







吴恩达序列模型第二周主要讲了word embedding 和情感分类,把作业整理一下以加深印象。
作业csdn很多人上传,不过有些没有data文件很烦,我自己也上传了一版
word Embedding
1.对词向量进行操作
作业目标:
- Load pre-trained word vectors, and measure similarity using cosine similarity
- Use word embeddings to solve word analogy problems such as Man is to Woman as King is to __.
- Modify word embeddings to reduce their gender bias
导入所需工具包,加载已经训练好的词向量模型,这些词向量由glove模型训练,用50维的向量来表示每一个词:
import numpy as np
from w2v_utils import *
def read_glove_vecs(glove_file):
fo = open(glove_file, 'r',encoding='gb18030',errors='ignore')
words = set()
word_to_vec_map = {}
for line in fo.readlines():
line = line.strip().split(" ")
curr_word = line[0]
words.add(curr_word)
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64)
return words, word_to_vec_map
words, word_to_vec_map = read_glove_vecs('data/glove.6B.50d.txt')这里加载的函数我重新自己定义了,因为工具包里的函数有些问题,应该是split函数和我的环境不太相同。
这一步是为了得到:
- words:所有词的一个集合
- word_to_vec_map:词语和词向量的对应,即词典
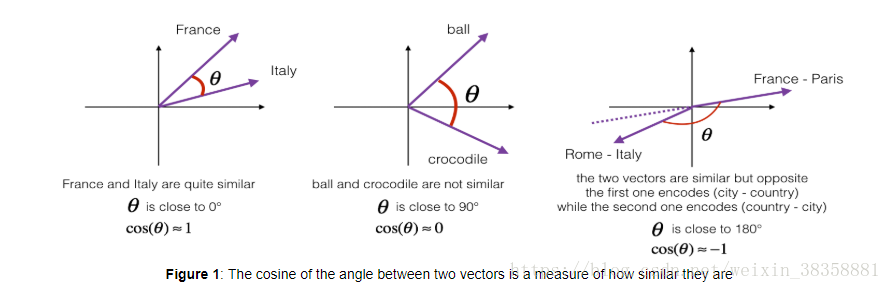
1.1 余弦相似度 Cosine similarity
作业中用余弦相似度来衡量两个word之间的相似度。
θ θ 表示的是两向量之间的夹角,
也就是说: cos(theta) c o s ( t h e t a ) 越接近1,越呈正相关,越接近0,越无关,越接近-1,越负相关。
如下图:
计算余弦相似度函数:
# GRADED FUNCTION: cosine_similarity
def cosine_similarity(u, v):
"""
Cosine similarity reflects the degree of similariy between u and v
Arguments:
u -- a word vector of shape (n,)
v -- a word vector of shape (n,)
Returns:
cosine_similarity -- the cosine similarity between u and v defined by the formula above.
"""
distance = 0.0
### START CODE HERE ###
# Compute the dot product between u and v (≈1 line)
dot = np.dot(u.T,v)
# Compute the L2 norm of u (≈1 line)
#ord = n 表示几范数(n=1,2,3)
norm_u = np.linalg.norm(u,ord=2)
# Compute the L2 norm of v (≈1 line)
norm_v = np.linalg.norm(v,ord=2)
# Compute the cosine similarity defined by formula (1) (≈1 line)
cosine_similarity = dot/(norm_u * norm_v)
### END CODE HERE ###
return cosine_similarity测试几个单词的相似度来检验算法的正确性:
father = word_to_vec_map["father"]
mother = word_to_vec_map["mother"]
ball = word_to_vec_map["ball"]
crocodile = word_to_vec_map["crocodile"]
france = word_to_vec_map["france"]
italy = word_to_vec_map["italy"]
paris = word_to_vec_map["paris"]
rome = word_to_vec_map["rome"]
print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile))
print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy))结果:
cosine_similarity(father, mother) = 0.8909038442893615
cosine_similarity(ball, crocodile) = 0.2743924626137942
cosine_similarity(france - paris, rome - italy) = -0.6751479308174202
1.2 词语类比任务
在这个任务中, 我们计算句子 “a is to b as c is to __”。 举例来说 ‘man 对于 woman 和 king 对于 queen‘相似 。具体来说, 我们试图找到一个单词 d, 使词向量 ea,eb,ec,ed e a , e b , e c , e d 用以下方式联系起来: eb−ea≈ed−ec e b − e a ≈ e d − e c 。我们将用余弦相似度来测量 eb−ea e b − e a 和 ed−ec e d − e c 相似性。
# GRADED FUNCTION: complete_analogy
def complete_analogy(word_a, word_b, word_c, word_to_vec_map):
"""
Performs the word analogy task as explained above: a is to b as c is to ____.
Arguments:
word_a -- a word, string
word_b -- a word, string
word_c -- a word, string
word_to_vec_map -- dictionary that maps words to their corresponding vectors.
Returns:
best_word -- the word such that v_b - v_a is close to v_best_word - v_c, as measured by cosine similarity
"""
# convert words to lower case
word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower()
### START CODE HERE ###
# Get the word embeddings v_a, v_b and v_c (≈1-3 lines)
e_a = word_to_vec_map(word_a)
e_b = word_to_vec_map(word_b)
e_c = word_to_vec_map(word_c)
#所需要的词向量,由上面的公式得出
e_tran = e_a - e_b + e_c
### END CODE HERE ###
words = word_to_vec_map.keys()
max_cosine_sim = -100 # Initialize max_cosine_sim to a large negative number
best_word = None # Initialize best_word with None, it will help keep track of the word to output
# loop over the whole word vector set
for w in words:
# to avoid best_word being one of the input words, pass on them.
if w in [word_a, word_b, word_c] :
continue
if word_to_vec_map(w).shape[0] != 50:
continue
### START CODE HERE ###
# Compute cosine similarity between the combined_vector and the current word (≈1 line)
cosine_sim = cosine_similarity(word_to_vec_map(w),e_tran)
# If the cosine_sim is more than the max_cosine_sim seen so far,
# then: set the new max_cosine_sim to the current cosine_sim and the best_word to the current word (≈3 lines)
if cosine_sim > max_cosine_sim:
max_cosine_sim = cosine_sim
best_word = w
### END CODE HERE ###
return best_word
执行发现,有一个词的向量长度为10,就添加了个判断shape的语句,来保证向量的可用性:
if word_to_vec_map(w).shape[0] != 50:
continue测试:
triads_to_try = [('italy', 'italian', 'spain'), ('india', 'delhi', 'japan'), ('man', 'woman', 'boy'), ('small', 'smaller', 'large')]
for triad in triads_to_try:
print ('{} -> {} :: {} -> {}'.format( *triad, complete_analogy(*triad,word_to_vec_map)))结果:
italy -> italian :: spain -> portugal
india -> delhi :: japan -> china
man -> woman :: boy -> kid
small -> smaller :: large -> filled我擦嘞
印度–德里
日本-中国?????
妈个鸡哟,中国咋成日本的emmm我怕不是要被+1s
冷静思考一下,应该是combined_vecto计算r有问题
看眼公式
e_tran = e_a - e_b + e_c
应该是:e_b-e_a+e_c
再试一次,成了italy -> italian :: spain -> spanish
india -> delhi :: japan -> tokyo
man -> woman :: boy -> girl
small -> smaller :: large -> larger
(话说python指针原来可以这样用,在下才疏学浅还差得远啊哈哈哈哈哈)
小结
余弦相似性是比较词向量对之间相似性的一种好方法。(虽然L2距离也适用。)
对于NLP应用,使用预先训练的来自互联网的单词向量集通常是一个很好的开始方法。
1.3 去偏词向量(选做)
这个练习是尝试去消除字向量中对性别的偏见。视频中提到:man->doctor woman->nurse
triad = ('man', 'doctor', 'woman')
man -> doctor :: woman -> nurse尝试其他:
triad = ('man', 'doctor', 'woman')
men -> doctor :: women -> patient我擦嘞,偏见更严重了
再试一个
triad = ('man', 'doctor', 'women')
man -> doctor :: women -> physicians偏见消除了,奇怪,感觉这点可以深入探讨下。
回归主题,安排
消除偏见步骤如下:
1.3.1 两向量相减
对应上面就是 e.man - e.woman
g = word_to_vec_map['woman'] - word_to_vec_map['man']
print(g)然后我们要考虑不同的词和g的余弦相似性,来判断每个词和g的相关性,反正就是什么手枪和物理干他娘啊啥玩意儿的和男性更相关,柔情似水,温柔体贴讨厌了啦这种和女性更相关,然后吴恩达说这不对啊,这是偏见,然后用了这篇文章的算法来消除这种偏见。Boliukbasi et al., 2016
这篇文章我也没看,有空看看讨论哈,反正大致意思就是有些词可以保持性别的特异性,比如“奶奶”,“爸爸”这种,有些不应该保持特异性,比如“物理学”,“博士”这种。
具体做法如下:
Neutralize bias for non-gender specific words 如何使非性别特异词中性化
卧槽这个好像有点那么难。
算了,硬着头皮看,快乐就完事了。
我们现在是将一个word又50维的向量表示。文章说这个向量可以分为两个部分,一个基础的向量g和剩余的49个向量,大概意思如下图左边的图所示。然后对向量e进行中和化操作。
咋中和化呢?
大致思想就是由向量e和向量g进行计算
ebias_component
e
b
i
a
s
_
c
o
m
p
o
n
e
n
t
,表示e向量相对于g向量所存在的偏差,然后再用原始的e向量减去偏差向量
ebias_component
e
b
i
a
s
_
c
o
m
p
o
n
e
n
t
,就得到了不存在偏差的向量
edisbiased
e
d
i
s
b
i
a
s
e
d
。感觉真鸡儿简单,具体公式如下:
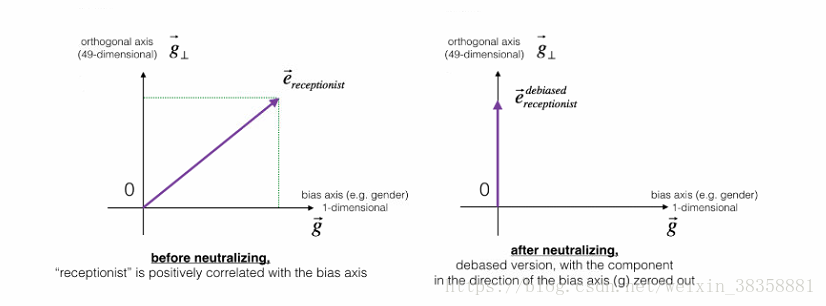
至于这个公式怎么来的,论文里应该有推导过程,感兴趣的童鞋去找找看好了
中和操作函数定义如下:
def neutralize(word, g, word_to_vec_map):
"""
Removes the bias of "word" by projecting it on the space orthogonal to the bias axis.
This function ensures that gender neutral words are zero in the gender subspace.
Arguments:
word -- string indicating the word to debias
g -- numpy-array of shape (50,), corresponding to the bias axis (such as gender)
word_to_vec_map -- dictionary mapping words to their corresponding vectors.
Returns:
e_debiased -- neutralized word vector representation of the input "word"
"""
### START CODE HERE ###
# Select word vector representation of "word". Use word_to_vec_map. (≈ 1 line)
e = word_to_vec_map[word]
# Compute e_biascomponent using the formula give above. (≈ 1 line)
e_biascomponent = np.dot(np.dot(e,g)/(np.square(np.linalg.norm(g))),g)
# Neutralize e by substracting e_biascomponent from it
# e_debiased should be equal to its orthogonal projection. (≈ 1 line)
e_debiased = e - e_biascomponent
### END CODE HERE ###
测试一下:
e = "receptionist"
print("cosine similarity between " + e + " and g, before neutralizing: ", cosine_similarity(word_to_vec_map["receptionist"], g))
e_debiased = neutralize("receptionist", g, word_to_vec_map)
print("cosine similarity between " + e + " and g, after neutralizing: ", cosine_similarity(e_debiased, g))
实际输出:
cosine similarity between receptionist and g, before neutralizing: 0.3307794175059374
cosine similarity between receptionist and g, after neutralizing: -2.099120994400013e-17
理想输出:
cosine similarity between receptionist and g, before neutralizing: : 0.330779417506
cosine similarity between receptionist and g, after neutralizing: : -3.26732746085e-17略有区别,不过在一个量级应该没有差别。
因为g表示性别这一概念,也就是说,本来和性别(男或女)相关的词汇,现在不再如此的相关了。
3.2 性别特异性词汇的均衡性算法
接下来我们来试试将中和算法应用到单词对上,比如“actor”,“actress”。假设一个词“babysit(保姆)”本来更接近于女演员。通过对“babysit”进行中和,我们可以减少保姆这词对性别的相关性。但是,这仍然不能保证“actor”和“actress”向量与“babysit”是等距的。那么均衡操作就是保证“actor”,“actress“这对词与“gender”向量中的另49维向量的距离相同,有点绕,就如下图:

公式的具体推导贼鸡儿复杂,就在那25页的论文里,下面几个公式算是核心思想吧:
均衡操作代码如下:
def equalize(pair, bias_axis, word_to_vec_map):
"""
Debias gender specific words by following the equalize method described in the figure above.
Arguments:
pair -- pair of strings of gender specific words to debias, e.g. ("actress", "actor")
bias_axis -- numpy-array of shape (50,), vector corresponding to the bias axis, e.g. gender
word_to_vec_map -- dictionary mapping words to their corresponding vectors
Returns
e_1 -- word vector corresponding to the first word
e_2 -- word vector corresponding to the second word
"""
### START CODE HERE ###
# Step 1: Select word vector representation of "word". Use word_to_vec_map. (≈ 2 lines)
w1, w2 = pair[0],pair[1]
e_w1, e_w2 = word_to_vec_map[w1],word_to_vec_map[w2]
# Step 2: Compute the mean of e_w1 and e_w2 (≈ 1 line)
mu = (e_w1+e_w2)/2
# Step 3: Compute the projections of mu over the bias axis and the orthogonal axis (≈ 2 lines)
mu_B = (np.dot(mu,bias_axis)/np.linalg.norm(bias_axis)) + (np.linalg.norm(bias_axis) * bias_axis)
mu_orth = mu - mu_B
# Step 4: Set e1_orth and e2_orth to be equal to mu_orth (≈2 lines)
e1_orth = mu_orth
e2_orth = mu_orth
# Step 5: Adjust the Bias part of u1 and u2 using the formulas given in the figure above (≈2 lines)
e_w1B = (np.sqrt(np.fabs(1 - np.square(np.linalg.norm(mu_orth,ord=2))))) * (((e_w1 - mu_orth) - mu_B) / np.fabs((e_w1 - mu_orth) - mu_B))
e_w2B = (np.sqrt(np.fabs(1 - np.square(np.linalg.norm(mu_orth,ord=2))))) * (((e_w2 - mu_orth) - mu_B) / np.fabs((e_w2 - mu_orth) - mu_B))
# Step 6: Debias by equalizing u1 and u2 to the sum of their projections (≈2 lines)
e1 = e_w1B + mu_orth
e2 = e_w2B + mu_orth
### END CODE HERE ###
return e1, e2结果:
cosine similarities before equalizing:
cosine_similarity(word_to_vec_map["man"], gender) = -0.11711095765336832
cosine_similarity(word_to_vec_map["woman"], gender) = 0.35666618846270376
cosine similarities after equalizing:
cosine_similarity(e1, gender) = -0.7738228268094309
cosine_similarity(e2, gender) = 0.679156160467685是比之前的差异小了,但是并不是理想啊,不知道哪儿错了,挠头
理想的为:
cosine_similarity(u1, gender) = -0.700436428931
cosine_similarity(u2, gender) = 0.700436428931
这咋整啊
反正,确实减少了男孩女孩和性别向量距离差异过大的情况,至于为啥没完全相等,容我看看原论文,因为我发现,给出的公式和作业,并没有用到e1_orth ,e2_orth 这两个变量,好像有些奇怪。
先就这样~~~
撒花欧耶!
















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









