







一、梯度下降
梯度下降(GD)是最小化风险函数、损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面关于这两种方法进行讲解。是对于机器学习算法的模型参数,即无约束优化问题时,梯度下降时最常用的方法之一,另外一种常用的方法时最小二乘法。
1、梯度下降的符号解释
M 训练样本的数量
x 输入变量,又称特征
y 输出变量,又称目标
(x, y)训练样本,对应监督学习的输入和输出
 表示第i组的x
表示第i组的x
 表示第i组的y
表示第i组的y
h(x) 表示对应算法的函数
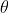 是算法中的重要参数(向量),是迭代要求解的值
是算法中的重要参数(向量),是迭代要求解的值
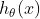 表示参数为的函数
表示参数为的函数
其中h(x)是要拟合的函数,J( )是损失函数,如下面公式所示:
)是损失函数,如下面公式所示:

2、梯度下降的直观解释
比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置的梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步一步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
当然,我们在进行梯度下降的时候不一定能够找到全局的最优解,很有可能时一个局部最优解。当然,如果损失函数是凸函数,梯度下降得到的解就一定是全局最优解。

图1 梯度下降方法的示例图
3、梯度下降的详细算法
梯度下降的算法可以有代数法和矩阵法(也称向量法)两种表示,代数法更容易理解,不过矩阵实现的逻辑更有合理性。
3.1 梯度下降的详细算法
1)先决条件:确认优化模型的假设函数和损失函数。
比如对于线性回归,假设函数表示为
二、批量梯度下降(Batch gradient descent)
https://www.cnblogs.com/pinard/p/5970503.html















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









