






Title
题目
Re-identification from histopathology images
组织病理学图像中的再识别
01
文献速递介绍
在光学显微镜下评估苏木精-伊红(H&E)染色切片是肿瘤病理诊断中的标准程序。随着全片扫描仪的出现,玻片切片可以被数字化为所谓的全片图像(WSIs)。这使得肿瘤评估能够使用自动化方法,尤其是深度学习(DL)算法,它们在数字病理学领域引发了革命。这些模型在自动肿瘤分级和分类(Nir等,2018;Han等,2017;Ganz等,2021)等各种任务中表现出令人期待的性能,或在生物标志物的自动评估(包括有丝分裂计数,Aubreville等,2023;Veta等,2019)或肿瘤区域分割(Wilm等,2022)中表现突出。一些DL算法甚至能够从WSIs中提取人类专家无法识别的信息,如分子改变的预测(Coudray等,2018;Hong等,2021;Lu等,2021b)或转移瘤原发部位的预测(Lu等,2021a)。
Aastract
摘要
In numerous studies, deep learning algorithms have proven their potential for the analysis of histopathologyimages, for example, for revealing the subtypes of tumors or the primary origin of metastases. These modelsrequire large datasets for training, which must be anonymized to prevent possible patient identity leaks.This study demonstrates that even relatively simple deep learning algorithms can re-identify patients in largehistopathology datasets with substantial accuracy. In addition, we compared a comprehensive set of state-ofthe-art whole slide image classifiers and feature extractors for the given task. We evaluated our algorithms ontwo TCIA datasets including lung squamous cell carcinoma (LSCC) and lung adenocarcinoma (LUAD). We alsodemonstrate the algorithm’s performance on an in-house dataset of meningioma tissue. We predicted the sourcepatient of a slide with 𝐹1 scores of up to 80.1% and 77.19% on the LSCC and LUAD datasets, respectively,and with 77.09% on our meningioma dataset. Based on our findings, we formulated a risk assessment schemeto estimate the risk to the patient’s privacy prior to publication.
在众多研究中,深度学习算法在组织病理学图像分析中展示了其潜力,例如用于揭示肿瘤的亚型或转移瘤的原发部位。然而,这些模型的训练通常需要大型数据集,这些数据集必须进行匿名处理,以防止可能的患者身份泄露。本研究表明,即使是相对简单的深度学习算法也能够在大型组织病理学数据集中以较高的准确性重新识别患者。此外,我们对一组先进的全片图像分类器和特征提取器进行了比较,以完成这一任务。我们在两个TCIA数据集上评估了我们的算法,包括肺鳞状细胞癌(LSCC)和肺腺癌(LUAD)。我们还展示了该算法在自有脑膜瘤组织数据集上的表现。我们在LSCC和LUAD数据集上分别预测了切片来源患者,获得的F1分数分别高达80.1%和77.19%,在脑膜瘤数据集上为77.09%。基于我们的研究结果,我们制定了一项风险评估方案,用于在发布前评估患者隐私的风险。
Method
方法
In this study, we utilized three distinct datasets of which two arepublicly available. Those two datasets, namely lung adenocarcinoma(LUAD) (National Cancer Institute Clinical Proteomic Tumor Analysis Consortium (CPTAC), 2018a) and lung squamous cell carcinoma(LSCC) (National Cancer Institute Clinical Proteomic Tumor AnalysisConsortium (CPTAC), 2018b), were obtained from TCIA (Clark et al.,2013). In the remainder of this paper, these datasets will be referred toas the LUAD dataset and the LSCC dataset. These datasets were scannedat a resolution of 0.5 μm per pixel and were obtained from variouspathology centers. We restricted our analysis to slides of patients forwhich at least two slides were available, resulting in 1059 images of226 patients for the LUAD dataset and 1071 images of 209 patients ofthe LSCC dataset.
在本研究中,我们使用了三个不同的数据集,其中两个是公开可用的。这两个数据集,分别为肺腺癌(LUAD)(美国国家癌症研究所临床蛋白质组肿瘤分析联盟(CPTAC),2018a)和肺鳞状细胞癌(LSCC)(美国国家癌症研究所临床蛋白质组肿瘤分析联盟(CPTAC),2018b),来自TCIA(Clark等,2013)。在本文的其余部分,这些数据集将分别被称为LUAD数据集和LSCC数据集。这些数据集以每像素0.5微米的分辨率扫描,并从多个病理中心获取。我们将分析限制在至少有两张切片可用的患者,最终获得了LUAD数据集的226名患者的1059张图像,以及LSCC数据集的209名患者的1071张图像。
Conclusion
结论
This work demonstrates that re-identification of patients fromhistopathology images of resected tumor specimens is possible, withsome limitations. As long as the slides originate from the same tumor,we can re-identify the patients with considerable accuracy (as canbe seen in Tables 1 and 2). If the slides were resected at differentpoints in time, the accuracy is considerably lower (see Table 3). Asuccessful resection should completely remove the tumor, and hencea later resection resembles a regrowth of an incomplete resection or anew tumor of potentially different pathogenesis and mutational pattern.Our results indicate that the strong performance drop could be linkedto different morphological tumor characteristics. Consequently, ourapproach is more likely to identify tumors than patients.Which visual factors in particular contribute to the re-identificationis a question for future research. However, even if the models wouldheavily rely on traces related to slide preparation to re-identify theslides, this would threaten patient privacy. Therefore if these factorswould imprint some kind of implicit visual time stamp, future workcan focus on how to remove these traces from the slides.Our results indicate that the safest way of publishing histopathologyimages is to only use each patient in one data publication, as tracingacross datasets and hence recombination of multiple meta and imagedatasets is feasible, especially if slides originating from the same tumorare used in different datasets.
这项研究表明,基于切除肿瘤标本的组织病理学图像对患者进行再识别是可行的,尽管存在一些局限性。只要切片来自同一肿瘤,我们可以以相当高的准确率重新识别患者(如表1和表2所示)。然而,如果切片是在不同时期切除的,准确率则显著降低(见表3)。一次成功的切除应完全清除肿瘤,因此后续的切除往往代表未完全切除的肿瘤再生或具有不同病因和突变模式的新肿瘤。我们的结果表明,这种性能大幅下降可能与肿瘤不同的形态学特征有关。因此,我们的方法更可能识别的是肿瘤,而不是患者。
未来的研究需要回答哪些视觉因素特别有助于再识别的问题。然而,即使模型主要依赖于与切片准备相关的痕迹进行再识别,这也会威胁到患者隐私。因此,如果这些因素在切片中留下了某种隐含的视觉时间戳,未来的工作可以着眼于如何从切片中去除这些痕迹。
我们的结果表明,发布组织病理学图像最安全的方式是每位患者的图像仅在一次数据发布中使用。因为跨数据集追踪并重新组合多个元数据和图像数据集是可行的,特别是当来自同一肿瘤的切片被用于不同的数据集中时。
Results
结果
For all experiments, we report the recall@1, recall@5, the precisionand the 𝐹1 score. These values are always the average values over allclasses. When considering recall@n, it means that for an algorithm’spredictions to be considered correct, the searched patient has to beincluded among the 𝑛 patients with the highest-ranked predictionsbased on the classification score. In a multiclass classification problem,the average recall@1 equals the balanced accuracy. For comparison,the probability of selecting the right patient by chance when assessing 𝑁 patients is also given for each dataset.
对于所有实验,我们报告了 recall@1、recall@5、precision(精确度)和 𝐹1 分数。这些值始终是对所有类别的平均值。对于 recall@n,它意味着算法的预测要被认为是正确的,目标患者必须包含在基于分类得分排名前 𝑛 的患者中。在多类别分类问题中,recall@1 的平均值等于平衡准确率。为了对比,针对每个数据集,还给出了评估 𝑁 名患者时随机选择正确患者的概率。
Figure
图
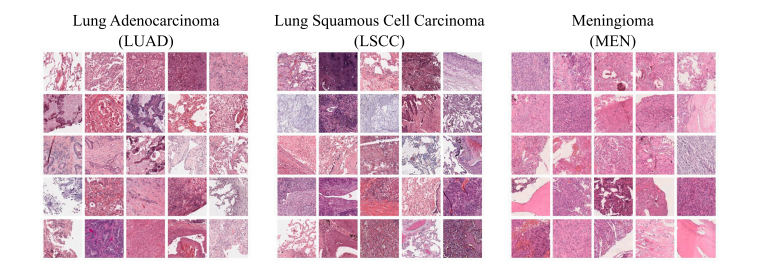
Fig. 1. Overview of randomly selected patches from the three datasets used. In contrast to our in-house meningioma dataset (MEN), the lung adenocarcinoma (LUAD) and lung squamous cell carcinoma (LSCC) datasets originating from TCIA exhibit a more pronounced visual variance. Each patch covers an area of about 0.012 square millimeters
图 1. 来自三个数据集的随机选取的图像块概述。与我们的自有脑膜瘤数据集(MEN)相比,源自TCIA的肺腺癌(LUAD)和肺鳞状细胞癌(LSCC)数据集表现出更明显的视觉差异。每个图像块覆盖约0.012平方毫米的区域。
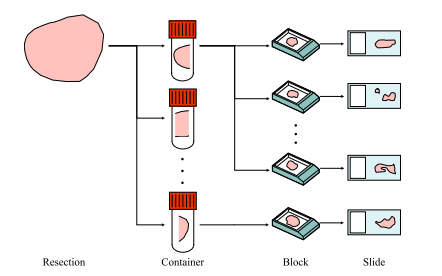
Fig. 2. Scheme of the tissue preparation procedure used to prepare the slides in the in-house meningioma (MEN) dataset. A resection can be divided into one or more containers, each of which can be further divided into one or more blocks. However, only one slide from each block is included in the data set.
图 2. 用于制备自有脑膜瘤(MEN)数据集中切片的组织准备流程示意图。一个切除样本可以分为一个或多个容器,每个容器可以进一步分为一个或多个蜡块。然而,数据集中只包含每个蜡块中的一张切片。
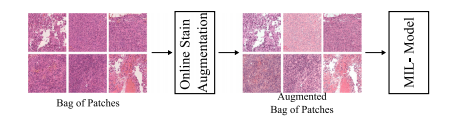
Fig. 3. Scheme of how the online stain augmentation was applied in the naive-MIL model. During training, each of the images within one bag was augmented separately
图 3. 在线染色增强在naive-MIL模型中的应用示意图。在训练过程中,同一个包内的每张图像都被单独增强。
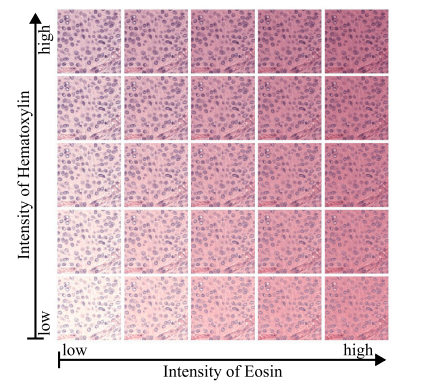
Fig. 4. Given are versions of the same patch to which different intensities of stainaugmentation were applied. A stain augmentation based on the Macenkos stainnormalization method was used. The non augmented patch is given in the center ofthe grid.
图 4. 展示了对同一图像块应用不同强度的染色增强的版本。采用了基于Macenko染色归一化方法的染色增强。未增强的图像块位于网格的中心。
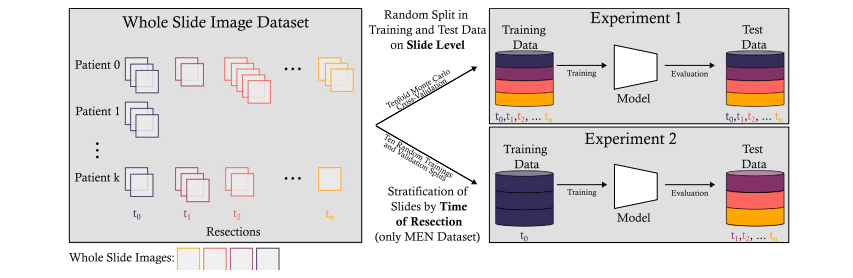
Fig. 5. Overview of the experimental setup of Experiments 1 and 2. Experiment 1 involved a tenfold Monte Carlo cross-validation. In Experiment 2, the slides from the earliest resection were used for training, while all images from later resections were used in a hold-out test dataset. To increase the statistical validity of the results of Experiment 2, tenmodels for each algorithm were trained on ten randomly selected training and validation splits drawn from the earliest resection of each patient.
图 5. 实验 1 和实验 2 的实验设置概述。实验 1 使用了十折蒙特卡洛交叉验证。实验 2 中,最早切除的切片用于训练,而所有后续切除的图像则用于保留测试数据集。为增加实验 2 结果的统计有效性,针对每个算法,分别在每位患者最早切除的随机选择的十个训练和验证分割上训练了十个模型。
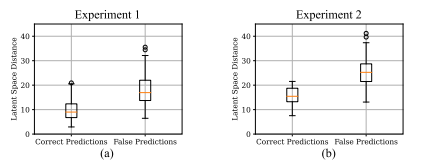
Fig. 6. Distances between test samples and their respective latent space anchors. Subfigure (a) shows the distances for Experiment 1 and sub-figure (b) shows the distancesfor Experiment 2. In general, correctly classified samples are closer to their respectivelatent space anchors.
图 6. 测试样本与其各自潜在空间锚点之间的距离。子图 (a) 显示了实验 1 的距离,子图 (b) 显示了实验 2 的距离。总体而言,正确分类的样本更接近其各自的潜在空间锚点。
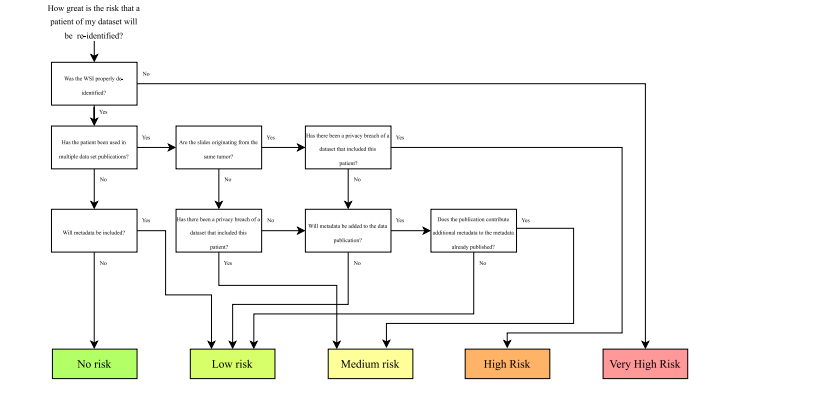
Fig. 7. Risk assessment scheme for estimating patient privacy risks when publishing histopathology images.
图 7. 评估在发布组织病理学图像时患者隐私风险的风险评估方案。
Table
表
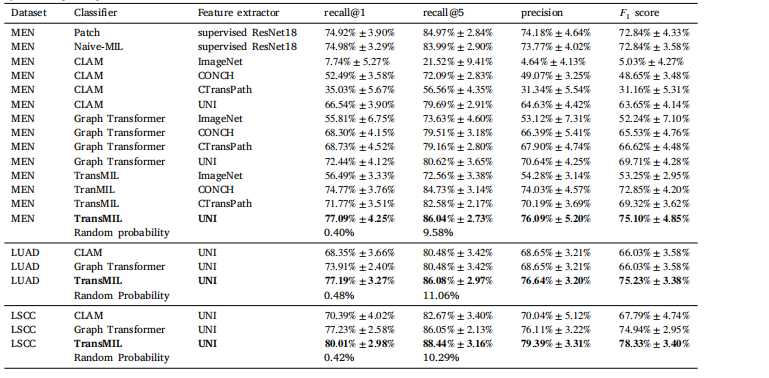
Table 1Results of Experiment 1. The respective means and standard deviations of the tenfold Monte Carlo cross-validation are given. In a multiclass classification problem, the mean recall is equal to the balanced accuracy. Random probability is the probability of selecting the correct patient by random guessing.
表 1实验 1 的结果。提供了十折蒙特卡洛交叉验证的相应均值和标准差。在多类别分类问题中,平均召回率等于平衡准确率。随机概率指的是通过随机猜测选择正确患者的概率。

Table 2 Results of Experiment 1 while using strong stain augmentation during training. The respective means and standard deviations of the tenfoldMonte Carlo cross-validation are given. In a multiclass classification problem, the mean recall is equal to the balanced accuracy. Randomprobability is the probability of selecting the correct patient by random guessing.
表 2实验 1 的结果,在训练期间使用了强染色增强。提供了十折蒙特卡洛交叉验证的相应均值和标准差。在多类别分类问题中,平均召回率等于平衡准确率。随机概率指的是通过随机猜测选择正确患者的概率。

Table 3Results of Experiment 2. In a multiclass classification problem, the balanced accuracy equals the average recall. Random probability is the probability of selecting the correct patient by random guessing
表 3实验 2 的结果。在多类别分类问题中,平衡准确率等于平均召回率。随机概率指的是通过随机猜测选择正确患者的概率。
Table A.1Results of the preliminary investigation of the optimal magnification level for patch sampling. Given are the results of the tenfold Monte Carlocross-validation using the MEN dataset and the patch-based model. In each experiment, patches with a width and height of 512 pixels wereused. The spatial resolution is given in microns per pixel (mpp)
表 A.1初步研究的最佳放大倍数下图像块采样结果。表中给出了使用MEN数据集和基于图像块模型的十折蒙特卡洛交叉验证结果。在每次实验中,使用宽度和高度均为512像素的图像块。空间分辨率以每像素微米(mpp)为单位表示。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









