






一、view()与reshape()的比较
1.1 将weight的tensor维度进行一个拉伸
weight = weight.view(
batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
)
view方法用于维度的变换
view() 方法返回的张量与原始张量共享存储空间,而 reshape() 方法返回的张量不共享存储空间。
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
y = x.view(3, 2)
print("x:\n", x)
print("y:\n", y)
x:
tensor([[1, 2, 3],
[4, 5, 6]])
y:
tensor([[1, 2],
[3, 4],
[5, 6]])
x与y共享同一个地址,但是reshape的话不会与原始张量共享存储空间
1.2 插值法的两种方式
# 将特征图大小从(4, 4)变为(7, 7)
new_size = (7, 7)
//表示双线性插值法
up = F.interpolate(x, size=new_size, mode='bilinear', align_corners=False)
//表示使用最近邻插值方法,是使用PyTorch实现的上采样操作,其作用是将输入张量x的大小增加一倍。具体地,它将输入张量在每个维度上的大小都乘以scale_factor,并使用指定的插值方法来计算新像素的值。
up = F.interpolate(x, scale_factor=2, mode="nearest")
双线性插值的作用是将原始张量的值插值指定维度,在特征拼接时可能会用到。
二、view()方法的使用场景
如果该卷积层需要上采样,则将输入数据的形状从
(batch, in_channel, height, width) 转换为 (1, batch*in_channel, height, width)。
2.1 F.conv_transpose2d() 函数
input = input.view(1, batch * in_channel, height, width)
二维转置卷积操作可以用于**上采样或反卷积**等任务,它可以增加特征图的尺寸并还原被卷积操作所丢失的信息。在这个函数中,padding 参数用于指定边缘填充的大小,stride 参数用于指定卷积核的步幅大小,groups 参数用于指定输入张量的分组数。
2.2 transpose(1, 2)
*value_1 = value_list[ lid_]. flatten(2). transpose(1, 2). reshape(N_M_, D_, H_, W_)
transpose操作用于交换数组的维度。具体来说,transpose(1, 2)将数组的第二个维度和第三个维度进行交换。这样做的目的是为了在后续的reshape操作中,将原先的四维数组转换为二维数组,使得每个元素都能够被唯一地标识。
2.3 permute()函数
这段代码首先对 f_all 进行转置操作,将它的维度顺序变为 (b, out_planes, 3 * head, h * w),
# 然后通过 reshape 操作将它重塑为形状为 (b, out_planes * 3 * head, h, w) 的张量。
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
permute(0, 2, 1, 3)表示将2与3两个对调。
2.4 q_att.unsqueeze(2)
将查询张量 q_att 在第二个维度上扩展一维,//在指定维度上进行扩展
在代码中,有一些维度上的操作,这些操作是为了保证张量维度的匹配,如unsqueeze和repeat,以便进行元素级别的运算。
2.5 nn.ReflectionPad2d(),四个参数分别代表左右上下

2.6 x.clamp(eps).pow§
这一部分首先对输入张量 x 进行了一个 clamp 操作,即将张量中所有小于等于 eps 的元素设置为 eps。这样可以保证张量中所有的元素都大于 eps。接下来对 clamp 操作后的张量每个元素进行了一个 p 次方的操作。

作用:torch.nn.ReflectionPad2d 是 PyTorch 中的一个二维反射填充层,它可以在输入特征图的边缘进行反射填充,以避免在进行卷积或池化等操作时损失边缘信息。
2.5关于函数的调用
1.self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)//首先在定义方法时,类中传入的是初始化方法所要传入的参数,当要使用的时候,也就是out = self.blur(out)//这里所要传入的参数也就是forward当中的参数。
2.from models.stylegan2.op import FusedLeakyReLU, fused_leaky_relu, upfirdn2d//这里是将op文件夹下的三个.py文件全部导入,因此便可以直接使用这个三个模块中的所有方法了。
三、张量维度的理解
[[[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]],
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]//里面两个括号表示特征图,第三个括号表示在channel维度上。第四个表示在batch维度上***(批次大小的选择需要根据具体的任务和硬件资源来进行选择和调整。通常情况下,我们会根据GPU的内存大小、数据集的大小以及模型的复杂度等因素来选择合适的批次大小)***。
第一维:batch_size 表示输入的样本数量,也就是在一个batch中有多少个样本;
第3,4维度:特征图的高度和宽度分别对应于特征图在垂直和水平方向上的大小,
第二维:通道数对应于特征图的深度。
其实质就是多个二维特征图的堆叠。堆叠的特征图的个数就是channel数,第一维度与2,3,4维度没有直接的关系。
样本数与特征图没有直接的对应关系,它们是不同的概念。在卷积神经网络中,输入的样本数量只影响网络的batch_size,而特征图的大小和深度则由网络的结构和参数决定。
个人认为四维可以理解为多个三维立方体的堆叠,每一个立方体对应一个样本
3.1列表是如何取值的
列表取值的语法是list[start:stop:step](重点),其中start表示起始位置,stop表示终止位置,step表示步长。
**当使用list[1::2]时,表示从列表的第二个元素(即下标为1的元素)开始,每隔一个元素取一个值,直到列表的最后一个元素。**
**而使用list[1:2]时,则表示从列表的第二个元素开始,取到第三个元素(即下标为2的元素)为止。**
需要注意的是,使用list[1:2]时取到的是一个切片,包含了列表中下标为1的元素,但不包含下标为2的元素。而使用list[1::2]时取到的是一个新列表,其中包含了原列表中下标为1、3、5、7等奇数下标位置上的元素。因此,在使用列表取值时,需要根据具体需求来选择合适的语法。
四、卷积相关操作
4.1 在卷积中加上残差模块
convs.append(ResBlock(in_channel, out_channel, blur_kernel))
4.2 张量展开成序列
(b * head, in_planes, h_out * kernel_att, w_out * kernel_att) 的张量 pad_att,展开操作后得到的张量 unfold_pad_att 的形状是 (b * head, in_planes * kernel_att * kernel_att, h_out * w_out),其中第一个维度表示了序列中的元素个数,第二个维度表示了每个元素的大小,第三个维度表示了序列的长度。
4.3 张量计算数据预处理
涉及到reshape,unsqueeze()的相关操作。unsqueeze()里面的参数分别表示在行列高三个维度上进行的扩充。(squeeze表示压缩的意思)
特征向量 out_att ==pad_att----填充–>new pad_att–展开–> (b * head, in_planes * kernel_att * kernel_att, h_out * w_out)
[self.unfold 函数对填充后的张量 pad_att 进行展开操作] --reshape–> (b * head, in_planes, kernel_att * kernel_att, h_out, w_out) [表示了每个位置的特征向量]
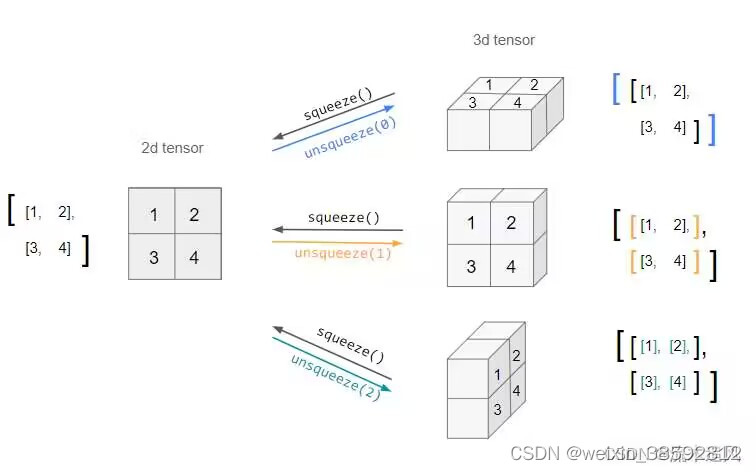
上面这张图展示unsqueeze的变化过程。
注意力权重 att ==(b * head, 1, h * w) [att.unsqueeze(1),表示计算出的注意力权重 att ][表示了每个位置的注意力权重]
3维---->5维----->
att * out_att = (b * head, in_planes, kernel_att * kernel_att, h_out, w_out) —对第三个维度求和–>(b * head, self.out_planes, h_out, w_out) —reshape–>(b, self.out_planes, h_out, w_out) [表示整个图像的特征向量]
5----->4------>4
进行数据变换的目的就是让张量能够更好的进行计算。
4.4 3 * 3 与1*1卷积的对比
1x1 的卷积因为它可以实现通道的线性变换,而不改变特征图的空间尺寸。这种卷积操作常用于深度残差网络中的跨通道信息交互,可以有效地降低计算量和模型参数数量,同时提高模型的表达能力。
相反,3x3 的卷积会在空间维度上进行滑动窗口卷积操作,并且会改变特征图的空间尺寸。因此,如果使用 3x3 的卷积,就会改变特征图的空间尺寸,
4.4 当stride为1,kernel_size=3,对于tensor(16,512,5)的张量卷积之后能得到(16,512,3)大小的张量。
五、注意力机制
5.1 q,k,v关系
q用来进行查询信息,v表示信息
键向量
k
k
k在多头注意力机制中扮演了提供信息的角色(它是一个向量,表示输入序列中某个位置的特征。具体来说,键向量
k
k
k 是通过对输入序列中某个位置的特征进行线性变换得到的。)。
它通过线性变换将输入序列中某个位置的特征映射到一个新的表示空间中,
与查询向量 q 进行相似度计算,从而得到注意力权重(也就是哪些地方重要哪些不重要)。
注意力权重可以用于对输入序列中每个位置进行加权表示,之后与V(值)进行计算从而实现对输入序列的编码和解码。
5.2 多头自注意力机制
1.多个查询、键、值的组合可以组成多头注意力机制,通过对多个头得到的信息进行拼接,可以提高模型的表达能力。(一个查询、键、值的组合表示了一种对输入序列中某个位置的编码和解码方式,也就是对某一个方向进行关注)
2.为了使得多头注意力机制能够学习到输入序列中不同位置之间的关系,需要对查询、键、值进行线性变换,具体来说,通过对查询、键、值分别乘上对应的权重矩阵,可以将它们从原始的向量空间映射到一个新的向量空间中。这样做的好处是可以使得不同位置之间的关系更加明确,从而更好地进行编码和解码也就是放大位置之间的关系。
计算qk关系其实就是在不断的重构q.*
3.将多个头得到的张量拼接在一起的是为了提高模型的表达能力。通过将多个头得到的信息进行拼接,可以使得模型更好地捕捉输入序列中不同位置之间的关系,从而提高模型的性能。另外,通过拼接操作,还可以减少模型中的参数数量,从而提高模型的运行效率。
4.通过将多组
Q
,
K
,
V
Q,K,V
Q,K,V 进行拼接,可以使得模型在多个不同的表示空间中进行计算,从而提高模型的表达能力,可以使得模型更加健壮和泛化能力更强,因此多头注意力机制将多组
Q
,
K
,
V
Q,K,V
Q,K,V 进行拼接,而不是将注意力权重矩阵与
V
V
V 矩阵计算得到的结果拼接在一起。
5、能够充分理解与关注输入语句不同角度的意思
















 1219
1219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









