






基于信息增益的决策树算法(附MATLAB代码)
最近在学机器学习,本篇文章的内容正好是作业内容,所以拿来分享一下,顺便捋一下思路。下面内容只涉及到决策树学习基本算法(伪代码)、信息增益的计算和matlab代码实现。决策树算法原理不再赘述,请自行百度。水平有限,如有错误,欢迎指正!
一、决策树学习基本算法

二、 信息增益的计算
1.信息熵
“信息熵”(information entropy)是度量样本集合纯度最常用的一种指标,假定当前样本集合D中第k类样本所占的比例为Pk(k = 1,2,…,|Y|),则D的信息熵定义为
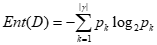
Ent(D)的值越小,D的纯度越高。
2.信息增益
假定离散属性a有V个可能的值a1,a2,…,aV,若使用a来对样本集D进行划分,则会产生V个分支节点,其中第v个分支节点包含了D中所有在属性a上取值为av的样本,记为Dv,这时可以计算出Dv的信息熵,同时考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重|Dv|/|D|,即样本数越多的分支结点的影响越大,于是可计算出用属性a对样本集D进行划分所获得的“信息增益”(information gain)
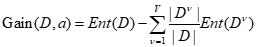
3.划分属性选择
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”就越大,因此,我们可用信息增益来进行决策树的划分选择,即选择属性a = arg* max Gain(D,a),这就是著名的ID3决策树学习算法。
三、MATLAB代码实现
%****************************************
%main.m
%****************************************
clear,clc
[~,data] = xlsread('data.xlsx',3) %读入数据集
[~,feature] = xlsread('feature.xlsx') %读入属性集
Node = createTree(data, feature); %生成决策树
drawTree(Node) %绘制决策树
%****************************************
%createTree.m
%****************************************
%生成决策树ID3算法
%data:训练集
%feature:属性集
function [node] = createTree(data, feature)
type = mostType(data); %cell类型
[m, n] = size(data);
%生成节点node
%value:分类结果,若为null则表示该节点是分支节点
%name:节点划分属性
%branch:节点属性值
%children:子节点
node = struct('value','null','name','null','branch','null','children',{});
temp_type = data{1, n};
temp_b = true;
for i = 1 : m
if temp_type ~= data{i, n}
temp_b = false;
end
end
%样本中全为同一分类结果,则node节点为叶节点
if temp_b == true
node(1).value = data(1, n); %cell类型
return;
end
%属性集合为空,将结果标记为样本中最多的分类
if isempty(feature) == 1
node.value = type; %cell类型
return;
end
%获取最优划分属性
feature_bestColumn = bestFeature(data); %最优属性列数,double类型
best_feature = data(:,feature_bestColumn); %最优属性列,cell类型
best_distinct = unique(best_feature); %最优属性取值
best_num = length(best_distinct); %最优属性取值个数
best_proc = cell(best_num, 2);
best_proc(:, 1) = best_distinct(:, 1);
best_proc(:, 2) = num2cell(zeros(best_num, 1));
%循环该属性的每一个值
for i = 1:best_num
%为node创建一个bach_node分支,设样本data中该属性值为best_proc(i, 1)的集合为Dv
bach_node = struct('value', 'null', 'name', 'null', 'branch', 'null', 'children',{});
Dv_index = 0;
for j = 1:m
if data{j, feature_bestColumn} == best_proc{i, 1}
Dv_index = Dv_index + 1;
end
end
Dv = cell(Dv_index, n);
Dv_index2 = 1;
for j = 1:m
if best_proc{i, 1} == data{j, feature_bestColumn}
Dv(Dv_index2, :) = data(j, :);
Dv_index2 = Dv_index2 + 1;
end
end
Dfeature = feature;
%Dv为空则将结果标记为样本中最多的分类
if isempty(Dv) == 1
bach_node.value = type;
bach_node.name = feature(feature_bestColumn);
bach_node.branch = best_proc(i, 1);
node.children(i) = bach_node;
return;
else
Dfeature(feature_bestColumn) = [];
Dv(:,feature_bestColumn) = [];
%递归调用createTree方法
bach_node = createTree(Dv, Dfeature);
bach_node(1).branch = best_proc(i, 1);
bach_node(1).name = feature(feature_bestColumn);
node(1).children(i) = bach_node;
end
end
end
%****************************************
%mostType.m
%****************************************
%计算样本最多的结果
function [res] = mostType(data) %返回值cell类型
[m,n] = size(data);
res = data(:, n);
res_distinct = unique(res);
res_num = length(res_distinct);
res_proc = cell(res_num,2);
res_proc(:, 1) = res_distinct(:, 1);
res_proc(:, 2) = num2cell(zeros(res_num,1));
for i = 1:res_num
for j = 1:m
if res_proc{i, 1} == data{j, n};
res_proc{i, 2} = res_proc{i, 2} + 1;
end
end
end
end
%****************************************
%getEntropy.m
%****************************************
%计算信息熵
function [entropy] = getEntropy(data) %返回值double类型
entropy = 0;
[m,n] = size(data);
label = data(:, n);
label_distinct = unique(label);
label_num = length(label_distinct);
proc = cell(label_num,2);
proc(:, 1) = label_distinct(:, 1);
proc(:, 2) = num2cell(zeros(label_num, 1));
for i = 1:label_num
for j = 1:m
if proc{i, 1} == data{j, n}
proc{i, 2} = proc{i, 2} + 1;
end
end
proc{i, 2} = proc{i, 2} / m;
end
for i = 1:label_num
entropy = entropy - proc{i, 2} * log2(proc{i, 2});
end
end
%****************************************
%getGain.m
%****************************************
%计算信息增益
function [gain] = getGain(entropy, data, column) %返回值double类型
[m,n] = size(data);
feature = data(:, column);
feature_distinct = unique(feature);
feature_num = length(feature_distinct);
feature_proc = cell(feature_num, 2);
feature_proc(:, 1) = feature_distinct(:, 1);
feature_proc(:, 2) = num2cell(zeros(feature_num, 1));
f_entropy = 0;
for i = 1:feature_num
feature_row = 0;
for j = 1:m
if feature_proc{i, 1} == data{j, column}
feature_proc{i, 2} = feature_proc{i, 2} + 1;
feature_row = feature_row + 1;
end
end
feature_data = cell(feature_row,n);
feature_row = 1;
for j = 1:m
if feature_distinct{i, 1} == data{j, column}
feature_data(feature_row, :) = data(j, :);
feature_row = feature_row + 1;
end
end
f_entropy = f_entropy + feature_proc{i, 2} / m * getEntropy(feature_data);
end
gain = entropy - f_entropy;
end
%****************************************
%bestFeature.m
%****************************************
%获取最优划分属性
function [column] = bestFeature(data) %返回值double类型
[~,n] = size(data);
featureSize = n - 1;
gain_proc = cell(featureSize, 2);
entropy = getEntropy(data);
for i = 1:featureSize
gain_proc{i, 1} = i;
gain_proc{i, 2} = getGain(entropy, data, i);
end
max = gain_proc{1,2};
max_label = 1;
for i = 1:featureSize
if gain_proc{i, 2} >= max
max = gain_proc{i, 2};
max_label = i;
end
end
column = max_label;
end
%****************************************
%drawTree.m
%****************************************
% 画出决策树
function [] = drawTree(node)
% 遍历树
nodeVec = [];
nodeSpec = {};
edgeSpec = [];
[nodeVec,nodeSpec,edgeSpec,~] = travesing(node,0,0,nodeVec,nodeSpec,edgeSpec);
treeplot(nodeVec);
[x,y] = treelayout(nodeVec);
[~,n] = size(nodeVec);
x = x';
y = y';
text(x(:,1),y(:,1),nodeSpec,'FontSize',15,'FontWeight','bold','VerticalAlignment','bottom','HorizontalAlignment','center');
x_branch = [];
y_branch = [];
for i = 2:n
x_branch = [x_branch; (x(i,1)+x(nodeVec(i),1))/2];
y_branch = [y_branch; (y(i,1)+y(nodeVec(i),1))/2];
end
text(x_branch(:,1),y_branch(:,1),edgeSpec(1,:),'FontSize',12,'Color','blue','FontWeight','bold','VerticalAlignment','bottom','HorizontalAlignment','center');
end
% 遍历树
function [nodeVec,nodeSpec,edgeSpec,current_count] = travesing(node,current_count,last_node,nodeVec,nodeSpec,edgeSpec)
nodeVec = [nodeVec last_node];
if isempty(node.value)
nodeSpec = [nodeSpec node.children(1).name];
else
if strcmp(node.value, '是')
nodeSpec = [nodeSpec '好瓜'];
else
nodeSpec = [nodeSpec '坏瓜'];
end
end
edgeSpec = [edgeSpec node.branch];
current_count = current_count + 1;
current_node = current_count;
if ~isempty(node.value)
return;
end
for next_ndoe = node.children
[nodeVec,nodeSpec,edgeSpec,current_count] = travesing(next_ndoe,current_count,current_node,nodeVec,nodeSpec,edgeSpec);
end
end
代码链接:.m文件下载
四、运行结果
训练集:
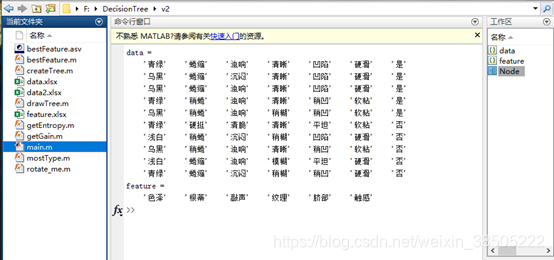
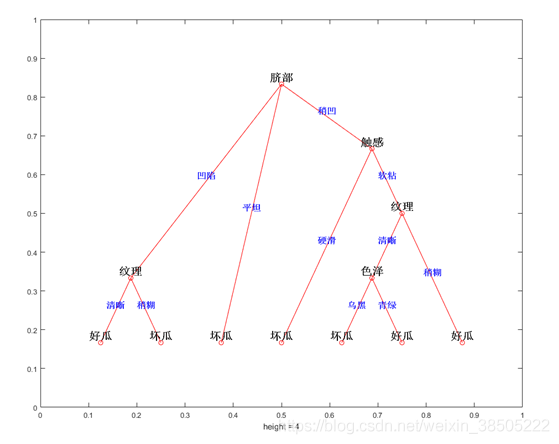
根据训练集生成决策树如下:
测试集及结果:
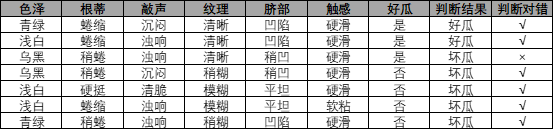
声明:本人并没有写测试部分的代码,感兴趣的可以自己写一下。
五、代码和数据集
链接:
https://pan.baidu.com/s/1nDWsmaMo_aJr0LCFEJCadA
提取码:7jrq















 2162
2162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









