







1. 卷积网络
import torch
from torch import nn
# 二维卷积
'''
[N,C,H,W] :批量数,通道数,高度,宽度
in_channels: int,输入图像的通道数
out_channels: int,输出图像的通道数
kernel_size: Union[int, Tuple[int, int]],卷积核
stride: Union[int, Tuple[int, int]] = 1,步长
padding: Union[str, int, Tuple[int, int]] = 0,补零
dilation: Union[int, Tuple[int, int]] = 1,膨胀卷积/空洞卷积
groups: int = 1,分组卷积
bias: bool = True,偏置
padding_mode: str = 'zeros',填充模式
device=None,设备
dtype=None,数据类型 默认:torch.float32
'''
conv1 = nn.Conv2d(in_channels=3, out_channels=16,kernel_size=3, stride=1,padding=1)
X = torch.randn(1,3,64,64)
print(conv1(X).shape) # : torch.Size([1, 16, 64, 64])
2. BatchNorm组件
- Batch:批量
- Norm:规范化
- x ˉ = ( x − μ ) / σ \bar x = (x - \mu) / \sigma xˉ=(x−μ)/σ
- BatchNorm 中的均值和标准差都是当前批的,所以一批样本的个数不能为1,否则计算均值和标准差就没有意义了。
- 按照常理来讲,推理的数据要和训练数据做一模一样的处理,BatchNorm 训练时使用的是当前批样本的均值和标准差进行计算,但是推理时样本数量为1,这要怎样来处理呢?
- 实际上,BatchNorm 内部做了如下处理:在训练时,默默记录每一批样本的均值和标准差,最终估算一个合适的值给推理使用。
- 我们不得不承认这是一个天才的想法,但是这个做法也给我们带来了麻烦,那就是它直接导致了训练和推理的行为不一致而层产生的两种模式:train模式 和 eval模式

# 每一层看作一个特征
bn = nn.BatchNorm2d(num_features=16)
print(bn.weight.shape,bn.bias.shape) # : torch.Size([16]) torch.Size([16])
3. ReLU层
def relu(x):
"""
修正线性激活单元
"""
x[x<0]=0
return x
X= torch.randn(2,6)
print(X)
print(relu(X)) # 自己写的ReLU
print(torch.relu(X)) # torch自带的ReLU
tensor([[-0.1721, -1.8191, -1.1624, 0.6398, 1.6384, -1.0803],
[-0.9440, -2.1701, -1.5298, -0.5117, -0.8510, -0.8240]])
tensor([[0.0000, 0.0000, 0.0000, 0.6398, 1.6384, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]])
tensor([[0.0000, 0.0000, 0.0000, 0.6398, 1.6384, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]])
4. 卷积三兄弟
- 卷积三兄弟:
- 卷积层
- 批规范化层
- 激活层
class ConvBlock(nn.Module):
"""
一层卷积:
- 卷积层
- 批规范化层
- 激活层
"""
def __init__(self,in_channels,out_channels,
kernel_size=3,stride=1,padding=1):
# 初始化子类之前要先初始化父类
super().__init__()
self.conv = nn.Conv2d(in_channels=in_channels,out_channels=out_channels,
kernel_size=kernel_size,stride=stride,padding=padding)
self.bn = nn.BatchNorm2d(num_features=out_channels)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
convblock1 = ConvBlock(in_channels=3, out_channels=16)
X = torch.randn(1,3,64,64)
convblock1(X).shape # torch.Size([1, 16, 64, 64])
5. 线性层
linear = nn.Linear(in_features=1024,out_features=16)
6. Dropout
- Dropout 就是让神经元随机失活,从而降低全连接神经网络过拟合的风险。
- 那么随机失活会导致全连接神经网络层发生质的改变吗?并不会,请看下面的公式:
y = f ( x ) = { 0 p 1 1 − p 1 − p y= f(x) = \left\{ \begin{array}{ll} 0 & \text p \\ \frac{1}{1-p} & \text 1-p \end{array} \right. y=f(x)={01−p1p1−p - p 是概率,通过计算 Dropout 的期望发现,期望与之前一致,所以本质上这个处理不会对结果产生很大影响。
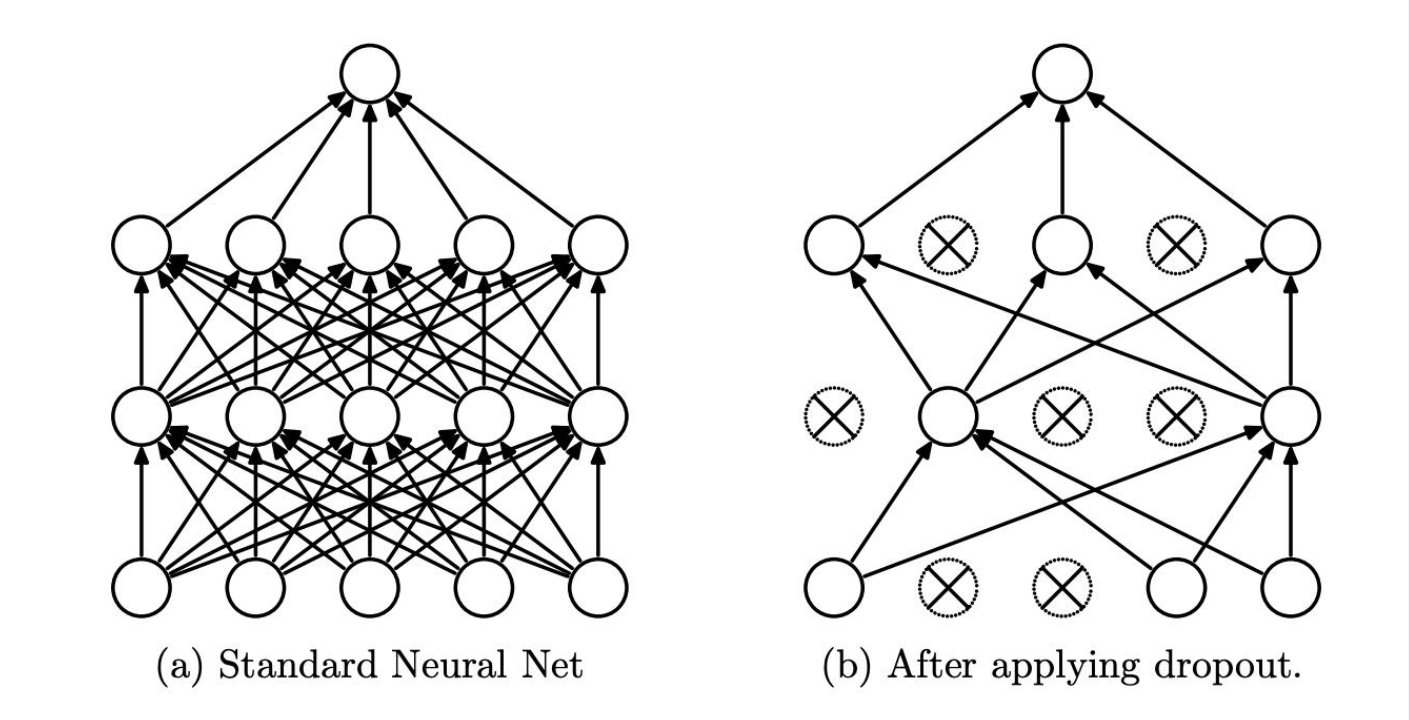
dp = nn.Dropout(p=0.5)
X = torch.randn(10)
print('原始数据:',X)
print('默认模式:',dp(X))
dp.eval()
print('eval模式:',dp(X))
dp.train()
print('train模式:',dp(X))
原始数据: tensor([-1.2073, 0.3764, 0.9974, -0.9199, 0.4409, 0.2878, 0.9389, -0.0928, 0.7844, 1.0739])
默认模式: tensor([-0.0000, 0.7528, 0.0000, -0.0000, 0.0000, 0.0000, 1.8777, -0.0000, 1.5689, 0.0000])
eval模式: tensor([-1.2073, 0.3764, 0.9974, -0.9199, 0.4409, 0.2878, 0.9389, -0.0928, 0.7844, 1.0739])
train模式: tensor([-2.4146, 0.7528, 0.0000, -1.8399, 0.8819, 0.5756, 0.0000, -0.0000, 0.0000, 0.0000])



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











