







关于数据集dataset类,这里面有个专栏解释的比较详细了:
Pytorch中的dataset类——创建适应任意模型的数据集接口_木盏-CSDN博客_dataset类
为了把整个数据集看明白我们就照着这个思路往下走。先把数据集的代码放出来
class DIMDataset(Dataset):
def __init__(self, split):
self.split = split
filename = '{}_names.txt'.format(split)
with open(filename, 'r') as file:
self.names = file.read().splitlines()#按行读取文件并存储在names变量中
self.transformer = data_transforms[split]
def __getitem__(self, i):
name = self.names[i]
fcount = int(name.split('.')[0].split('_')[0])
bcount = int(name.split('.')[0].split('_')[1])
im_name = fg_files[fcount]
bg_name = bg_files[bcount]
img, alpha, fg, bg = process(im_name, bg_name)
# crop size 320:640:480 = 1:1:1
different_sizes = [(320, 320), (480, 480), (640, 640)]
crop_size = random.choice(different_sizes)
trimap = gen_trimap(alpha)
x, y = random_choice(trimap, crop_size)
img = safe_crop(img, x, y, crop_size)
alpha = safe_crop(alpha, x, y, crop_size)
trimap = gen_trimap(alpha)
# Flip array left to right randomly (prob=1:1)
if np.random.random_sample() > 0.5:
img = np.fliplr(img)
trimap = np.fliplr(trimap)
alpha = np.fliplr(alpha)
x = torch.zeros((4, im_size, im_size), dtype=torch.float)
img = img[..., ::-1] # RGB
img = transforms.ToPILImage()(img)#将数据转化成PIL Image类型
img = self.transformer(img)
x[0:3, :, :] = img
x[3, :, :] = torch.from_numpy(trimap.copy() / 255.)
y = np.empty((2, im_size, im_size), dtype=np.float32)
y[0, :, :] = alpha / 255.
mask = np.equal(trimap, 128).astype(np.float32)
y[1, :, :] = mask
return x, y
def __len__(self):
return len(self.names)
直接看看getitem方法里面在 i 进入遍历的时候数据集要产生的两样东西:x和y对应是什么。这就要把getitem全都单拿出来看看。
def __getitem__(self, i):
name = self.names[i]
fcount = int(name.split('.')[0].split('_')[0])
bcount = int(name.split('.')[0].split('_')[1])
im_name = fg_files[fcount]
bg_name = bg_files[bcount]
img, alpha, fg, bg = process(im_name, bg_name)
# crop size 320:640:480 = 1:1:1
different_sizes = [(320, 320), (480, 480), (640, 640)]
crop_size = random.choice(different_sizes)
trimap = gen_trimap(alpha)
x, y = random_choice(trimap, crop_size)
img = safe_crop(img, x, y, crop_size)
alpha = safe_crop(alpha, x, y, crop_size)
trimap = gen_trimap(alpha)
# Flip array left to right randomly (prob=1:1)
if np.random.random_sample() > 0.5:
img = np.fliplr(img)
trimap = np.fliplr(trimap)
alpha = np.fliplr(alpha)
x = torch.zeros((4, im_size, im_size), dtype=torch.float)
img = img[..., ::-1] # RGB
img = transforms.ToPILImage()(img)#将数据转化成PIL Image类型
img = self.transformer(img)
x[0:3, :, :] = img
x[3, :, :] = torch.from_numpy(trimap.copy() / 255.)
y = np.empty((2, im_size, im_size), dtype=np.float32)
y[0, :, :] = alpha / 255.
mask = np.equal(trimap, 128).astype(np.float32)
y[1, :, :] = mask
return x, y
从后往前看看,返回的y是对应的mask值的变形,x对应的是img值变形。那么从开头往下看,self.name对应就是输入的split值的文件,回头看一下实际使用时候的代码

到这里就明白了split就是对应的输入值,在train函数里面对应的就是两个:train和valid这两个字符串,对应的就是文件里面的两个文件:train_names.txt和valid_names.txt。到这里就不得不把这俩文件打开来看看是什么了。下面打开的是train_names

找这个名字搜了一圈,找到了文件的所在地

再看看valid_names

最后搜罗了一圈,也都是在merge文件夹里面,属于都在一个文件夹里面分出来的一部分测试集一部分验证集。要想看到这些就必须要先把pre_process.py运行才能把所有的图片都导出来。为了把getitem的读取文件弄明白,这就试验一下。
第一步:复制出来train_names.txt
第二步:直接按行读取并打印结果
然后就出现了这样的东西

这些肯定不是全部,那么对应以下train_names文件本身每一行的内容,每一条都有逗号和空格隔开。放大一些看看就更清楚。

由此猜测getitem的前两句应该是为了把名字隔开,但是本身 i 是作为遍历的元素对应i位置的结果对x和y,那么按照这个道理来说 names[i] 是对应第i+1个元素,在实验代码里面也得到了证实,那么split是针对这个元素在做什么需要细扣一下。
![]()
如果直接说代码是干嘛的反而没啥用,干脆就直接用实例走一次看看具体是怎么回事。我们先以name[1]这个数据为例。
name[1] = 0_2.png
fcount = names[1].split('.')[0].split('_')[0] = 0
bcount = names[1].split('.')[0].split('_')[1] = 1fcount就是得到了在符号 . 之前,也就是图片对应的除了.png 的文件命名 中的 _ 前面的数字
bcount就是 _后面的数字
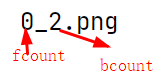
这两个东西到后来是干什么的,接着往下看。下一句代码:im_name = fg_files[fcount] 这里面fg_files在文件的前面有所定义,跟这个相关联的也有一组相似代码
with open('Combined_Dataset/Training_set/training_fg_names.txt') as f:
fg_files = f.read().splitlines()
with open('Combined_Dataset/Training_set/training_bg_names.txt') as f:
bg_files = f.read().splitlines()
with open('Combined_Dataset/Test_set/test_fg_names.txt') as f:
fg_test_files = f.read().splitlines()
with open('Combined_Dataset/Test_set/test_bg_names.txt') as f:
bg_test_files = f.read().splitlines()这四个都是把文件逐行打开保存文件数据,那么事不宜迟先看看fg_files对应的那条文件。

按照名字搜罗一圈找一找对应的位置在哪。

再看看bg_files对应的文件以及图片所在位置。


这个文件对应的东西是什么以及有什么作用,对照着bg来看按照字面的意思理解是前景和背景,粗略估计这就是需要扣出来的原图。那么干脆就把这两个东西合一起看看,也就是看图说话。
im_name = fg_files[fcount]
bg_name = bg_files[bcount]把上面得出来的fcount=0填进去,对应到fg_files[0]对应那张图,也就是此时im_name=035A4301.jpg

那么对于bg_name来说,bg_name = bg_files[2] 对应到bg_files就是COCO_train2014_000000000030.jpg,长这样

那么原来的图片0_2.png 则是这个造型,对应的文件夹在Deep-Image-Matting-PyTorch-master\data\merged

这个数据集精妙之处就来了。merged是合成后的图片,我们训练的目的就是在合成后的图片中把中间这个东西给抠出来,那么抠出来就要有所对应有所合成,所以fg存放的是前景也就是我们需要扣出来的部分,bg存放的是背景。在merged的图片命名规则就是:前景对应的位置_背景对应的位置.png 这招虽然不算多么天才,但我在发现这点的时候已经足够颤抖了。
fcount = 前景图片位置
bcount = 背景图片位置
im_name= 前景图片的文件名
bg_name= 背景图片文件名下一步到了这句:img, alpha, fg, bg = process(im_name, bg_name),就要返回到process函数里面看具体能生成什么东西。
def process(im_name, bg_name):
im = cv.imread(fg_path + im_name)
a = cv.imread(a_path + im_name, 0)
h, w = im.shape[:2]
bg = cv.imread(bg_path + bg_name)
bh, bw = bg.shape[:2]
wratio = w / bw
hratio = h / bh
ratio = wratio if wratio > hratio else hratio
if ratio > 1:
bg = cv.resize(src=bg, dsize=(math.ceil(bw * ratio), math.ceil(bh * ratio)), interpolation=cv.INTER_CUBIC)
return composite4(im, bg, a, w, h)那么这里面有些变量就都在config.py文件里面,这个文件就是为了把单独的参数拿出来方便设置修改。

这里面就出现了一个之前没出现的文件目录:mask目录,我们看一眼这里面都是什么

这里面都是对应fg_name的蒙版图,也就是原本数据集给的抠出来的正确答案。按照模型所述,把图片和trimap输入模型后出来的结果与mask蒙版图的数据进行比对然后逐步修正模型参数,这就完成了整个dim模型对抠图的要求。这个东西先放在这以后肯定用的上。
接着看process函数里面的内容
im = cv.imread(fg_path + im_name)
a = cv.imread(a_path + im_name, 0)
h, w = im.shape[:2]
bg = cv.imread(bg_path + bg_name)这四句就是用opencv的读取函数,将对应的图片读取出来。im读取前景图片,a读取im的对应蒙版图片,bg读取背景图片。在读取前景蒙版的时候会以灰白图片形式读取,也就是单通道的读取。关于这句 h, w = im.shape[:2],是为了把im图片的宽和高都读取出来,这里面我们试验一下整个的效果。

同理,bh, bw = bg.shape[:2]也是得出来背景图片的宽和高。继续往下看。
wratio = w / bw
hratio = h / bh
ratio = wratio if wratio > hratio else hratio
if ratio > 1:
bg = cv.resize(src=bg, dsize=(math.ceil(bw * ratio), math.ceil(bh * ratio)), interpolation=cv.INTER_CUBIC)
return composite4(im, bg, a, w, h)返回值来说,im和bg是读取的前景和背景的数据,a是蒙版数据,w和h对应的是宽和高。但是前面几个语句里面肯定是对之前读取的那些有所处理,这里就要反推回去看看。直接看这句:
bg = cv.resize(src=bg, dsize=(math.ceil(bw * ratio), math.ceil(bh * ratio)), interpolation=cv.INTER_CUBIC)这里面就要搞懂对bg做什么处理。cv.resize是对bg进行尺寸的重塑,先把resize的几个参数都单独列出来一个一个研究
src : 原图
dsize - 目标图像大小。dsize(宽,高)
按照上面的dsize=(math.ceil(bw * ratio), math.ceil(bh * ratio))来比对的话,缩放后的宽为math.ceil(bw * ratio),高为math.ceil(bh * ratio)。那么到这里面就要看看代码前面ratio这个变量。
wratio = w / bw
hratio = h / bh
ratio = wratio if wratio > hratio else hratio
w和h是前景的宽度和高度,bw和bh是背景的宽度和高度,那么wratio和hratio就是计算前景和背景在宽度和高度上面的比值,谁的比值更大那么就把这个比值赋给ratio。之后一旦ratio大于1就执行修改尺寸的代码。math.ceil是向上取整。
interpolation - 插值方法。这里用的是INTER_CUBIC - 基于4x4像素邻域的3次插值法,能够保证图像变化后的清晰度。
现在就随便用两张前景和背景的照片试验一下

再把上面的wratio和hratio以及ratio运行一下以及最后把图片处理的代码运行一下,看看处理完成的结果。

对比一下处理前后的bg图像,宽640高480。

下面的是处理之后的,宽820高615

图片经过这样的变换到底有什么意义?这时候把前景图请出来比对一下,宽410高615。

这里面就发现背景图片经过变换之后把高度变成了前景图片的高度。那么再回到原来的算式推导一下。

到了这里就知道bg处理的目的了,那么最后一句composite4又涉及到了一个函数。
def composite4(fg, bg, a, w, h):
fg = np.array(fg, np.float32)
bg_h, bg_w = bg.shape[:2]
x = 0
if bg_w > w:
x = np.random.randint(0, bg_w - w)
y = 0
if bg_h > h:
y = np.random.randint(0, bg_h - h)
bg = np.array(bg[y:y + h, x:x + w], np.float32)
alpha = np.zeros((h, w, 1), np.float32)
alpha[:, :, 0] = a / 255.
im = alpha * fg + (1 - alpha) * bg
im = im.astype(np.uint8)
return im, a, fg, bg实际在前面的对于这个函数的使用是这样传参数的:composite4(im, bg, a, w, h)所以这里要把参数都对应上。
fg = im 前景图片数据
bg = bg 背景图片数据
a = a 蒙版图片数据
w = w 前景图片的宽
h = h 前景图片的高这里面就有个疑问:bg_h, bg_w = bg.shape[:2] 这句的目的是得到背景图的高和宽,那么在前面的代码bh和bw都是宽和高,为什么不直接传入?因为bg经过了为了适配im的尺寸变形,而前面得到的bh和bw都是原来的bg的尺寸,所以直接把bg传入得到高和宽更为适合。
再看这些代码:
x = 0
if bg_w > w:
x = np.random.randint(0, bg_w - w)
y = 0
if bg_h > h:
y = np.random.randint(0, bg_h - h)
bg = np.array(bg[y:y + h, x:x + w], np.float32)如果变换后的背景宽度bg_w比前景w更宽,x就会赋予一个值:np.random.randint(0, bg_w - w)。
np.random.randint(low, high=None, size=None, dtype='l')是为了产生离散均匀分布的整数
low:生成元素的最小值,high:生成元素的值一定小于high值,high不为None,生成元素的值在[low,high)区间中;如果high=None,生成的区间为[0,low)区间
size:输出的大小,可以是整数也可以是元组
dtype:生成元素的数据类型那么回到 x=np.random.randint(0, bg_w - w),就是为了生成在0到bg_w-w之间的离散均匀分布的整数,y就是从0到bg_h-h的离散均匀分布的整数。这里面不管是x还是y生成的都是一个随机的整数,并不是一系列的整数。最后bg = np.array(bg[y:y + h, x:x + w], np.float32),这句看得出来是把bg进行数组化,bg[y:y + h, x:x + w] 是把bg这个二维数组切片,从y到y+h-1行以及x到x+w-1列这些数据切出来,那么最后bg就是被切出来了这一块的数据并且赋予了float32的类型。(经过试验,变成floa32据说会方便计算,但是显示出来图片就会长残)由于x和y都是随机出来的数字,所以每一次运行处理出来的bg图片都不一定相同。

但是最后在确定处理完毕的图片的尺寸的时候发现了一个关键的问题:有一个参数没变,另外的一个参数就会随机乱蹦。这里面就把这个图片对于代码的试验结果拿出来看看。

奥秘就在这两句判断。
x = 0
if bg_w > w:
x = np.random.randint(0, bg_w - w)
y = 0
if bg_h > h:
y = np.random.randint(0, bg_h - h)当背景图的宽度更高的时候,x才会赋值,当背景图宽度更宽的时候,y才会赋值。在这一对图像里面,
![]()
经过处理后的背景图尺寸:
![]()
宽度更宽,高度与前景图对齐。那么在上面的判断里面,宽度背景图更宽,x被随机从0到背景宽度-前景宽度的差值之间赋予了一个整数,背景图和前景图的高度对齐,y就不会被赋值。这里面还有个神奇的事情,那就是在整个bg进行了处理之后尺寸和前景竟然一致了。奥秘在这句:
bg = np.array(bg[y:y + h, x:x + w], np.float32)虽然x和y都属于随机值,但是w和h是固定值。在刚才的例子里面,bg的切片数值是这样子:
bg[y=0,y+h=610,x=332,x+w = 742]那么切片出来之后的bg尺寸就是:
[y+h-y = h , x+w-x = w]
也就是说最后切出来的bg尺寸是和前景的尺寸完全对应上的,随机值的目的就是保证切片出来的数据完全随机,保证尺寸的同时保证了切片数据的随机性。
alpha = np.zeros((h, w, 1), np.float32)
alpha[:, :, 0] = a / 255.
im = alpha * fg + (1 - alpha) * bg
im = im.astype(np.uint8)继续看这里,alpha在经历了初始化全为0并且宽度和高度都和前景一样的np.float处理后,将蒙版值a/255赋予了alpha值,这样子就在不改变图像的特征之下保证像素在0到1之间的一致性,也方便后续的计算比对。 关于这两句,
im = alpha * fg + (1 - alpha) * bg
im = im.astype(np.uint8)
就是把前景和背景合成为一张图片的代码,最后再把合成的图片类型变回uint8,这里面最后我们就把最开始做实验的图片进行如上的几步处理得到的最后的造型如下:

到这里就有必要再回顾一下composite4函数的作用了。
def composite4(fg, bg, a, w, h):
"""
输入:
fg:前景数据
bg: 背景数据
a: 蒙版数据
w: 前景图片的宽
h: 前景图片的高
"""
fg = np.array(fg, np.float32)
bg_h, bg_w = bg.shape[:2]
x = 0
if bg_w > w:
x = np.random.randint(0, bg_w - w)
y = 0
if bg_h > h:
y = np.random.randint(0, bg_h - h)
bg = np.array(bg[y:y + h, x:x + w], np.float32)
alpha = np.zeros((h, w, 1), np.float32)
alpha[:, :, 0] = a / 255.
im = alpha * fg + (1 - alpha) * bg
im = im.astype(np.uint8)
return im, a, fg, bg
"""
输出:
im:重新合成的前景和背景图片
a: 蒙版值
fg:重新处理过的前景图片,数据类型变更为np.float32
bg:重新处理过的背景图片, 尺寸变更为前景的尺寸,并且数值选取随机,类型变更为float32
"""那么返回到process函数,process函数最后返回的结果也是composite4函数的返回结果。输入值比较简单就是前景和背景的图片文件名。
def process(im_name, bg_name):
im = cv.imread(fg_path + im_name)
a = cv.imread(a_path + im_name, 0)
h, w = im.shape[:2]
bg = cv.imread(bg_path + bg_name)
bh, bw = bg.shape[:2]
wratio = w / bw
hratio = h / bh
ratio = wratio if wratio > hratio else hratio
if ratio > 1:
bg = cv.resize(src=bg, dsize=(math.ceil(bw * ratio), math.ceil(bh * ratio)), interpolation=cv.INTER_CUBIC)
return composite4(im, bg, a, w, h)从这里搞明白了process函数之后回到前面的函数,这么一堆的东西只是为了完成一个语句:
img, alpha, fg, bg = process(im_name, bg_name),将前景和背景的名字输入之后得到了四样东西:
img:合成的前景和背景图
alpha:前景蒙版图
fg:处理过后的前景图片
bg:处理过后的背景图片
def __getitem__(self, i):
name = self.names[i]
fcount = int(name.split('.')[0].split('_')[0])
bcount = int(name.split('.')[0].split('_')[1])
im_name = fg_files[fcount]
bg_name = bg_files[bcount]
img, alpha, fg, bg = process(im_name, bg_name)
# crop size 320:640:480 = 1:1:1
different_sizes = [(320, 320), (480, 480), (640, 640)]
crop_size = random.choice(different_sizes)
trimap = gen_trimap(alpha)
x, y = random_choice(trimap, crop_size)
img = safe_crop(img, x, y, crop_size)
alpha = safe_crop(alpha, x, y, crop_size)
trimap = gen_trimap(alpha)
# Flip array left to right randomly (prob=1:1)
if np.random.random_sample() > 0.5:
img = np.fliplr(img)
trimap = np.fliplr(trimap)
alpha = np.fliplr(alpha)
x = torch.zeros((4, im_size, im_size), dtype=torch.float)
img = img[..., ::-1] # RGB
img = transforms.ToPILImage()(img)#将数据转化成PIL Image类型
img = self.transformer(img)
x[0:3, :, :] = img
x[3, :, :] = torch.from_numpy(trimap.copy() / 255.)
y = np.empty((2, im_size, im_size), dtype=np.float32)
y[0, :, :] = alpha / 255.
mask = np.equal(trimap, 128).astype(np.float32)
y[1, :, :] = mask
return x, y















 1658
1658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









