+大屏的电商商品数据分析可视化系统
电商商品数据分析可视化系统-系统前言简介
- 随着互联网和电子商务的快速发展,电商行业在全球范围内迅速崛起,成为了商业领域的重要一环。电商平台的海量数据中蕴含着丰富的商业信息和价值,通过数据分析可以揭示出消费者的购物习惯、品牌偏好、市场趋势等重要信息。然而,如何有效利用这些数据,并将其转化为有价值的洞见和决策依据,一直是电商行业面临的挑战。
- 本文旨在介绍一种基于Hadoop、Spark和大数据技术的电商商品数据分析可视化系统。该系统通过对接电商平台的API接口,实时获取商品数据、销售数据、用户行为数据等,并利用大数据技术进行存储、处理和分析。同时,结合机器学习算法对商品进行分类、聚类和推荐等分析,以及数据可视化技术将分析结果在大屏上展示,为电商平台的运营决策提供数据支持。
- 本文的主要目的是设计并实现一个高效、可靠、可扩展的电商商品数据分析可视化系统。首先,本文将介绍系统的需求分析和技术选型,包括数据来源、数据类型、分析目标以及所涉及的技术和工具。其次,本文将详细阐述数据预处理、模型构建和数据可视化等关键技术的实现细节和优化方法。最后,本文将展示系统的测试结果和性能评估,并探讨未来的发展和应用前景。
- 通过本文的研究和实现,我们期望为电商行业提供一个实用的商品数据分析可视化工具,帮助电商平台更好地理解市场需求、优化产品策略、提升运营效率。同时,本文的研究成果也可以为其他类似领域的数据分析提供参考和借鉴。
spark电商商品数据分析可视化系统-开发技术与环境
- 开发语言:Python
- 技术:python+爬虫技术、Hadoop大数据分布式框架、Spark分析、机器学习、线性回归预测模型、Echarts可视化分析、产品评论数据情感分析
- 前端:Vue
- 数据库:MySQL
- 系统架构:B/S
- 开发工具:Python环境,pycharm,mysql(5.7或者8.0)
spark电商商品数据分析可视化系统-研究内容
- 大屏可视化(亮点:大屏可视化分析)
- 用户:登录注册、销量排行列表、生鲜类商品价格区间、各类商品的总评论数占比、服装类的商品的价格区间、各类型商品的数量
(1)需求分析:首先,需要明确毕设的需求,包括需要分析的电商商品数据的来源、数据类型、分析目标等。这需要与导师或相关人员进行深入的交流和讨论,以确保需求分析的准确性和完整性。
(2)技术选型:本题目涉及了多种技术和工具,包括Hadoop、Spark、大数据技术(如数据存储、数据处理、数据挖掘等)、机器学习(如分类、聚类、推荐等)、数据可视化等。需要根据需求和分析目标,选择合适的技术和工具,并进行相应的配置和优化。
(3)数据预处理:电商商品数据通常包含大量的噪声和异常值,需要进行数据清洗和预处理,以提高分析的准确性和可靠性。这包括数据筛选、缺失值处理、异常值处理、数据转换等。
(4)模型构建:根据需求和分析目标,选择合适的机器学习模型进行建模。可以考虑使用分类模型对商品进行分类,或者使用聚类模型对用户进行分组等。同时,需要考虑模型的评估和优化,以确保模型的准确性和泛化能力。
(5)数据可视化:利用数据可视化技术将分析结果呈现给用户,以便更直观地了解和分析数据。可以选择使用大屏展示可视化结果,以提供更好的交互性和实时性。
(6)系统设计和实现:根据需求和技术选型,设计并实现一个完整的电商商品数据分析可视化系统。需要考虑系统的可扩展性、可维护性、可重用性等。
(7)测试和优化:对系统进行全面的测试,包括功能测试、性能测试、安全测试等,以确保系统的稳定性和可靠性。同时,对系统进行优化,以提高系统的性能和用户体验。
(8)论文撰写:撰写毕设论文,总结整个毕设过程,包括需求分析、技术选型、数据预处理、模型构建、数据可视化、系统设计和实现等方面的内容。同时,需要注意论文的格式和排版,以及学术规范和引用格式等
spark电商商品数据分析可视化系统-演示图片
1.用户端页面:


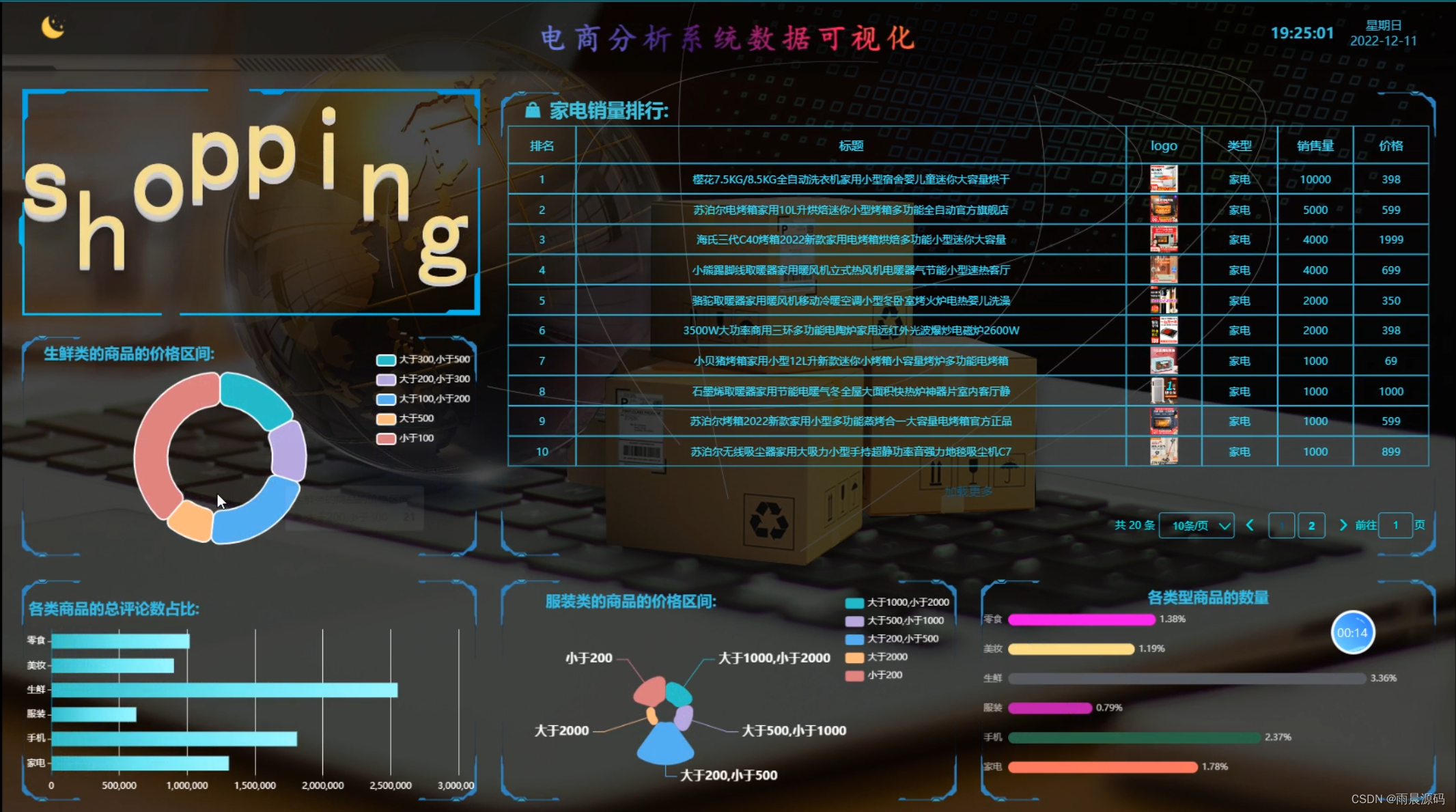
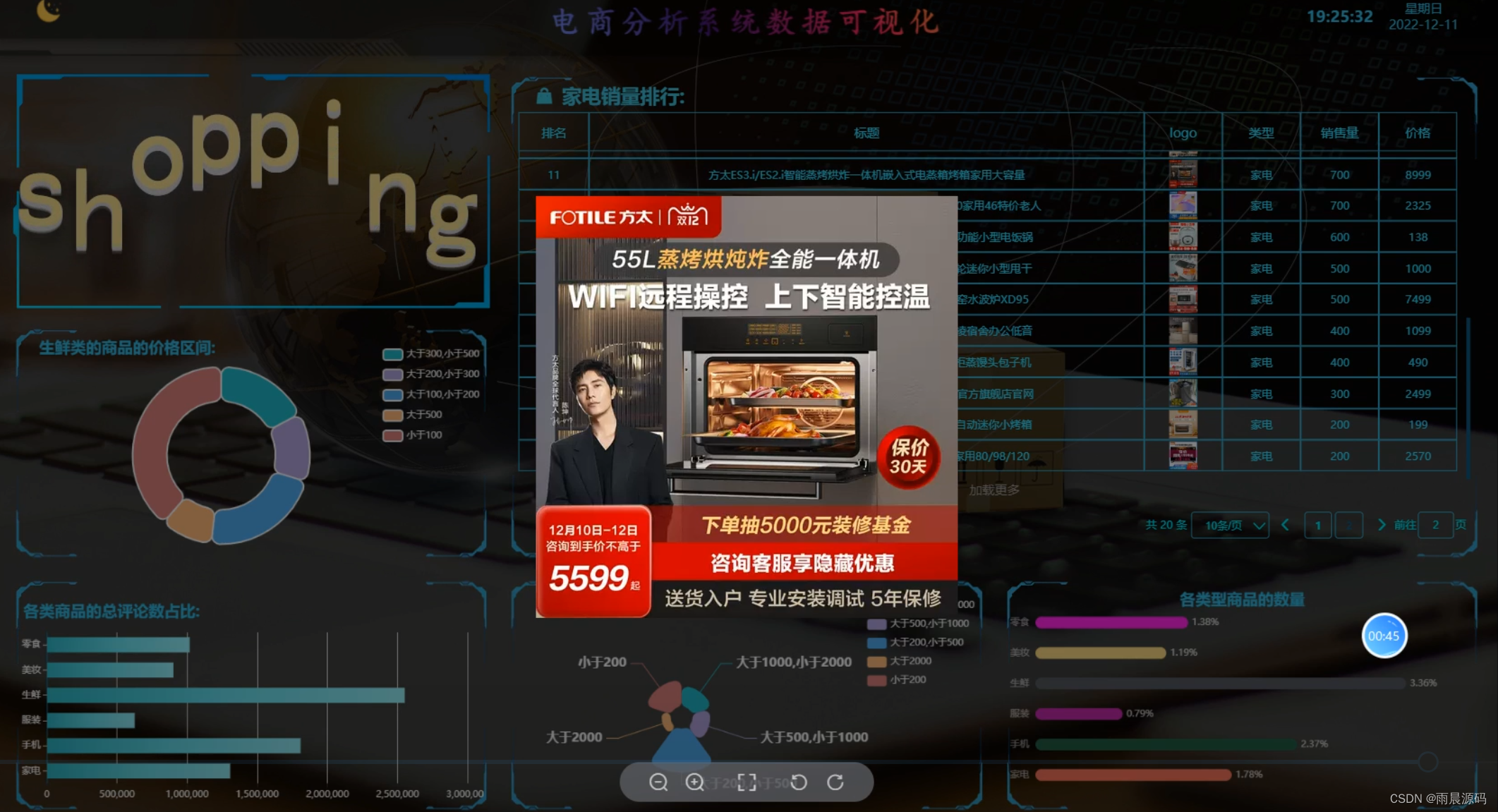
spark电商商品数据分析可视化系统-代码展示
1.爬虫代码【代码如下(示例):】
# 数据爬取文件
import scrapy
import pymysql
import pymssql
from ..items import ShoujixinxiItem
import time
import re
import random
import platform
import json
import os
from urllib.parse import urlparse
import requests
import emoji
# 手机信息
class ShoujixinxiSpider(scrapy.Spider):
name = 'shoujixinxiSpider'
spiderUrl = 'https://search.jd.com/s_new.php?keyword=%E6%89%8B%E6%9C%BA&pvid=a94b7c4f9cb54d89aa8cef3cd927d129&page={}&s=56&click=0'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def start_requests(self):
plat = platform.system().lower()
if plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'k2y49_shoujixinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if plat == 'windows_bak':
pass
elif plat == 'linux' or plat == 'windows':
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, 'k2y49_shoujixinxi') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('ul[class="gl-warp clearfix"] li.gl-item')
for item in list:
fields = ShoujixinxiItem()
fields["laiyuan"] = self.remove_html(item.css('div.p-img a::attr(href)').extract_first())
if fields["laiyuan"].startswith('//'):
fields["laiyuan"] = self.protocol + ':' + fields["laiyuan"]
elif fields["laiyuan"].startswith('/'):
fields["laiyuan"] = self.protocol + '://' + self.hostname + fields["laiyuan"]
fields["fengmian"] = self.remove_html(item.css('div.p-img a img::attr(data-lazy-img)').extract_first())
if fields["fengmian"].startswith('//'):
fields["fengmian"] = self.protocol + ':' + fields["fengmian"]
elif fields["fengmian"].startswith('/'):
fields["fengmian"] = self.protocol + '://' + self.hostname + fields["fengmian"]
fields["jiage"] = self.remove_html(item.css('div.p-price strong i::text').extract_first())
detailUrlRule = item.css('div.p-img a::attr(href)').extract_first()
if self.protocol in detailUrlRule:
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''div.sku-name''':
fields["biaoti"] = re.findall(r'''div.sku-name''', response.text, re.S)[0].strip()
else:
if 'biaoti' != 'xiangqing' and 'biaoti' != 'detail' and 'biaoti' != 'pinglun' and 'biaoti' != 'zuofa':
fields["biaoti"] = self.remove_html(response.css('''div.sku-name''').extract_first())
else:
fields["biaoti"] = emoji.demojize(response.css('''div.sku-name''').extract_first())
except:
pass
try:
if '(.*?)' in '''ul#parameter-brand li a::text''':
fields["pinpai"] = re.findall(r'''ul#parameter-brand li a::text''', response.text, re.S)[0].strip()
else:
if 'pinpai' != 'xiangqing' and 'pinpai' != 'detail' and 'pinpai' != 'pinglun' and 'pinpai' != 'zuofa':
fields["pinpai"] = self.remove_html(response.css('''ul#parameter-brand li a::text''').extract_first())
else:
fields["pinpai"] = emoji.demojize(response.css('''ul#parameter-brand li a::text''').extract_first())
except:
pass
try:
if '(.*?)' in '''</li>.*<li title='(.*?)'>商品产地''':
fields["spcd"] = re.findall(r'''</li>.*<li title='(.*?)'>商品产地''', response.text, re.S)[0].strip()
else:
if 'spcd' != 'xiangqing' and 'spcd' != 'detail' and 'spcd' != 'pinglun' and 'spcd' != 'zuofa':
fields["spcd"] = self.remove_html(response.css('''</li>.*<li title='(.*?)'>商品产地''').extract_first())
else:
fields["spcd"] = emoji.demojize(response.css('''</li>.*<li title='(.*?)'>商品产地''').extract_first())
except:
pass
try:
if '(.*?)' in '''</li>.*<li title='(.*?)'>运行内存''':
fields["yxnc"] = re.findall(r'''</li>.*<li title='(.*?)'>运行内存''', response.text, re.S)[0].strip()
else:
if 'yxnc' != 'xiangqing' and 'yxnc' != 'detail' and 'yxnc' != 'pinglun' and 'yxnc' != 'zuofa':
fields["yxnc"] = self.remove_html(response.css('''</li>.*<li title='(.*?)'>运行内存''').extract_first())
else:
fields["yxnc"] = emoji.demojize(response.css('''</li>.*<li title='(.*?)'>运行内存''').extract_first())
except:
pass
2.预测模型【代码如下(示例):】
# 线性回归模型
# X-特征 Y-标签
def load_linear_regression_model(X, y):
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 建立多元线性回归模型
regressor = LinearRegression()
regressor.fit(X_train, y_train)
# 进行预测
y_pred = regressor.predict(X_test)
# 模型的保存
with open('modelFiles/lr.pickle', 'wb') as f:
pickle.dump(regressor, f) # 将训练好的模型clf存储在变量f中,且保存到本地
# 计算误差指标
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
r2 = r2_score(y_test, y_pred)
logger.info("均方根误差:%s" % rmse)
logger.info("决定系数:%s" % r2)
# 可视化结果
plt.scatter(X_test[:, 1], y_test, color='red', label="真实值")
plt.scatter(X_test[:, 1], y_pred, color='blue', label="预测值")
plt.title("招聘网站薪资预测分析")
plt.xlabel("地点")
plt.ylabel("薪资")
plt.legend()
plt.show()
def run():
dp = DataPreprocess()
dataset = dp.data_preprocess()
print(len(dataset))
df = pd.DataFrame(dataset)
# print(df.info())
# print(df.corr())
X = df.drop(['salary'], axis=1).values
y = df['salary'].values
load_linear_regression_model(X, y)
def salary_predict(data):
dp = DataPreprocess()
item = {'area': dp.area_data_format(data['place']), 'exp': dp.exp_data_format(data['experience']),
'edu': dp.edu_data_format(data['education']), 'scale': dp.scale_data_format(data['scale'])}
skills = dp.skill_data_format(data['skill'])
# print(data['skill'], skills)
for skill, value in skills.items():
item[skill] = value
print(item)
print(item.values())
test_dataset = np.array([[i for i in item.values()]])
# print(test_dataset)
# 调用现行回归模型预测薪资
with open(r'D:\workSpace\boss_job_spider_flask\AnalysisModels\modelFiles\lr.pickle', 'rb') as f:
clf_load = pickle.load(f) # 将模型存储在变量clf_load中
res = clf_load.predict(test_dataset)
print(res) # 调用模型并预测结果
return res
if __name__ == '__main__':
run()
spark电商商品数据分析可视化系统-结语(文末获取源码)
💕💕
Java精彩实战毕设项目案例
小程序精彩项目案例
Python实战项目集
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。



















 8788
8788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











