






经典的卷积神经网络

1.经典CNN——AlexNet
2012年ImageNet LSVRC(大规模视觉识别挑战赛)冠军。TOP-5错误率15,。3%,远低于第二名的错误率(26.2%);TOP-1错误率37.5%
网络结构:

AlexNet 该模型一共分为八层,5个卷积层,,以及3个全连接层,在每一个卷积层中包含了激励函数RELU以及局部响应归一化(LRN)处理,然后再经过降采样(pool处理)。每一层的详细介绍及caffe代码可参考https://blog.csdn.net/Rasin_Wu/article/details/80017920
主要贡献:
-
防止过拟合:数据增强(data augmentation),Dropout
**数据增强:**利用平移、缩放、颜色等变换,人工增大训练集样本个数,从而获得更充足的训练集,使模型训练效果更好
Dropout:
用于全连接层,每次迭代以某概率将神经元输出置零,不参与前向和后向传播。产生不同的网络结构,进行组合,大大减少了过拟合。
缺点:训练时间增加

-
GPU实现:将网络分布在两个GPU上,且GPU之间某些层能够互相通信
-
非线性激活:RelU
-
大数据训练:120万ImageNet图像数据集
2.经典CNN——VGGNet
VGG Net由牛津大学的视觉几何组(Visual Geometry Group)和 Google DeepMind公司的研究员一起研发的的深度卷积神经网络,在 ILSVRC 2014 上取得了第二名的成绩,将 Top-5错误率降到7.3%。它主要的贡献是展示出网络的深度(depth)是算法优良性能的关键部分。目前使用比较多的网络结构主要有ResNet(152-1000层),GoogLeNet(22层),VGGNet(19层),大多数模型都是基于这几个模型上改进,采用新的优化算法,多模型融合等。到目前为止,VGG Net 依然经常被用来提取图像特征。
网络结构:
最常见的 VGG16结构图
输入是大小为224224的RGB图像,预处理(preprocession)时计算出三个通道的平均值,在每个像素上减去平均值(处理后迭代更少,更快收敛)。
图像经过一系列卷积层处理,在卷积层中使用了非常小的33卷积核,在有些卷积层里则使用了11的卷积核。
卷积层步长(stride)设置为1个像素,33卷积层的填充(padding)设置为1个像素。池化层采用max pooling,共有5层,在一部分卷积层后,max-pooling的窗口是2*2,步长设置为2。
卷积层之后是三个全连接层(fully-connected layers,FC)。前两个全连接层均有4096个通道,第三个全连接层有1000个通道,用来分类。所有网络的全连接层配置相同。
全连接层后是Softmax,用来分类。
所有隐藏层(每个conv层中间)都使用ReLU作为激活函数。VGGNet不使用局部响应标准化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间(LRN:Local Response Normalization,局部响应归一化,用于增强网络的泛化能力)。
各种VGG的网络结构

VGGNet各级别网络参数设置

VGGNet与AlexNet的异同: -
VGGNet可以看成加深版本的AlexNet
-
VGGNet有5个卷积组
VGGNet拥有5段卷积,每一段内有2~3个卷积层,同时每段尾部会连接一个最大池化层来缩小图片尺寸。每段内的卷积核数量一样,越靠后的段的卷积核数量越多:64-128-256-512 -512。其中经常出现多个完全一样的33的卷积层堆叠在一起的情况,这其实是非常有用的设计。如下图所示,两个33的卷积层串联相当于1个55的卷积层,即一个像素会跟周围55的像素产生关联,可以说感受野的大小为55。而3个33的卷积层串联起来的效果则相当于1个77的卷积层。除此之外,3个串联的33的卷积层,拥有比1个77的卷积层更少的参数量,只有后者的(333)/(77)=55%。更重要的是,3个33的卷积层拥有比1个77的卷积层更多的非线性变换(前者可以使用三次ReLU激活函数,而后者只有一次),使得CNN对特征的学习能力更强。
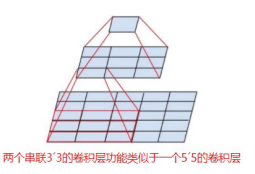
-
卷积核大小:3x3
-
卷积核深度:大部分都采用了逐层递增的方式
3.经典CNN——GoogLeNet
2014年,GoogLeNet和VGG是当年ImageNet挑战赛(ILSVRC14)的双雄,GoogLeNet获得了第一名、VGG获得了第二名,这两类模型结构的共同特点是层次更深了。VGG继承了LeNet以及AlexNet的一些框架结构(详见 大话CNN经典模型:VGGNet),而GoogLeNet则做了更加大胆的网络结构尝试,虽然深度只有22层,但大小却比AlexNet和VGG小很多,GoogleNet参数为500万个,AlexNet参数个数是GoogleNet的12倍,VGGNet参数又是AlexNet的3倍,因此在内存或计算资源有限时,GoogleNet是比较好的选择;从模型结果来看,GoogLeNet的性能却更加优越。
基于Inception构建了GoogLeNet的网络结构如下(共22层)

具体各Inception版本的详细介绍参考https://my.oschina.net/u/876354/blog/1637819
4.经典CNN——ResNet
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。ResNet的主要思想是在网络中增加了直连通道,即Highway Network的思想。此前的网络结构是性能输入做一个非线性变换,而Highway Network则允许保留之前网络层的一定比例的输出。ResNet的思想和Highway Network的思想也非常类似,允许原始输入信息直接传到后面的层中,如下图所示。
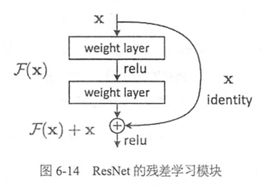
这样的话这一层的神经网络可以不用学习整个的输出,而是学习上一个网络输出的残差,因此ResNet又叫做残差网络。
网络结构
在ResNet网络结构中会用到两种残差模块,一种是以两个33的卷积网络串接在一起作为一个残差模块,另外一种是11、33、11的3个卷积网络串接在一起作为一个残差模块。它们如下图所示。

ResNet有不同的网络层数,比较常用的是50-layer,101-layer,152-layer。它们都是由上述的残差模块堆叠在一起实现的。
















 1462
1462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









