







 文章详细描述了如何运用KNN算法,结合特定数据集(如赵云数据),通过输入武将特征值预测其职业类别(武官或文官)。
文章详细描述了如何运用KNN算法,结合特定数据集(如赵云数据),通过输入武将特征值预测其职业类别(武官或文官)。
思路:
通过KNN算法进行分类(标签:0为武官 1为文官)K值固定为5,并且使用的是欧式距离。
测试样本数据:

导入数据:
import pandas as pd
import numpy as np
import math
#导入数据
filepath='sgz.xlsx'
data=pd.read_excel(filepath)数据集划分:
将整个数据集分成特征值和标签两部分:
#将表格数据划分成特征值和标签
feature_data=data.iloc[:,:-1]
data_label=data.iloc[:,-1]
dataMat = np.mat(feature_data) # 转化为矩阵形式
labelMat = np.mat(data_label).transpose() # 转化为矩阵形式
X = np.array(dataMat) # 将列表转换成数组
complete_data=np.array(data)输入用于预测的数据:
# 用于预测的数据
test=np.array(['赵云', 96, 96, 77, 65]) #预测样本
test=test.astype(object) #转换为object类型
计算得距离最接近的五个武将:
通过计算欧式距离得出与预测样本最接近的五个武将
dis2=[] #用于存储计算得到的距离
# 将test数组中的索引从1到4的元素转换为整数
for j in range(1,5):
test[j]=int(test[j])
# 将X数组中的索引从1到4的元素转换为整数,并计算与test的欧氏距离
for i in range(X.shape[0]):
for j in range(1,5):
X[i][j]=int(X[i][j])
dis = math.sqrt((test[1]-X[i][1])**2+(test[2]-X[i][2])**2+(test[3]-X[i][3])**2+(test[4]-X[i][4])**2)
dis2.append(dis)
dis2=np.array(dis2)
sorted_indices2 = np.argsort(dis2) # 获取排序后的索引
top_five = sorted_indices2[:5] #取排序后前五位的索引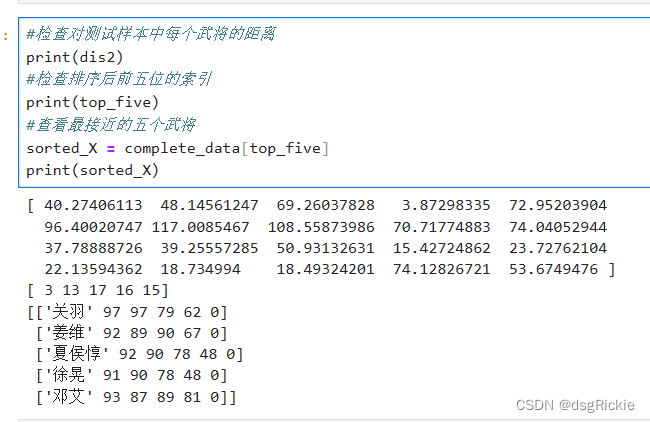
执行判断:
通过判断得出该武将是文官还是武官
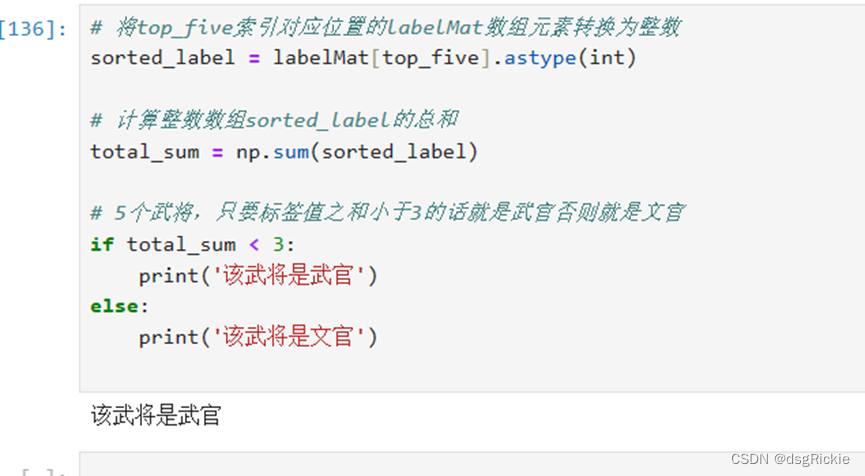
# 将top_five索引对应位置的labelMat数组元素转换为整数
sorted_label = labelMat[top_five].astype(int)
# 计算整数数组sorted_label的总和
total_sum = np.sum(sorted_label)
# 5个武将,只要标签值之和小于3的话就是武官否则就是文官
if total_sum < 3:
print('该武将是武官')
else:
print('该武将是文官')
将以上各功能封装成函数:
import pandas as pd
import numpy as np
import math
def load_and_process_data(filepath):
data = pd.read_excel(filepath)
feature_data = data.iloc[:, :-1]
data_label = data.iloc[:, -1]
dataMat = np.mat(feature_data) # 转化为矩阵形式
labelMat = np.mat(data_label).transpose() # 转化为矩阵形式
X = np.array(dataMat) # 将列表转换成数组
complete_data = np.array(data)
return data, feature_data, data_label, dataMat, labelMat, X, complete_data
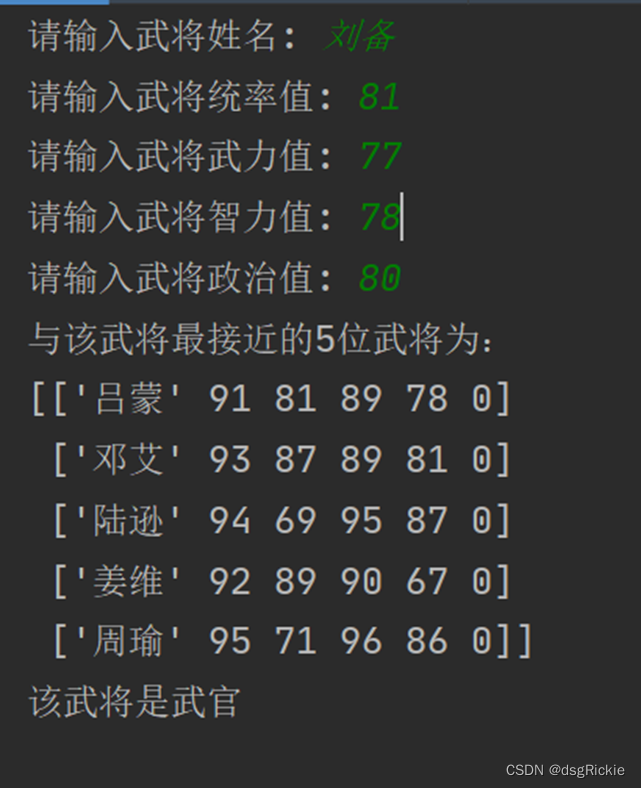
def input_warlord_info():
test_name = input("请输入武将姓名: ")
test_cmd = int(input("请输入武将统率值: "))
test_atk = int(input("请输入武将武力值: "))
test_int = int(input("请输入武将智力值: "))
test_pol = int(input("请输入武将政治值: "))
test = np.array([test_name, test_cmd, test_atk, test_int, test_pol], dtype=object)
return test
def calculate_top_five_distances(test, X):
dis2 = [] # 用于存储计算得到的距离
# 将test数组中的索引从1到4的元素转换为整数
for j in range(1, 5):
test[j] = int(test[j])
# 将X数组中的索引从1到4的元素转换为整数,并计算与test的欧氏距离
for i in range(X.shape[0]):
for j in range(1, 5):
X[i][j] = int(X[i][j])
dis = math.sqrt((test[1]-X[i][1])**2 + (test[2]-X[i][2])**2 + (test[3]-X[i][3])**2 + (test[4]-X[i][4])**2)
dis2.append(dis)
dis2 = np.array(dis2)
sorted_indices2 = np.argsort(dis2) # 获取排序后的索引
top_five = sorted_indices2[:5] # 取排序后前五位的索引
return top_five
def classify_officer_type(labelMat, top_five):
# 将top_five索引对应位置的labelMat数组元素转换为整数
sorted_label = labelMat[top_five].astype(int)
# 计算整数数组sorted_label的总和
total_sum = np.sum(sorted_label)
# 判断武将类型并打印相应信息
if total_sum < 3:
print('该武将是武官')
else:
print('该武将是文官')
def main():
filepath = 'sgz.xlsx'
data, feature_data, data_label, dataMat, labelMat, X, complete_data = load_and_process_data(filepath)
test = input_warlord_info()
top5=calculate_top_five_distances(test,X)
sorted_X = complete_data[top5]
print('与该武将最接近的5位武将为:')
print(sorted_X)
classify_officer_type(labelMat,top5)
if __name__ == "__main__":
main()
程序执行效果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









