







1)Rcnn 贡献:1)采用监督预训练方式(解决大量数据需求问题) 2)候选区域提出(解决计算量大的问题)
本质:将候选区域设定在backbone前,Resize后进行特征提取分类回归
第一步:RP选取:SS算法(无监督)
SS算法:1)使用Efficient Graph-Based Image Segmentation获取原始图片分割区域
2)根据各分割区域的颜色、小大、纹理、吻合等方面相似度合并分割区域
本质:层次化区域分割,即不断分割,按相似度合并区域,直到整图成为一个区域。
第二步:将候选区域缩放至227*227(缺点:缩放会使得物体变形),送入cnn中提取特征
第三步:区域分类+ 边框校准(对物体的大小,形状进行微调进行回归)
1)特征送入每一类的SVM分类器中(进行二分类判别)
2)对每一类目标,使用一个线性回归器回归(输入4096维特征,输出xy方向缩放和平移)
网络中预测时使用IOU>0.6,可以看出,网络重复计算量很大,
IOU:测量真实和预测之间的相关度,相关度越高,该值越高
缺点 1)每张建议框的ROI进行计算特征,计算量大
2)AlexNet需要227的输入,对RP ROI进行缩放时会让图片扭曲或不完整
优点:类别的扩充,不影响检测速度(由于使用了多个svm进行二分类)
原论文观点:
1)R-CNN是在推荐区域上进行操作,所以可以很自然地扩展到语义分割任务上
2)为了计算推荐区域的特征,首先需要将输入的图像数据转变成CNN可以接受的方式
3)缩放至227提供了四种方法:
1.建议框像周围像素扩充(同行变形),图像边界则用建议框像素均值填充
2.直接用建议框像素均值填充
3.resize
4.边界像素填充【padding】
注:关于全连接层对输入大小有要求的原因
全连接层的神经元设定之后是固定的,比如是M个(个数代表提取多少个特征),全连接层的参数和输入图像大小有关,因为它要把输入的所有像素点连接起来,需要指定输入层神经元个数和输出层神经元个数,如 X*W=Y(Y为全连接层) 矩阵的维度要对应,所以R-CNN的第二步在进入CNN前对图片进行crop/warp处理,就是为了卷积之后的特征数,能够和了全连接层的神经元个数相等
2)SPP-Net(Spatial Pyramid Pooling空间金字塔池化)
本质:定义一种可伸缩的池化层,不管输入分辨率是多大,都可以划分成m*n个部分
贡献:消除了resize和clip带来的信息丢失和物体变形的问题,提出了金字塔池化。

在最后一个卷积层后,接入金字塔池化层,使得任意大小的特征图都能够转换成固定大小的特征向量。
特点:不同尺寸的图像也可以产生固定的 输出维度,即沿着 金字塔的低端向顶端 一层一层做池化
a.第一层对这个特征图feature A整个特征图进行池化(池化又分为:最大池化,平均池化,随机池化),论文中使用的是最大池化,得到1个特征。
b.第二层先将这个特征图feature A切分为4个(20,30)的小的特征图,后使用对应的大小的池化核对其进行池化得到4个特征。
c.第三层先将这个特征图feature A切分为16个(10,15)的小的特征图,后使用对应大小的池化核对其进行池化得到16个特征。
4.将这1+4+16=21个特征输入到全连接层,进行权重计算.
方法:将reponse map分成1x1(金字塔底座),2x2(金字塔中间),4x4(金字塔顶座)三张子图,分别做max pooling后,输出特征一定是(16+4+1) 长度为21的一维向量。
原理:每个网格提取一个维度特征,将特征进行维度划分,致使输出特征向量长度仅仅与网格数量有关.
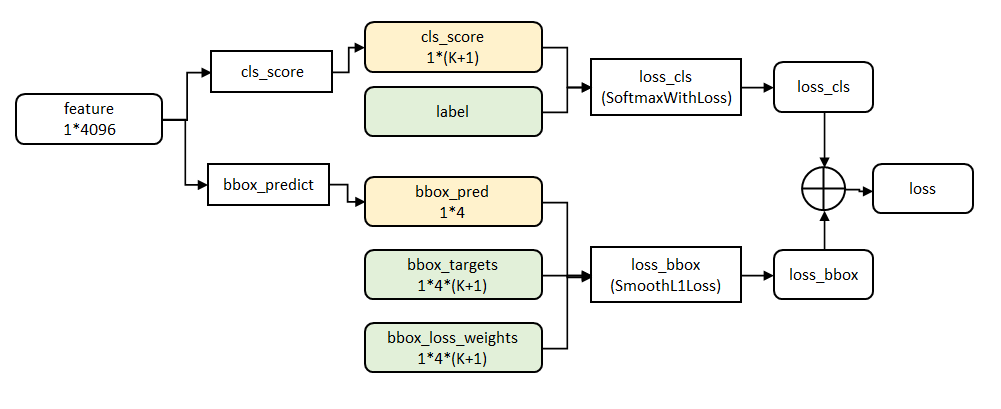
3). Fast RCNN
本质:将候选区别使用在con5后(VGG16),Roi pooling后,进行分类和 回归
贡献 1)ROI pooling 进行同维度输出(简化spp net为单尺度)
2)multi-task loss 进行分类,回归统一训练(softmax 分类,两个任务进行卷积共享),解决了多步骤问题
3)smooth L1 loss(光滑损失函数提出,能够避免对于偏移较大的点致使梯度剧增,增加模型的鲁棒性)
4)Truncated SVD(将一个大全连接层,分解为两个小的全连接层)
3)smooth L1 loss:

4)Truncated SVDSVD
利用SVD分解,将O(uv)——>O(t(u+v))
第一步:SS选取RP
第二步:一次性特征提取,将RP映射到最后一层卷积特征图上(CNN)(类似SPP,但只有7*7网络,下采样得到49*512特征)
第三步:ROI pooling 将RP下一层 ROI的特征图大小进行统一,送入
第四步: 输入到并行两个全连接层中(multi-task ),使用了多任务损失函数(multi-task loss )
4. Faster RCNN
本质:
贡献:1)用RPN提取RP (且RPN产生RP和目标检测的卷积层共享) ,候选区域网络(RPN)将第一个卷积网络的输出特征图作为输入。它在特征图上滑动一个 3×3 的卷积核,以使用卷积网络构建与类别无关的候选区域
2)能够实现端到端的训练(两种模式:1.交替式训练 2.端到端训练)
1)一次性特征提取(CNN)
2)用RPN生成建议窗口(RP)(每张图片生成300个建议窗口)
3)将RP映射到最后一层卷积特征图上
4)ROI pooling 将RP ROI的特征图大小进行统一,送入下一层
5)输入到并行两个全连接层中(multi-task ),使用了多任务损失函数(multi-task loss )
RPN:
RPN的贡献: 1)Anchor Box的提出(9中尺度)
2)对每个建议窗口进行分类(背景与非背景二分类)
6.SSD
贡献:1)单阶段
2)全卷积网络,用大小不同特征图来获取检测信息(多尺度特征图检测,大特征图检测小物体)
3)Default box,每组特征图上只考虑一个尺度的默认框。(1:1,1:2,1:3,1:1/2,1:1/3)
细节:
1)需要预测c+1个置信度值(c个类别置信度+背景或非背景的评分)
2)强制正负比不超过1:3
3)数据增强策略:保证正例能被选上。
优点:
1)原文采用了数据增强(随机剪裁,翻转)
2)多尺度检测,在基础网络的conv4_3进行检测,底层网络的特征图信息完整,感受野小,适合小物体检测
3)原文中,使用了瘦高和扁宽的默认框(更符合数据集)
4)使用atrous卷积(解决了卷积过程中,为了特征图尺度不变,加入padding时引入噪声的问题)
从代码看本质:
本质讲,神经网络对图片操作 就好比将一张纸,进行升维后,设定目标,进行降维聚类过程。
目标体现: 损失函数
降维聚类体现: 会强制令其最后一层网络输出为损失函数的输入要求
例如: 7分类, 常最后连接 fc(7)
4坐标回归,常连接 conv(4)

有图可得,ssd算法有三个分支,
分类分支(每个像素点的框数( 这里作者默认4——6个)*类别数)
默认框分支(每个像素点的框数*4) 输出:
锚点分支(每个像素点的框数*8 (xmin ymin xmax ymax)和对应的四个variance)) 输出: (batch, height, width, n_boxes, 8)`
其中框数代码如下: 可得每个像素预测框 在各层为[4, 6, 6, 6, 4, 4]
aspect_ratios_per_layer=[[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5]]
two_boxes_for_ar1=True
n_predictor_layers = 6
aspect_ratios_global=[]
if aspect_ratios_per_layer:
n_boxes = []
for ar in aspect_ratios_per_layer:
if (1 in ar) & two_boxes_for_ar1:
n_boxes.append(len(ar) + 1) # +1 for the second box for aspect ratio 1
else:
n_boxes.append(len(ar))
else: # If only a global aspect ratio list was passed, then the number of boxes is the same for each predictor layer
if (1 in aspect_ratios_global) & two_boxes_for_ar1:
n_boxes = len(aspect_ratios_global) + 1
else:
n_boxes = len(aspect_ratios_global)
n_boxes = [n_boxes] * n_predictor_layers
print('11111111111')
print(n_boxes)
[4, 6, 6, 6, 4, 4]
一方面为了后面各个层提取的特征能够concat起来,也是为了后面计算softmax,我们需要把类别单独提取出来作为单独的axis,以conv4_3为例:

最后先Reshape 为(B,W*H*n_boxes, classes) #这里的n_boxes 近似于 C*n_boxes (即每个维度特征图拥有n_boxes个框)
最后 Cancat 一起训练:

因此,此处特征图大小 为 38*38 一直到 1*1
上代码:
'''
A Keras port of the original Caffe SSD300 network.
Copyright (C) 2018 Pierluigi Ferrari
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
'''
from __future__ import division
import numpy as np
from keras.models import Model
from keras.layers import Input, Lambda, Activation, Conv2D, MaxPooling2D, ZeroPadding2D, Reshape, Concatenate
from keras.regularizers import l2
import keras.backend as K
from keras_layers.keras_layer_AnchorBoxes import AnchorBoxes
from keras_layers.keras_layer_L2Normalization import L2Normalization
from keras_layers.keras_layer_DecodeDetections import DecodeDetections
from keras_layers.keras_layer_DecodeDetectionsFast import DecodeDetectionsFast
def ssd_300(image_size,
n_classes,
mode='training',
l2_regularization=0.0005,
min_scale=None,
max_scale=None,
scales=None,
aspect_ratios_global=None,
aspect_ratios_per_layer=[[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5, 3.0, 1.0/3.0],
[1.0, 2.0, 0.5],
[1.0, 2.0, 0.5]],
two_boxes_for_ar1=True,
steps=[8, 16, 32, 64, 100, 300],
offsets=None,
clip_boxes=False,
variances=[0.1, 0.1, 0.2, 0.2],
coords='centroids',
normalize_coords=True,
subtract_mean=[123, 117, 104],
divide_by_stddev=None,
swap_channels=[2, 1, 0],
confidence_thresh=0.01,
iou_threshold=0.45,
top_k=200,
nms_max_output_size=400,
return_predictor_sizes=False):
'''
Build a Keras model with SSD300 architecture, see references.
The base network is a reduced atrous VGG-16, extended  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1271
1271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









