






点击下方卡片,关注“小白玩转Python”公众号
你有没有遇到过想要自动化的任务?例如,我们可能需要填写一些重复的在线表格。我们要么需要完成多个,要么需要定期完成。作为程序员,我们有自己的方法来处理这些需求。这就是Web自动化。在Python中,有很多库允许我们这样做,比如Scrapy,它帮助我们从网站抓取信息,还有可能是最著名的Selenium。Selenium使我们能够在网页上进行更多的交互动作。
然而,我发现了了一个更高级别的Web自动化库 —— Helium,它利用了Selenium使得自动化Web相关任务变得非常简单。
安装
要安装Helium,我们可以简单地运行以下pip命令。
pip install helium需要注意的是,Helium支持两种浏览器,Chrome和Firefox。因此,我们还需要确保我们的操作系统中安装了这些浏览器之一。使用Chrome或Firefox没有区别。所以,我将在本文中为了演示目的使用Chrome。
快速开始
正如前面提到的,Helium是我见过的最易于使用的Web自动化库之一。如果你曾经使用过其他库,比如Scrapy或Selenium,你应该记得它们在我们可以对这些元素做一些事情之前,需要相当复杂的逻辑来选择HTML元素。
Helium的创新之处在于,我们可以直接对HTML元素执行操作,而无需选择它们,只要它们有值。不是,让我们一起来看看这个。首先,让我们将Helium导入会话并启动一个Chrome浏览器实例。
import helium as hl
hl.start_chrome("www.google.com")正如你所见,当我们启动浏览器时,我们可以传递URL,以便浏览器可以打开这个网页。
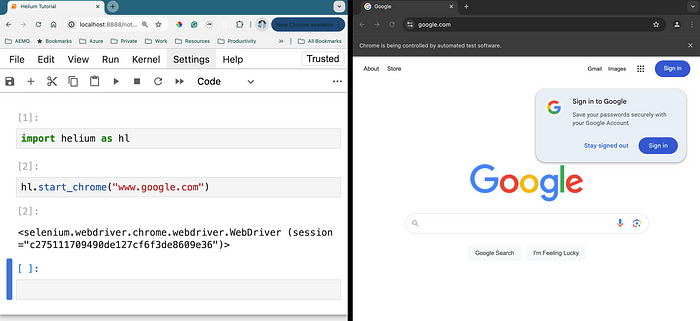
然后,我们可以直接写入搜索文本字段,因为谷歌在打开其首页时使其成为默认焦点。
hl.write('towards data science')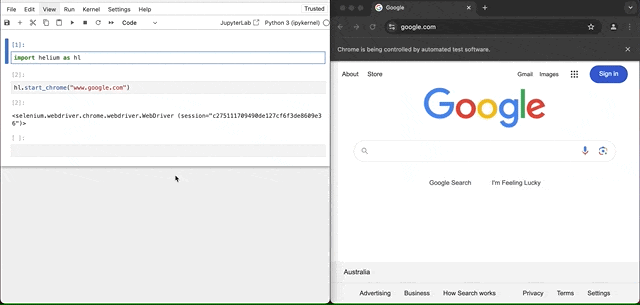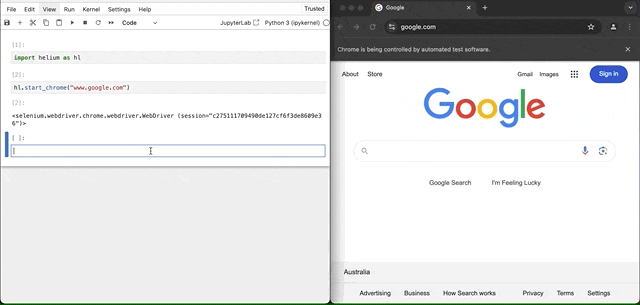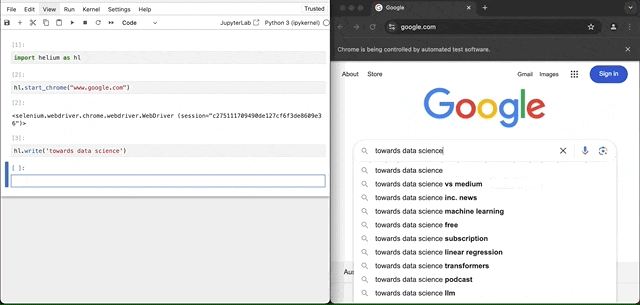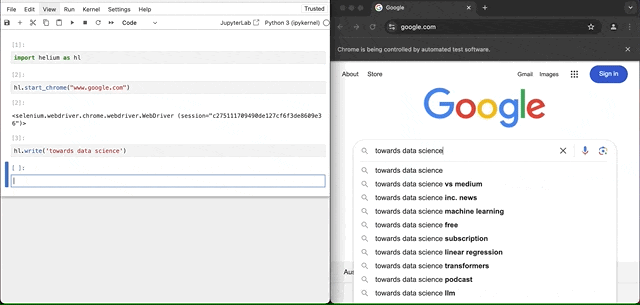
然后,让我们“按下”回车键。
hl.press(hl.ENTER)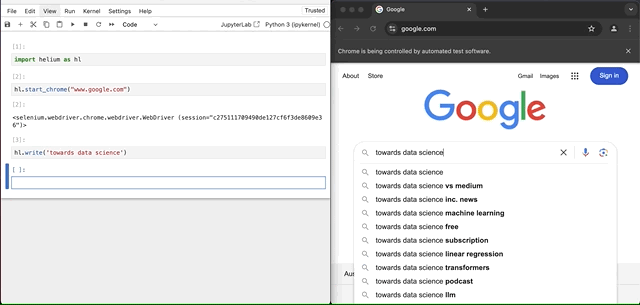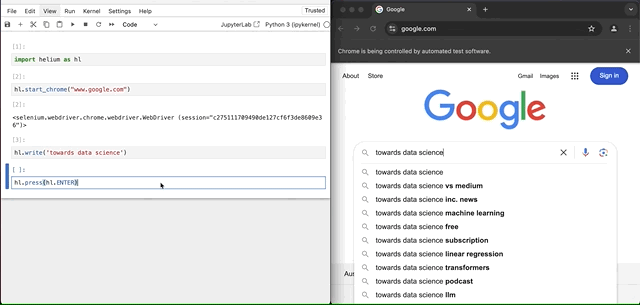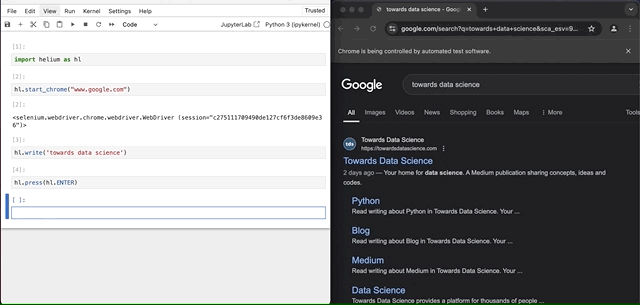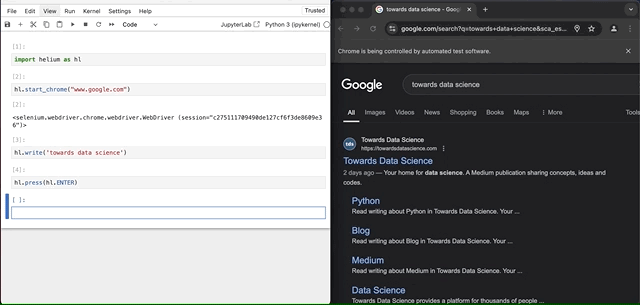
之后,这里有一个小把戏。如果我们想点击第一个链接,“Towards Data Science”,它实际上可能会点击搜索字段。这是因为按值匹配的原则只能找到第一个具有给定值的HTML元素。
因此,如果我们运行代码hl.click("Towards Data Science"),我们可能不会得到我们预期的结果。为了解决这个问题,我们可能需要使用一些其他技术。然而,让我们在这里保持简单。假设我们想点击搜索结果中“Towards Data Science”下的第一个链接。这要容易得多,因为它非常明确。
hl.click("Python")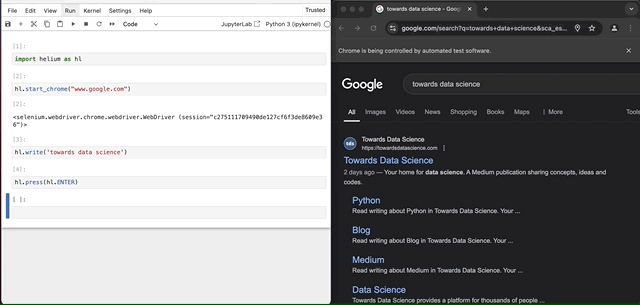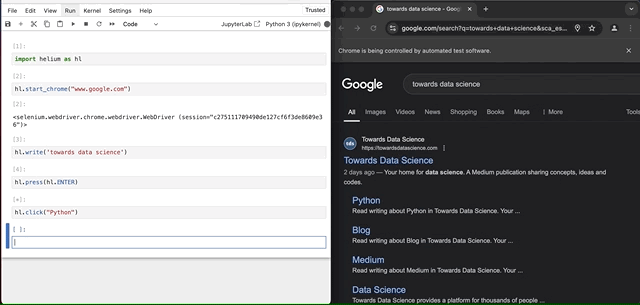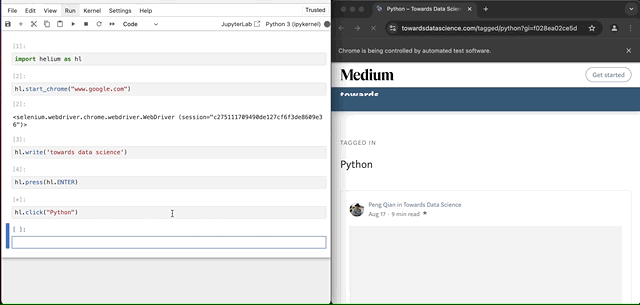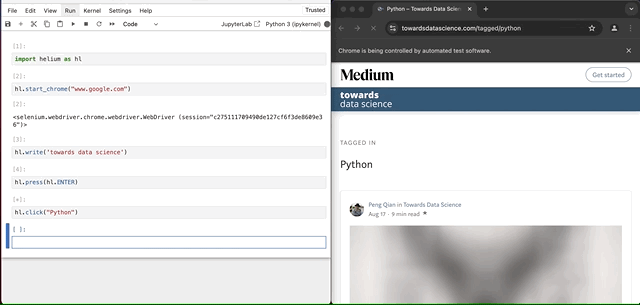
现在,让我们稍微滚动一下。我们可以指定滚动多少像素。在这种情况下,让我们做200像素。
hl.scroll_down(num_pixels=200)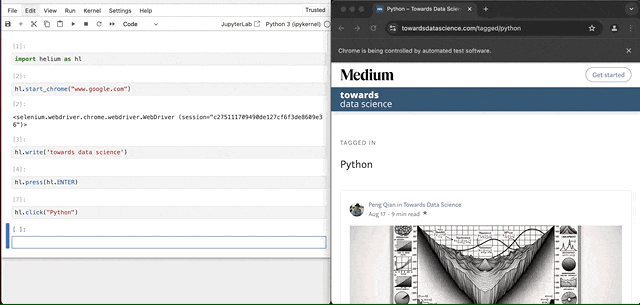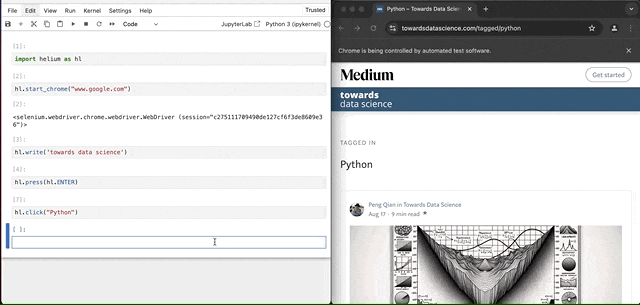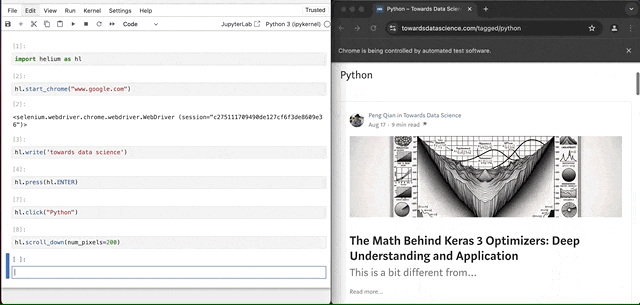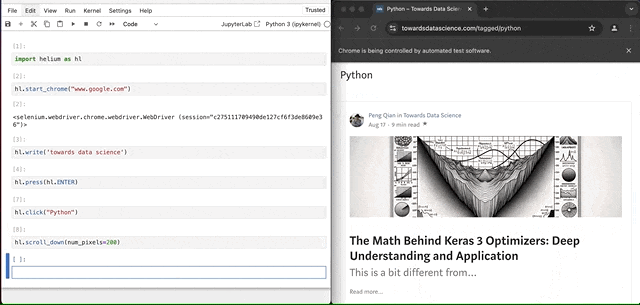
最后,不要忘记关闭浏览器以释放资源。同时,为了确保我们的自动化任务是可重复的,关闭浏览器并确保每次运行都是原子的和自包含的是一种好习惯。要做到这一点,我们只需要调用kill_browser()方法。
hl.kill_browser()
正如我们所看到的,使用这个库在网页上执行常见任务非常简单。除了演示的功能外,Helium还提供了更多开箱即用的功能,例如:
drag(element, to) 接受要拖动的HTML元素和目的地作为参数。
hover() 模拟鼠标悬停在元素上方
rightclick() 和 doubleclick()
drag_file(r"C:\Documents\notes.txt", to="Drop files here") 模拟将文件拖到HTML区域
attach_file(r"c:/test.txt", to="Please select a file...") 模拟附加文件
我相信,有了上述封装在函数中的常见操作,我们已经可以做很多事情了。然而,如果你仍然不满意,让我在后续部分介绍一些更多的技巧,这些技巧允许我们处理更复杂的情况。
使用XPath
 如果你熟悉HTML,我认为你一定知道XPath。如果你不知道,有很多资源和教程可以教你语法。基本上,它允许我们使用特定的字符串表达式来选择HTML元素。
如果你熟悉HTML,我认为你一定知道XPath。如果你不知道,有很多资源和教程可以教你语法。基本上,它允许我们使用特定的字符串表达式来选择HTML元素。
在上面的快速开始部分,我们假设谷歌搜索页面默认聚焦在搜索文本字段上。然而,如果,在其他一些场景中,情况并非如此呢?
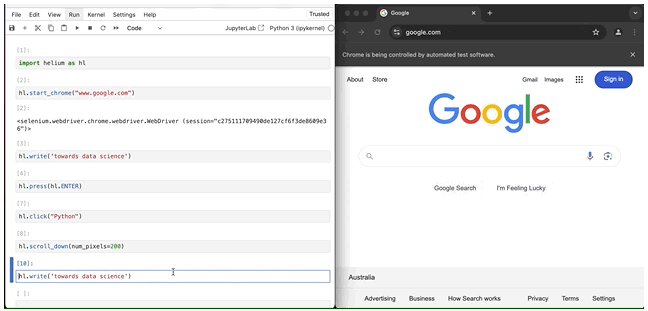
上面的截图显示,我故意点击了文本字段之外,以便失去焦点。然后,我回来运行hl.write()方法,它不再起作用了。
在这种情况下,我们可以使用XPath来明确告诉方法在哪里写文本。语法是使用方法hl.S("<XPath_Expression>")。
hl.write("towards data science", into=hl.S("//textarea[@title='Search']"))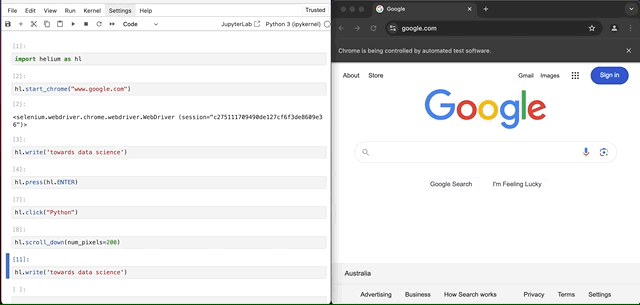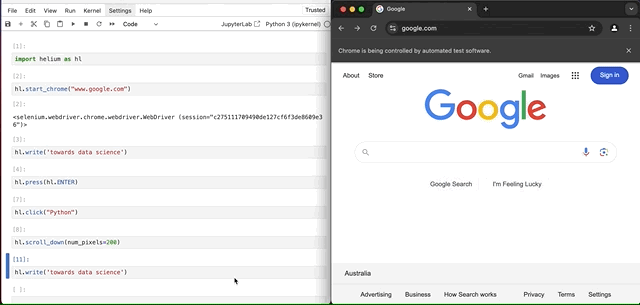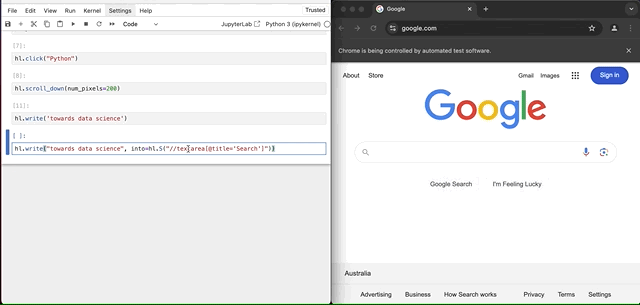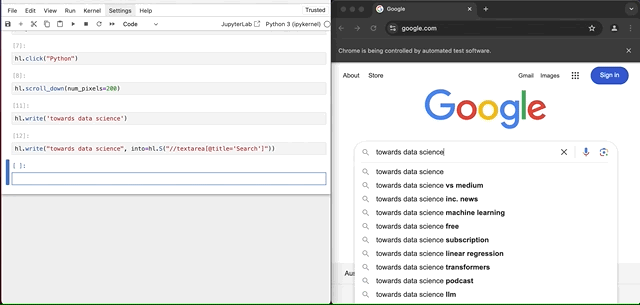
除了hl.write()方法,我们还可以在Helium中以许多其他方式使用XPath。例如,我们也可以使用方法hl.click(hl.S("<XPath_Expression>"))来点击某个HTML元素。
等待直到条件为真
另一个我非常喜欢的功能是“等待直到”。例如,有些网站在完全加载后可能会弹出一些窗口或模态视图。这通常很难捕捉,因为我们不知道它何时会发生。
让我们尝试一下。在下面的代码中,我们使用hl.go_to()方法返回谷歌搜索。然后,让我们等待网页上出现文本“Christopher Tao”。当然,我们可以利用搜索文本字段来做到这一点。一旦检测到文本,我们要求Python会话输出一些东西。
hl.go_to("www.google.com")
hl.wait_until(
hl.Text("Christopher Tao").exists,
timeout_secs=999
)
print("Christopher Tao input already!")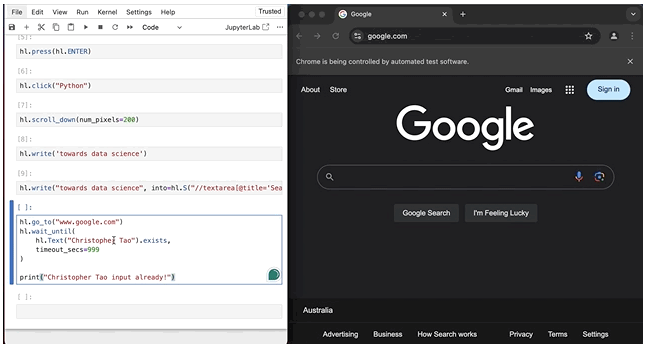
在上面的代码中,我设置了timeout_secs=999,以便我在搜索字段中输入我的名字。默认超时是10秒,所以如果需要,请记住重新配置。
总结
在本文中,我介绍了一个名为Helium的库。它可以帮助我们自动化Web相关任务。与其他大多数做同样事情的库不同,它可能是最容易使用的,因为它的高级包装函数和智能实现。
· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者删除















 5972
5972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









