






Title
题目
Segment Anything Model for Medical Images?
用于医学图像的分割任何物模型
01
文献速递介绍
ChatGPT1和GPT-42等大型语言模型的出现,开启了自然语言处理(NLP)的新纪元,这些模型以其卓越的零样本和少样本泛化能力而著称。这一进步激励研究者们为计算机视觉(CV)开发类似的大规模基础模型。首批提出的基础CV模型主要基于预训练方法,如CLIP(Radford et al., 2021)和ALIGN(Jia et al., 2021)。
CLIP能够通过将视觉概念和细节(如对象的形状、纹理和颜色)与相应的文本描述关联起来,来识别和理解这些概念和细节。这使CLIP能够执行广泛的任务,包括图像分类、对象检测,甚至视觉问答。ALIGN能够生成图像区域的自然语言描述,提供比传统图像字幕方法更详细、更易解释的结果。DALL·E(Ramesh et al., 2021)被开发用于从文本描述生成图像。该模型在一个大型文本-图像对数据集上训练,能够创造出从逼真对象到结合多个概念的超现实场景的广泛图像范围。
然而,这些模型并未针对图像分割特别是医学图像分割(MIS)进行显式优化。
最近,分割任何物模型(SAM)作为图像分割的一种创新基础模型被提出(Kirillov et al., 2023)。SAM基于视觉变换器(ViT)(Dosovitskiy et al., 2020)模型,并在包含1亿掩模的1100万图像的大型数据集上训练。SAM最大的亮点是其对未见数据集和任务的良好零样本分割性能。这一过程由不同的提示驱动,例如,点和框,用于指示目标对象的像素级语义和区域级位置。已被证明,它具有极高的通用性,能够应对广泛的分割任务(Kirillov et al., 2023)。
Abstract-Background
摘要
The Segment Anything Model (SAM) is the first foundation model for general image segmentation. It has achieved impressive results on various natural image segmenta tion tasks. However, medical image segmentation (MIS) is more challenging because of the complex modalities, fine anatomical structures, uncertain and complex object boundaries, and wide-range object scales. To fully validate SAM’s performance on medical data, we collected and sorted 53 open-source datasets and built a large med ical segmentation dataset with 18 modalities, 84 objects, 125 object-modality paired targets, 1050K 2D images, and 6033K masks. We comprehensively analyzed different models and strategies on the so-called COSMOS 1050K dataset. Our findings mainly include the following: 1) SAM showed remarkable performance in some specific ob jects but was unstable, imperfect, or even totally failed in other situations. 2) SAM with the large ViT-H showed better overall performance than that with the small ViT
B. 3) SAM performed better with manual hints, especially box, than the Everything mode. 4) SAM could help human annotation with high labeling quality and less time. SAM was sensitive to the randomness in the center point and tight box prompts, and may suffer from a serious performance drop. 6) SAM performed better than interac tive methods with one or a few points, but will be outpaced as the number of points increases. 7) SAM’s performance correlated to different factors, including boundary complexity, intensity differences, etc. 8) Finetuning the SAM on specific medical tasks could improve its average DICE performance by 4.39% and 6.68% for ViT-B and ViT-H, respectively. Codes and models are available at: https://github.com/yuhoo0302/ Segment-Anything-Model-for-Medical-Images. We hope that this comprehen sive report can help researchers explore the potential of SAM applications in MIS, and
guide how to appropriately use and develop SAM.
© 2024 Elsevier B. V. All rights reserved.
分割任何物模型(SAM)是第一个用于通用图像分割的基础模型。它在各种自然图像分割任务上取得了令人印象深刻的结果。然而,医学图像分割(MIS)更具挑战性,因为其复杂的模式、精细的解剖结构、不确定和复杂的对象边界以及广泛的对象尺度。为了全面验证SAM在医学数据上的性能,我们收集和整理了53个开源数据集,并构建了一个大型的医学分割数据集,包括18种模态、84个对象、125个对象-模态配对目标、1050K 2D图像和6033K掩模。我们在所谓的COSMOS 1050K数据集上对不同的模型和策略进行了全面分析。我们的发现主要包括:1)SAM在某些特定对象上表现出色,但在其他情况下不稳定、不完美甚至完全失败。2)配备大型ViT-H的SAM比配备小型ViT-B的性能更好。3)SAM在手动提示(特别是框提示)下的表现优于Everything模式。4)SAM可以在高标注质量和较少时间的情况下帮助人工标注。5)SAM对中心点和紧密框提示的随机性敏感,并可能遭受严重的性能下降。6)与一点或几点的交互式方法相比,SAM表现更好,但随着点数的增加,其性能将被超越。7)SAM的性能与不同因素相关,包括边界复杂性、强度差异等。8)对特定医学任务进行SAM的微调,可以分别使ViT-B和ViT-H的平均DICE性能提高4.39%和6.68%。代码和模型可在以下链接获取:https://github.com/yuhoo0302/Segment-Anything-Model-for-Medical-Images。我们希望这份全面的报告能帮助研究人员探索SAM在MIS中的潜力,并指导如何适当地使用和发展SAM。
Conclusions
结论
In this study, we comprehensively evaluated the SAM for the segmentation of a large medical image dataset. Based on the aforementioned empirical analyses, our conclusions are as fol lows: 1) SAM showed remarkable performance in some spe cific objects but was unstable, imperfect, or even totally failed in other situations. 2) SAM with the large ViT-H showed bet ter overall performance than that with the small ViT-B. 3) SAM performed better with manual hints, especially box, than the Everything mode. 4) SAM could help human annotation with high labeling quality and less time. 5) SAM is sensitive to the randomness in the center point and tight box prompts, and may suffer from a serious performance drop. 6) SAM performed better than interactive methods with one or a few points, but will be outpaced as the number of points increases. 7) SAM’s performance correlated to different factors, including boundary complexity, etc. 8) Finetuning the SAM on specific medical tasks could improve its average DICE performance by 4.39% and 6.68% for ViT-B and ViT-H, respectively. Finally, we be lieve that, although SAM has the potential to become a general MIS model, its performance in the MIS task is not stable at present. We hope that this report will help readers and the com munity better understand SAM’s segmentation performance in medical images and ultimately facilitate the development of a new generation of MIS foundation models.
在这项研究中,我们全面评估了SAM在大型医学图像数据集分割方面的应用。基于上述实证分析,我们的结论如下:1) SAM在一些特定对象上表现出色,但在其他情况下不稳定、不完美甚至完全失败。2) 配备大型ViT-H的SAM总体性能优于配备小型ViT-B的。3) SAM在手动提示,特别是框提示下的表现,优于Everything模式。4) SAM能够帮助人类进行高质量标注且耗时更少。5) SAM对中心点和紧密框提示的随机性敏感,并可能遭受严重性能下降。6) SAM在使用一个或几个点的交互式方法下表现更好,但随着点数的增加将被超越。7) SAM的性能与不同因素相关,包括边界复杂性等。8) 在特定医疗任务上对SAM进行微调,可以使ViT-B和ViT-H的平均DICE性能分别提高4.39%和6.68%。最后,我们认为,尽管SAM有潜力成为一种通用的医学图像分割(MIS)模型,但其在MIS任务中的性能目前尚不稳定。我们希望这份报告能帮助读者和社区更好地理解SAM在医学图像分割中的性能,并最终促进新一代MIS基础模型的发展。
Figure
图
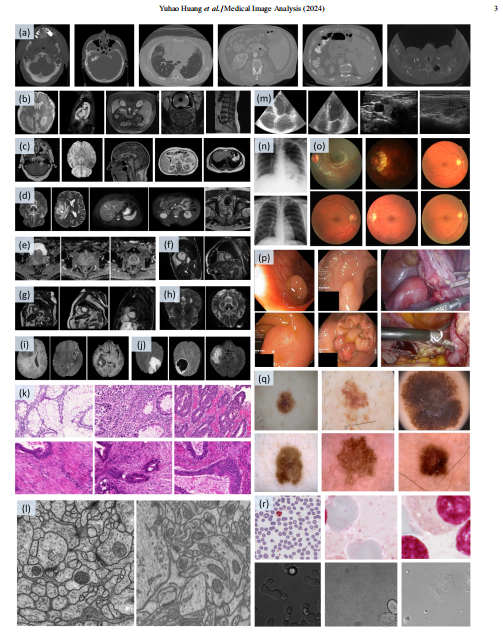
Fig. 1: Our COSMOS 1050K dataset contains various modalities involving (a) CT, (b) MRI, (c) T1-weighted (T1W) MRI, (d) T2-weighted (T2W) MRI, (e) ADC MRI, (f) Cine-MRI, (g) CMR, (h) diffusion-weighted (DW) MRI, (i) post-contrast T1-weighted (T1-GD) MRI, (j) T2 Fluid Attenuated Inversion Recovery (T2- FLAIR) MRI, (k) Histopathology, (l) Electron Microscopy, (m) Ultrasound (US), (n) X-ray, (o) Fundus, (p) Colonoscopy, (q) Dermoscopy, and (r) Microscopy
图1:我们的COSMOS 1050K数据集包含多种模态,包括 (a) CT,(b) MRI,(c) T1加权(T1W)MRI,(d) T2加权(T2W)MRI,(e) ADC MRI,(f) Cine-MRI,(g) 心脏磁共振成像(CMR),(h) 扩散加权(DW)MRI,(i) 对比剂后T1加权(T1-GD)MRI,(j) T2液体衰减反转恢复(T2-FLAIR)MRI,(k) 组织病理学,(l) 电子显微镜,(m) 超声(US),(n) X光,(o) 眼底,(p) 结肠镜,(q) 皮肤镜,以及 (r) 显微镜。
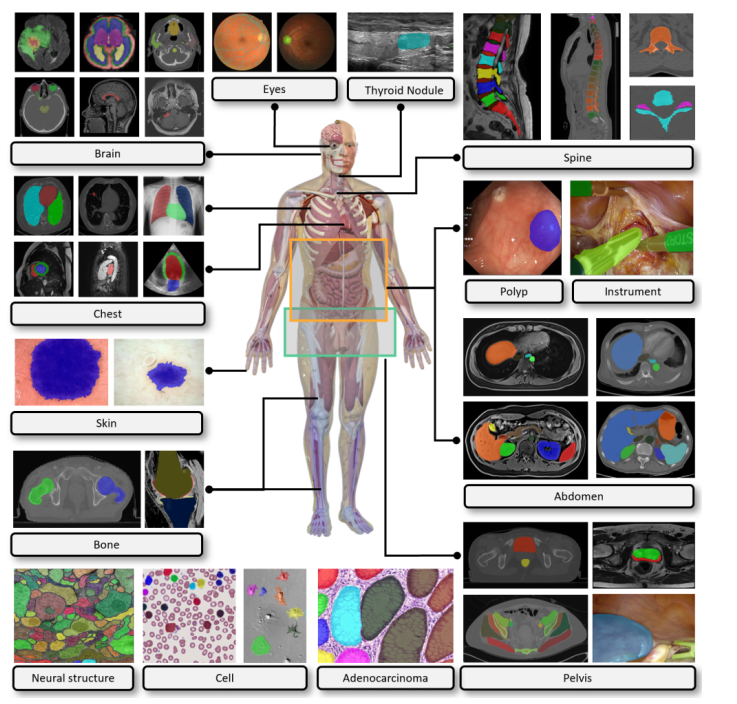
Fig. 2: Our COSMOS 1050K dataset covers the majority of biomedical objects, for example, brain tumors, fundus vasculature, thyroid nodules, spine, lung, heart, abdominal organs and tumors, cell, polyp, and instrument.
图2:我们的COSMOS 1050K数据集涵盖了大多数生物医学对象,例如,脑肿瘤、眼底血管、甲状腺结节、脊柱、肺、心脏、腹部器官和肿瘤、细胞、息肉和器械。
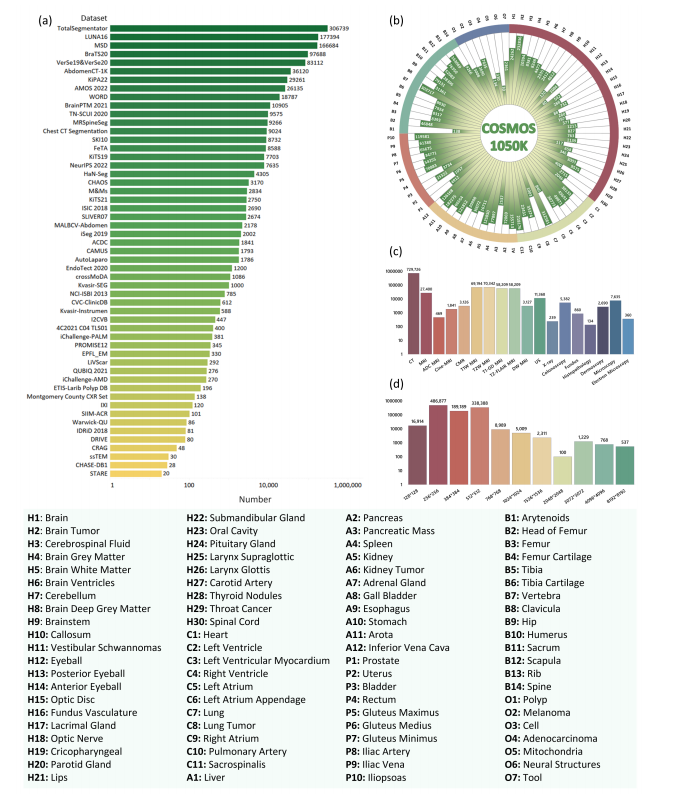
Fig. 3: Statistics of COSMOS 1050K dataset. (a) Number of datasets after preprocessing. (b) Histogram distribution of 84 objects’ quantity, as indicated by the abbreviated mapping provided in the legend. (c) Number of Modalities. (d) Histogram distribution of image resolutions. In (d), each bar represents an area interval distribution, e.g., 128 ∗ 128 represents the image area interval (0, 128 ∗ 128); 256 ∗ 256 represents the image area interval (128 ∗ 128, 256 ∗ 256)
图3:COSMOS 1050K数据集的统计信息。(a) 预处理后数据集的数量。(b) 根据图例中提供的缩写映射,显示84个对象数量的直方图分布。(c) 模态数量。(d) 图像分辨率的直方图分布。在(d)中,每个条形代表一个面积间隔分布,例如,128128代表图像面积间隔(0, 128128);256256代表图像面积间隔(128128, 256*256)。
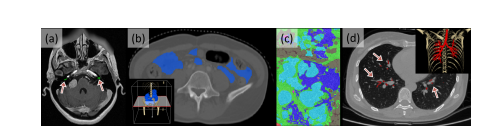
Fig. 4: Typical examples of meeting the exclusion criteria. (a) cochlea (criteria1), (b) intestine (criteria 2), (c) histopathological breast cancer (criteria 3), and (d) lung trachea trees (criteria 3). The corners (b) and (d) show the 3D rendering images obtained by Pair annotation software package (Liang et al., 2022).
图4:典型的符合排除标准的例子。(a) 耳蜗(标准1),(b) 肠(标准2),(c) 组织病理学乳腺癌(标准3),以及(d) 肺气管树(标准3)。角落(b)和(d)展示了通过Pair注释软件包(Liang et al., 2022)获得的3D渲染图像。
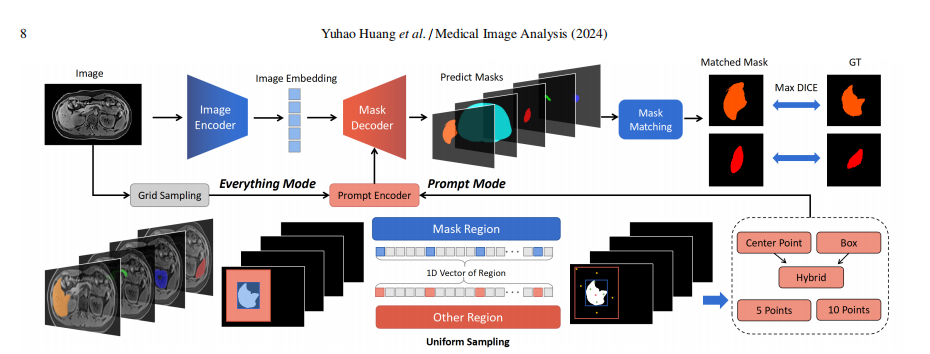
Fig. 5: Testing pipeline of SAM in our study
图5:我们研究中SAM的测试流程
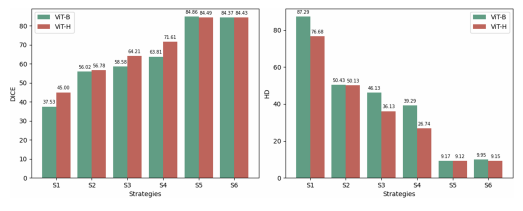
Fig. 6: Comparison of the average performance of ViT-B and ViT-H under different strategies.
图6:在不同策略下,ViT-B和ViT-H平均性能的比较。
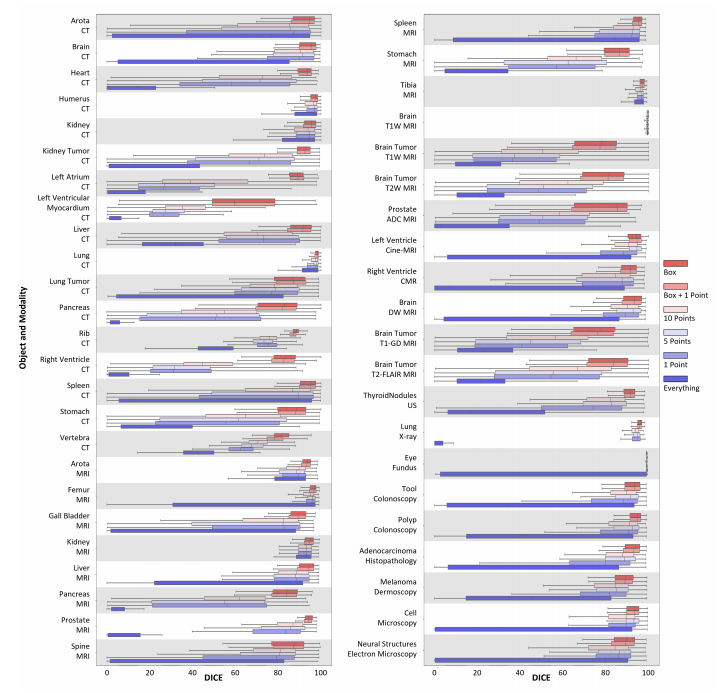
Fig. 7: Comparison of DICE performance for selective common medical objects under ViT-B in different testing strategies
图7:在不同测试策略下,ViT-B针对选定常见医学对象的DICE性能比较。

Fig. 8: Comparison of DICE performance for selective common medical objects under ViT-H in different testing strategies.
图8:在不同测试策略下,ViT-H针对选定常见医学对象的DICE性能比较。
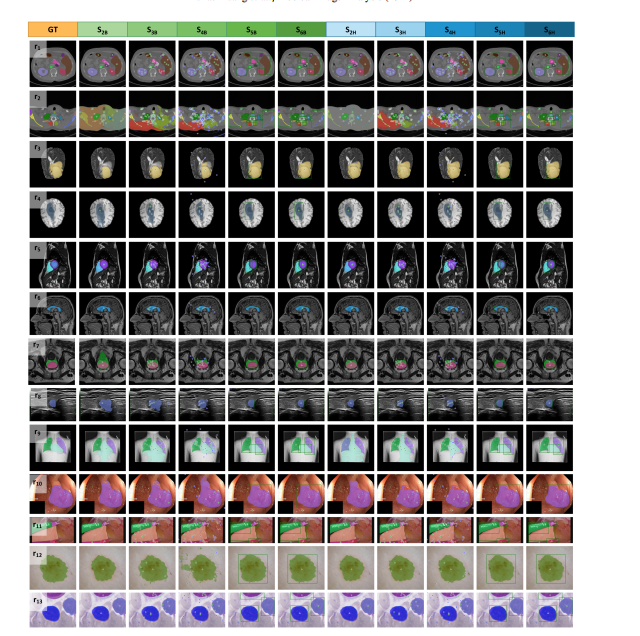
Fig. 9: Typical good cases of SAM (r: row). r1, r2: CT, r3, r7: T2W MRI, r4, r6: T1W MRI, r5: CMR, r8: US, r9: X-ray, r10, r11: Colonoscopy, r12: Dermoscopy, r13: Microscopy. Green and blue stars represent positive and negative point prompts, respectively. The green box indicates the box prompt.
图9:SAM的典型良好案例(r:行)。r1,r2:CT,r3,r7:T2W MRI,r4,r6:T1W MRI,r5:CMR,r8:US,r9:X光,r10,r11:结肠镜,r12:皮肤镜,r13:显微镜。绿色和蓝色星星分别代表正面和负面点提示。绿色框表示框提示。
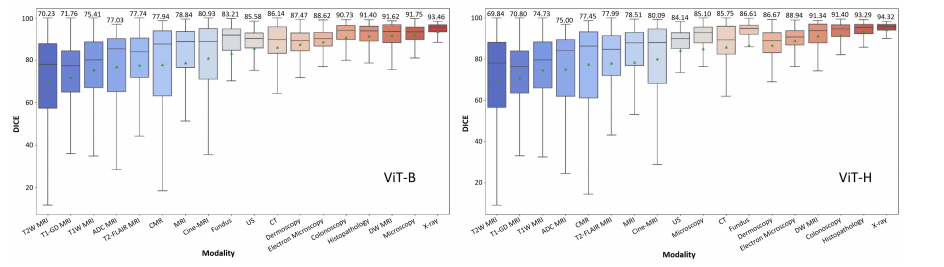
Fig. 10: DICE performance of 18 different modalities. The green triangle and the values above each box in the box plot represent the average value.
图10:18种不同模态的DICE性能。箱线图中每个箱体上方的绿色三角形和数值代表平均值。

Fig. 11: Different cases of Adenocarcinoma (Sirinukunwattana et al., 2017), Mitochondria (Lucchi et al., 2013) and Neural Structures (Cardona et al., 2010) with different numbers of points in S 1H.
图11:在S 1H中,具有不同点数的腺癌(Sirinukunwattana et al., 2017)、线粒体(Lucchi et al., 2013)和神经结构(Cardona et al., 2010)的不同案例。
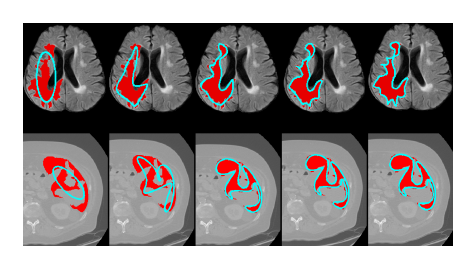
Fig. 12: Contour decoded from the Fourier series. From left to right, the de coded contour (blue) gets closer to the original contours (red) as the FO in creases.
图12:从傅里叶级数解码的轮廓。从左到右,随着FO(频率顺序)的增加,解码的轮廓(蓝色)越来越接近原始轮廓(红色)。
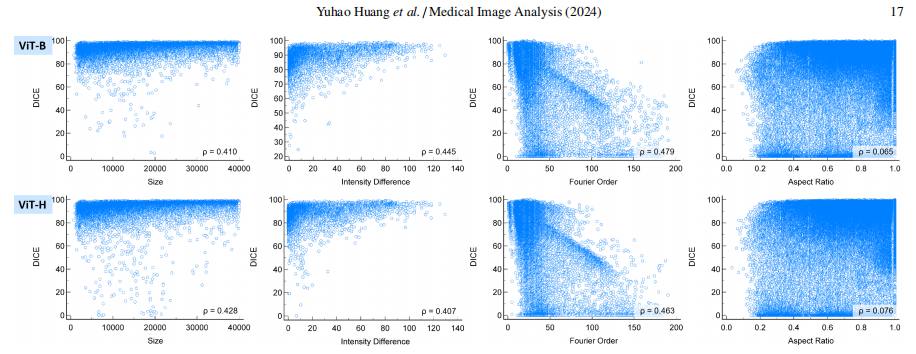
Fig. 13: Scatterplot of different object attributes with DICE under S 5 strategies.
图13:在S 5策略下,不同对象属性与DICE的散点图。

Fig. 14: FO boxplot of different DICE ranges.
图14:不同DICE范围的FO箱线图。
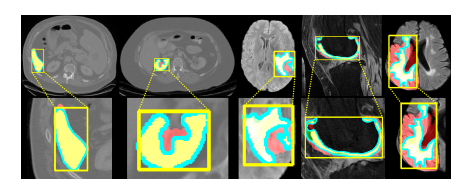
Fig. 15: Relationship between DICE and FO. From left to right, FO gradually increases. The yellow box represents the box prompt, the red mask is the pre diction, the green mask is the GT, the yellow mask is the overlap of prediction and GT, and the blue contour is decoded from the Fourier series.
图15:DICE与FO之间的关系。从左到右,FO逐渐增加。黄色框代表框提示,红色掩模是预测,绿色掩模是真实标注(GT),黄色掩模是预测和真实标注的重叠部分,蓝色轮廓是从傅里叶级数解码得到的。

Fig. 16: Average performance of three different methods varies with the number of point prompts.
图16:随着点提示数量的变化,三种不同方法的平均性能如何变化。

Fig. 17: Trend analysis of DICE under different attributes (ViT-B and ViT-H with box prompt, S 5). The blue circles show the most obvious changes.
图17:在不同属性下DICE的趋势分析(带框提示的ViT-B 和 ViT-H,S 5)。蓝色圆圈显示了最明显的变化。
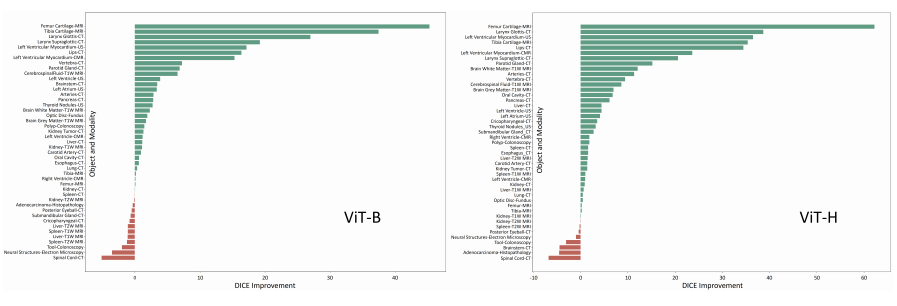
Fig. 18: DICE improvement after finetuning, including SAM with ViT-B and ViT-H.
图18:微调后DICE的改善情况,包括带有ViT-B和ViT-H的SAM。
Table
表
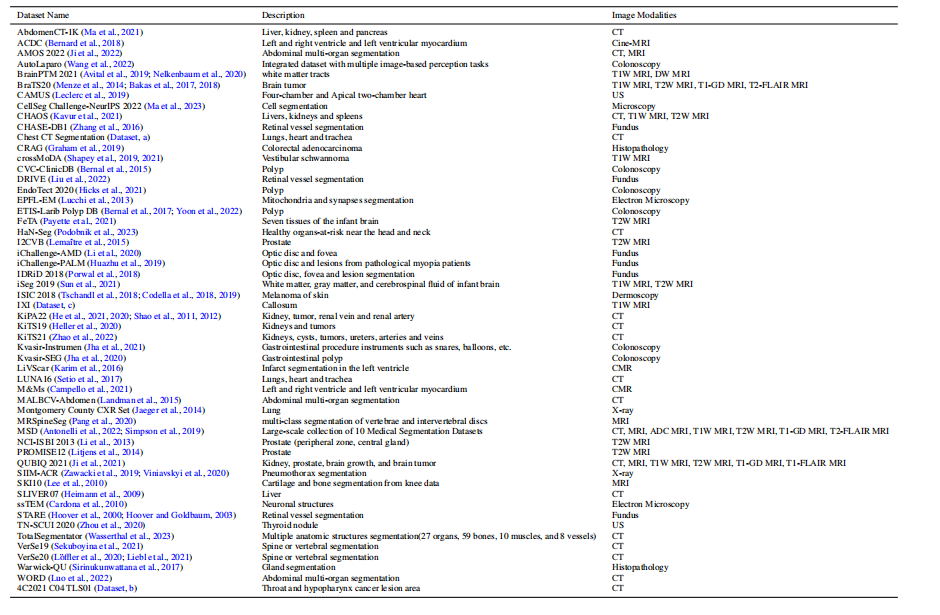
Table 1: Description of the collected dataset. MALBCV-Abdomen is an abbreviation for the abdomen dataset of Multi-Atlas Labeling Beyond the Cranial Vault.
表1:收集数据集的描述。MALBCV-腹部是超越颅顶的多图谱标记腹部数据集的缩写。
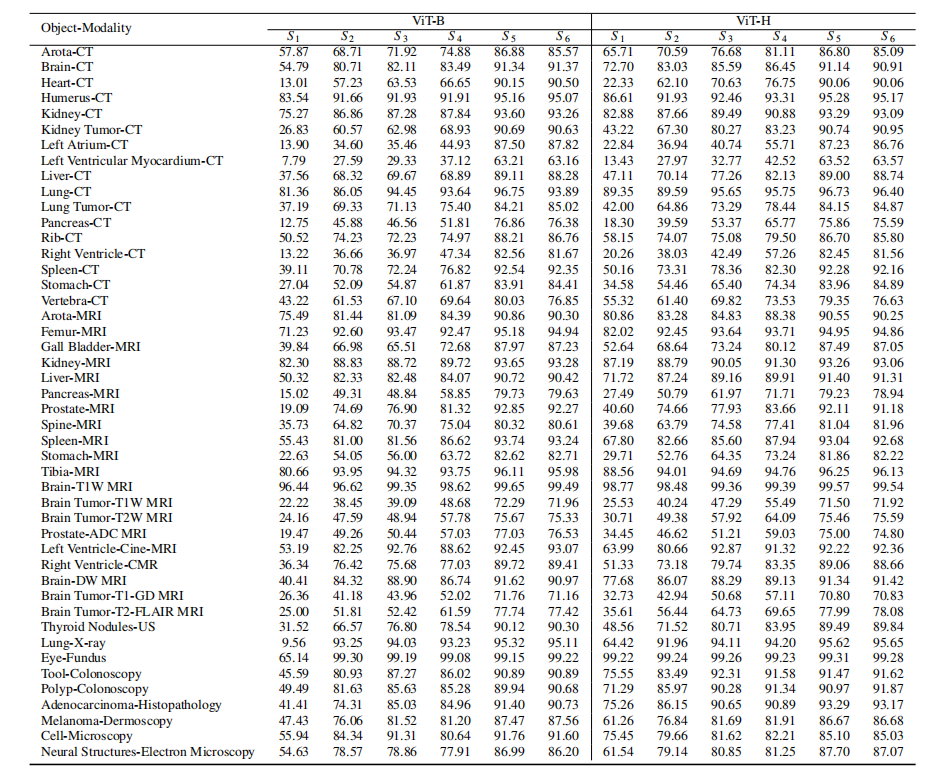
Table 2: Performance on selective common medical objects with different modalities in terms of DICE score (%). ViT-B and ViT-H represent the small and largeencoders of SAM. S 1-S 6 represent different testing strategies, including everything, 1 point, 5 points, 10 points, box, and box with 1 point, respectively.
表2:在不同模态下,针对选定常见医学对象的DICE得分(%)性能比较。ViT-B 和 ViT-H 代表SAM的小型和大型编码器。S 1-S 6 代表不同的测试策略,依次包括everything(一切),1点,5点,10点,框,以及框加1点。
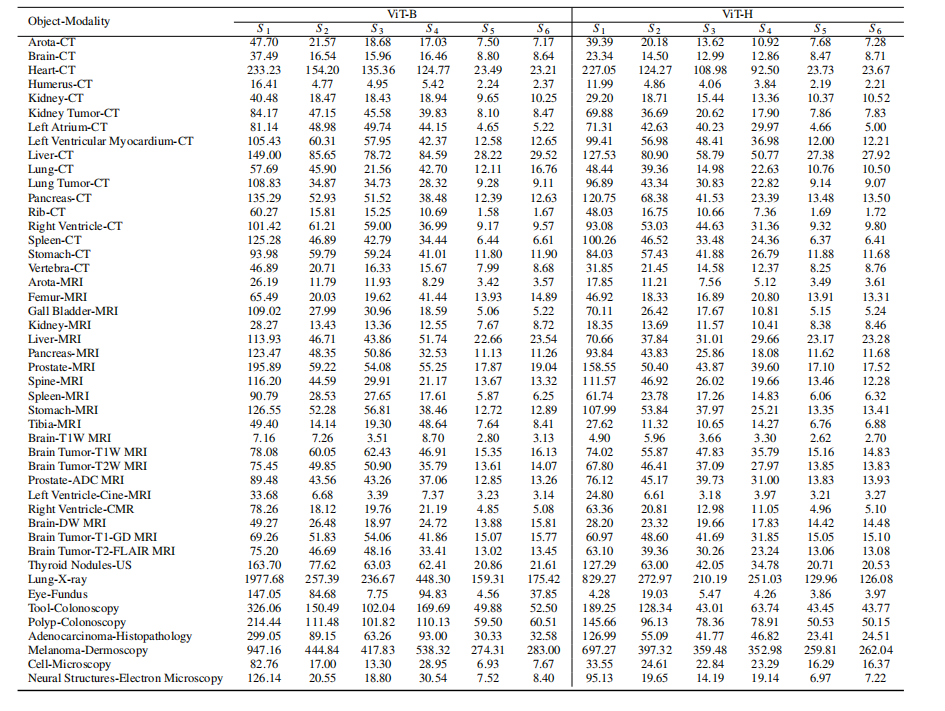
Table 3: Performance on selective common medical objects with different modalities in terms of HD (pixels). ViT-B and ViT-H represent the small and large encoders of SAM. S 1-S 6 represent different testing strategies, including everything, 1 point, 5 points, 10 points, box, and box with 1 point, respectively
表3:在不同模态下,针对选定常见医学对象的HD(像素)性能比较。ViT-B 和 ViT-H 代表SAM的小型和大型编码器。S 1-S 6 代表不同的测试策略,依次包括everything(一切),1点,5点,10点,框,以及框加1点。
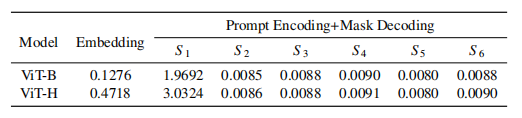
Table 4: Test time analysis of SAM (seconds).
表4:SAM的测试时间分析(秒)。

Table 5: Ablation study on the number of points in Everything mode.
表5:在Everything模式下,对点数进行消融研究。
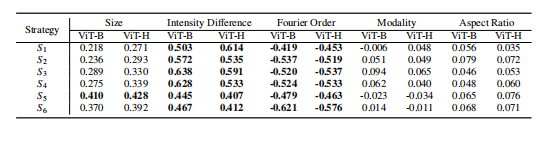
Table 6: Spearman partial correlation analysis (values with p < 0.001 areshown in bold).
表6:斯皮尔曼偏相关分析(p < 0.001的值以粗体显示)。
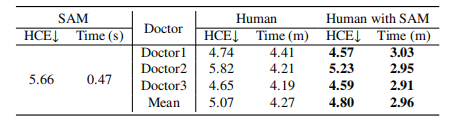
Table 7: Annotation speed and quality of a human with or without SAM’s help. s: seconds, m: minutes.
表7:人工标注的速度和质量,分别在有无SAM帮助的情况下。s:秒,m:分钟。
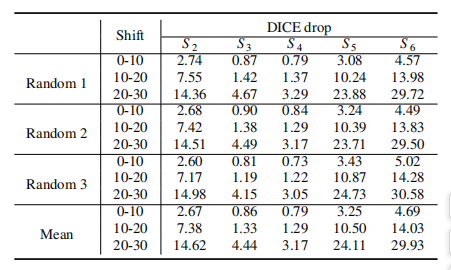
Table 8: Comparison of DICE decrease under different shifting levels and test ing strategies.
表8:在不同偏移水平和测试策略下,DICE下降的比较。















 1879
1879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









