









有一个做深度学习模型部署的同学曾经提到过他目前的方向主要是模型压缩,就是对于部署在app上的模型在不影响性能的前提下如何减小模型的体量,我也会经常用Bert等transformer架构的模型,体量过大也是缺点,所以才有了后面的ALBert模型,这里对模型压缩的内容提前了解下,以免后面的工作会用到。
目录
1. 模型压缩的意义
模型压缩更多地是应用到复杂的深度模型上,并且越来越受到重视,因为当模型的准确度达到一定程度后,如何用更少的硬件成本去做模型服务变得有意义。
2. 模型压缩相关技术
- 低秩分解(low-ran approximation/factorization);
- 剪枝,深度学习可以看做是一个复杂树状结构,如果能减去一些对结果没什么影响的旁枝,就可以实现模型的减小;
- 知识蒸馏
- 量化,模型由大量的浮点型权重组成,如果能用float32替代原有的float64表示,模型就近乎减小一倍的体积,量化也是最容易实现的一种压缩方式;
- 权重共享,有点像提取公因数,假设模型的每一层都有公用的公因式,是否可以提取出来在结果处做一次运算,而不是每一层都算一次(如在LayerNorm中,只归一化计算一次可否)
2.1 低秩分解
模型中,如果把原先网络的权值矩阵当做满秩矩阵来看,可以用多个低秩的矩阵来逼近原来的矩阵,以达到简化的目的(想想推荐算法中的基于协同过滤的个性化推荐)。原先稠密的满秩矩阵可以表示为若干个低秩矩阵的组合,低秩矩阵又可以分解为小规模矩阵的乘积。对于二维矩阵运算来说,SVD是非常好的简化方法。目前更高级的低秩分解算法主要包括CP分解、Tucker分解、Tensor Train分解和Block Term分解,主要涉及到Tensor分解来做加速和压缩。
2.2 剪枝
模型的构成是由许多浮点型的神经元相连接,每一层根据神经元的权重将信息向下传递。但是在每一层的神经元中,有些节点的权重非常小,对模型加载信息的影响微乎其微。如果可以把这些权重较小的神经元删掉,既减小了模型大小,对模型的精度等影响也较小。

每一层把数值小的节点去掉,但是需要考虑剪枝的粒度,如可以去掉每层中的5个神经元,或者3个,也可以用L1/L2正则的方式去做。剪多了,模型精度影响会比较大,剪少了效果不明显,所以需要做大量的尝试和迭代,实践中,剪枝是一个迭代的过程,通常叫做迭代式剪枝(Iterative Pruning):修剪-训练-重复。
通过引入AutoML机制,可以通过NAS(神经网络搜索,有点类似于机器学习中的网格搜索)的方式探索出剪枝候选集,然后自动的剪枝、验证、迭代。
2.3 知识蒸馏
蒸馏模型采用的是迁移学些(GPT--ELMO--Bert--XLNET--ERNIE,这些都是迁移学习模型的应用),通过采用预先训练好的负载模型(Teacher model)的输出作为监督信号去训练另一个简单的网络,这个简单的网络被称为student model。
目前来看,无论是压缩比还是蒸馏后的性能都还有待提高。存在的问题和研究的趋势 寻“知识”的不同形式,去除softmax的限制,研究趋向于选用中间特征层 如何选择特征层,如何设计损失函数 训练学生模型数据集的选择 、学生模型的设计 、如何和其他压缩方法集成 紧凑网络设计。 如果要把模型压缩分为两部分的话,可以分为压缩已有的网络和构建新的小网络两种。其中剪枝、量化和低秩分解可以归到第一种,蒸馏归入第二种,而更好的方法就是在模型构建的初始阶段,就选择小而紧凑的网络,也就是紧凑网络设计。
2.4 网络量化
一般而言,神经网络模型的参数都是用的32bit长度的浮点型数表示,实际上不需要保留那么高的精度,可以通过量化,比如用0~255表示原来32个bit所表示的精度,通过牺牲精度来降低每一个权值所需要占用的空间。此外,SGD(Stochastic Gradient Descent)所需要的精度仅为6~8bit,因此合理的量化网络也可保证精度的情况下减小模型的存储体积。根据量化方法不同,大致可以分为二值量化,三值量化,多值量化对网络网络进行量化要解决三个基本问题。
目前深度学习中大部分都是用32bit float类型进行计算的,bit位数的多少直接限制了数据类型能够表达的数据范围,比如float32 的数据是由1 bit表示正负,8 bit表示整数部,23 bit表示分数部:

用更低位的数值类型意味着更小的数据表示范围和更稀疏的数值,量化的时候就会造成数值精度损失。比如要把float数值量化到int类型,那么首先小数部分就会丢失,而那些超过int类型范围的值也会被压缩到int能够表达的最大或最小值:
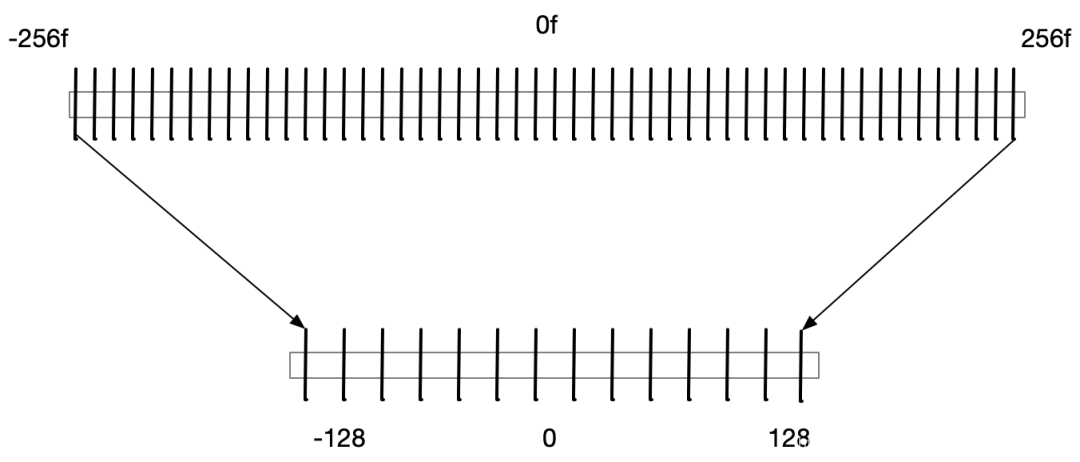
因此,模型压缩的关键是将float32 压缩到多少,目前主流的方式是压缩到int8 。压缩到int8 意味着内存节省的 ,同时提升了计算效率,因为在GPU这样的硬件上,低位的浮点计算速度会远远高于高位浮点计算速度。
压缩到int8的另外一个原因是,从概率分布角度看,int8的字符长度可以较完整的覆盖大部分的模型权重值。float32到float8的转变,只需要一个系数乘积将原有的小数部分变为整数(因为直接去掉了23位的小数部分)。
2.5 共享权重
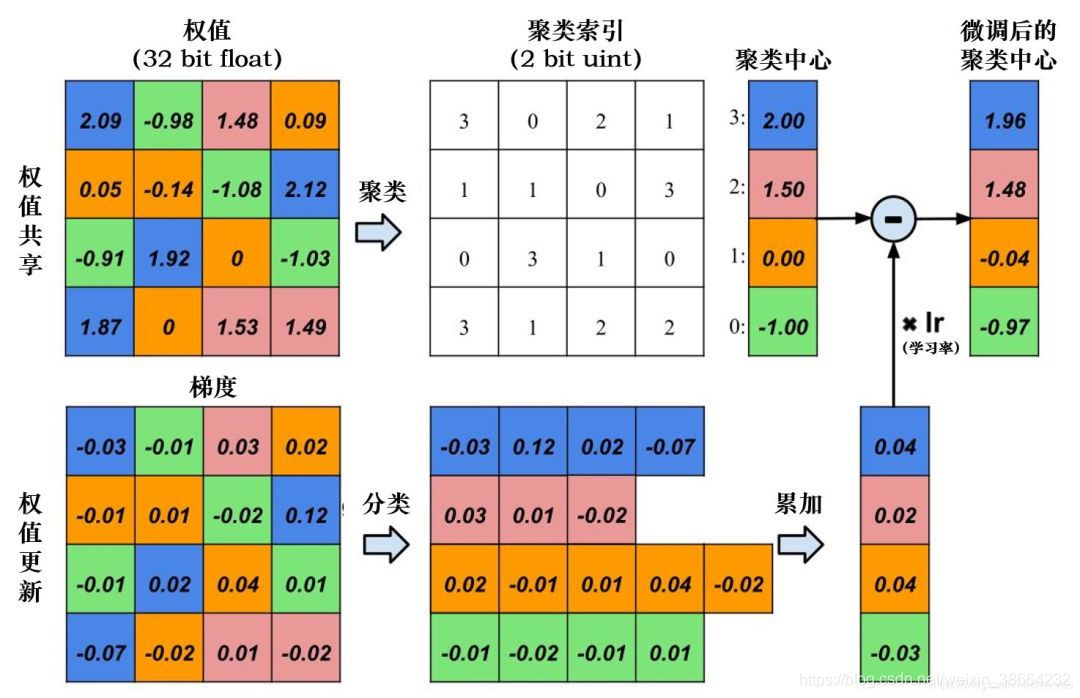
共享权重的概念指的是模型在构建的过程是否有些局部的信息在全局中是多次出现并重复使用的。如果可以通过聚类的方式挖掘出这些可以共享的权重系数,并且以类别的方式让他门共享一些权重,就可以实现模型的压缩。
例如卷积核中的部分权重是有共享关系的,可以将它们分为4类,然后针对类别去更新权重值即可:














 1873
1873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









