







 本文是《机器学习实战》中KNN算法的应用,通过海伦约会网站的数据,构建分类器对约会对象进行自动分类。数据包括飞行常客里程数、视频游戏时间百分比和每周冰激凌消费量,目标是预测海伦对约会对象的评价。文章涉及数据准备、文本转NumPy、数据可视化等步骤。
本文是《机器学习实战》中KNN算法的应用,通过海伦约会网站的数据,构建分类器对约会对象进行自动分类。数据包括飞行常客里程数、视频游戏时间百分比和每周冰激凌消费量,目标是预测海伦对约会对象的评价。文章涉及数据准备、文本转NumPy、数据可视化等步骤。
《机器学习实战》中KNN算法实例一:关于这个实战的故事背景可以搜索“海伦 约会网站”基本上就可以了解。
这个实验的目的是根据已有的海伦整理出来的约会对象的资料和海伦对约会对象的评价,构造分类器,使对新的约会对象进行自动分类(不喜欢的人,魅力一般的人,极具魅力的人)。
数据准备
海伦准备的约会数据datingTestSet.txt,我已上传github
我们可以先看一下截图:
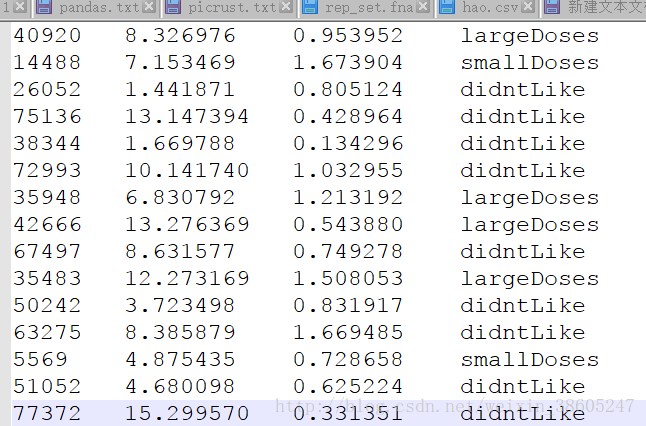
文件一共有四列,每一行为一个约会对象的信息(“每年获得的飞行常客里程数”,“玩视频游戏所消耗的时间百分比”,“每周消费的冰激凌公斤数”),最后一列是海伦对他的评价。
那么得到数据后,我们从下面几个方面来处理数据,帮助海伦来预测约会对象是否合适:
1.先将文本的数据文件转换为NumPy的解析程序
2.分析数据,将数据可视化
3.准备数据:归一化数值
4.测试分类器,计算准确率
5.使用算法,对新的约会对象进行预测
将文本的数据文件转换为NumPy的解析程序
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3926
3926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









