






01
背景与现状
1、广告领域数据特点
广告领域数据可以分成:连续值特征和离散值特征。不同于 AI 图像、视频、语音等领域,广告领域内的原始数据大多以 ID 形式呈现,比如用户 ID、广告 ID、与用户交互的广告 ID 序列等,而且 ID 规模较大,形成了广告领域数据高维稀疏的鲜明特点。
连续值特征
既有静态的(比如用户的年龄),也有基于用户行为的动态特征(比如用户点击某行业广告的次数)。
优点是具备良好的泛化能力。一个用户对行业的偏好可以泛化到对这个行业有相同统计特性的其他用户身上。
不足是缺乏记忆能力导致区分度不高。比如两个相同统计特性的用户,可能行为上也会存在显著差别。另外,连续值特征还需要大量的人工特征工程。
离散值特征
离散值特征是细粒度的特征。有可枚举的(如用户性别、行业ID ),也有高维的(如用户ID 、广告ID )。
优点就是记忆性强、区分度高。还可以对离散值特征进行特征组合,用于学习交叉、协同信息。
缺点是泛化能力相对较弱。
广告是一个要求对于用户强记忆,对于媒体流量强区分的场景,因此,离散值特征是广告模型个性化预估优化的基础。广告 ID 、用户 ID 、以及其组合等高维稀疏数据都可以作为离散值特征使用,这样的话不同的用户有不同的行为就可以在特征上有很好的区分。一般来说,离散值特征的使用方式包括两种:
独热编码( One-hot Encoding )
特征嵌入( Embedding )
对于高维离散值特征进行独热编码极容易导致“维度灾难”,表现为参数爆炸、模型收敛慢、泛化能力弱的明显缺陷。因此,其适用于离散值有限可枚举类型下的编码,对于大规模 ID 的编码基本通过特征嵌入的方式,将高维空间下的稀疏 ID 在低维稠密空间进行向量表达。
2、爱奇艺广告排序模型现状
2016 年,谷歌提出的 Wide & Deep 模型正式把深度学习模型引入到推荐领域,Wide & Deep 模型实现了对记忆和泛化能力的统一建模,迅速成为工业界搜索、广告、推荐领域的 baseline 模型。爱奇艺广告排序业务也于 2019 年陆续从 online-learning FM 模型演进为 DNN 模型。
我们的 DNN 模型基于开源框架 TensorFlow 训练和推理。在 TensorFlow 框架中,全部以稠密 Tensor 为基本数据单元对数据进行计算、存储以及传输。用于存储离散值 ID 特征 Embedding 的 Tensor shape 需事先确定,即固定为 [ vocabulary_size , embedding_dimension ],vocabulary_size 需要人工根据 ID 空间决定。因此在引入高维稀疏 ID 特征时,我们首先将 ID 特征 Hash 映射到 vocabulary_size 范围内。
目前我们在使用高维稀疏 ID 特征时存在如下问题:
特征冲突:若 vocabulary_size 设置过大,训练效率会急剧下降且会由于内存 OOM 导致训练失败。因此即使对于亿级别的用户 ID 离散值特征,我们也仅会设置 10 万量级的 ID Hash 空间,Hash 冲突率较高,特征信息受损,离线评估无正向收益。
低效的 IO :由于用户 ID 、广告 ID 等特征是高维稀疏的,即一段时间内训练更新的参数只占总量很少的一部分,在 TensorFlow 原有静态 Embedding 机制下,模型存取需要处理整个稠密 Tensor,这会带来极大的 IO 开销,无法支持稀疏大模型的训练。
02
广告稀疏大模型实践
如上文所述,离散值特征是模型实现个性化预估更进一步的基础,我们在使用高维稀疏 ID 离散值特征时也遇到了问题。因此我们在 2023 年采用业界主流开源技术开展稀疏大模型的训练和推理的建设。
1、算法框架
过去几年,业界在 TensorFlow 支持推荐稀疏大模型方面进行了大量探索且已在真实商业场景落地。我们选择 TFRA动态 Embedding 开源组件,主要有如下原因:
TFRA API 兼容 Tensorflow 生态(复用原有优化器和初始化器,API 同名且行为一致),使 TensorFlow 能够以更原生的方式支持 ID 类稀疏大模型的训练和推理;学习及使用成本低,不改变算法工程师建模习惯。
内存动态伸缩,训练更省资源;有效避免Hash 冲突,保证特征信息无损。
我们基于 TensorFlow 2.6.0 和 TFRA 0.6.0 框架,先后进行了如下迭代:
静态 Embedding 升级到动态 Embedding :下线对于离散值特征的人工 Hash 逻辑,使用 TFRA 动态Embedding 对参数进行存储、访问和更新,从而在算法框架上保证所有离散值特征的 Embedding 无冲突,保证所有离散值特征的无损学习。
高维稀疏 ID 特征的使用:如上文所述,使用 TensorFlow 静态 Embedding 功能时,用户 ID 、广告 ID 特征由于 Hash 冲突,离线评估无收益。算法框架升级后,重新引入用户 ID、广告 ID 特征,离线及线上均有正向收益。
高维稀疏组合 ID 特征的使用:引入用户 ID 与广告粗粒度 ID 的组合离散值特征,比如用户 ID 分别与行业 ID 、App 包名的组合。同时结合特征准入功能,引入使用更稀疏的用户 ID 与广告 ID 的组合离散特征。
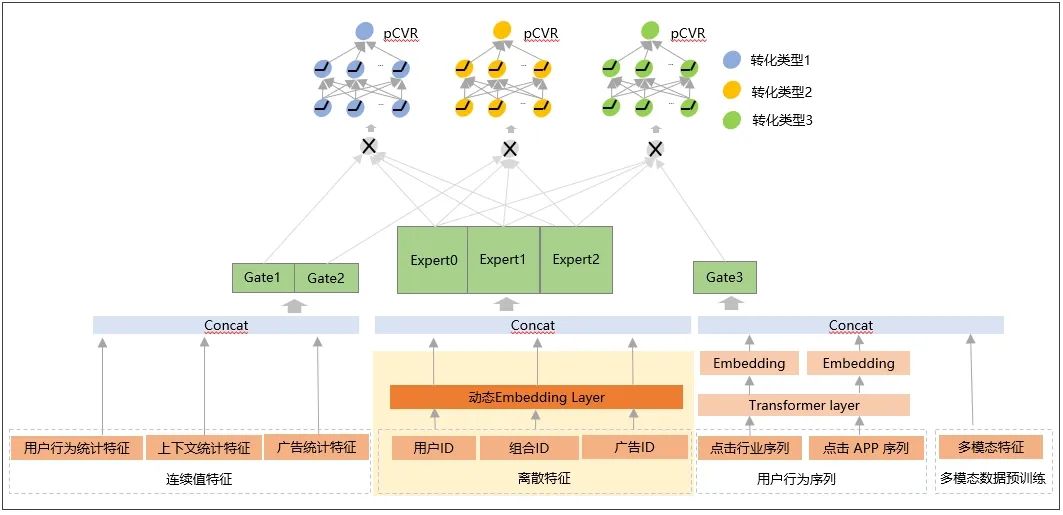
2、模型更新
我们在稀疏大模型落地过程中,遇到了很多训练推理和部署更新的问题。针对落地过程中的各问题进行了深度的分析优化,最终实现了稀疏大模型高效稳定地训练推理和部署更新。
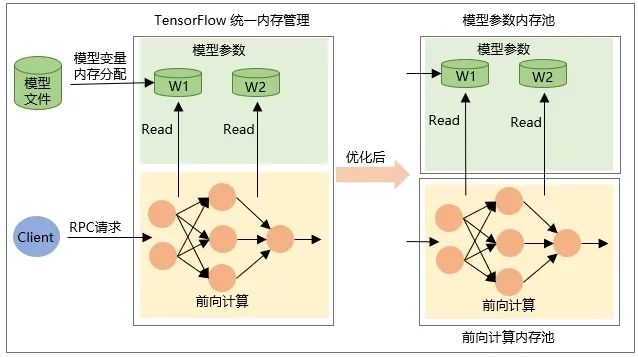
使用 TensorFlow Serving 热更新稀疏大模型时会由于内存分配和释放的竞争导致推理延迟。TensorFlow 内存分配和释放的使用场景主要有两个部分:
模型 Restore 时变量本身 Tensor 的分配,即加载模型时分配内存,卸载模型时释放内存。
RPC 请求时网络前向计算时中间输出 Tensor 的内存分配,在请求处理结束后被释放。
因此在稀疏大模型更新时,新模型加载时的 Restore OP 有大量的内存被分配,旧模型被卸载时有大量内存被释放。而这个过程中,RPC 推理请求没有中断,这个时候两者的内存分配和释放会产生冲突和竞争关系,导致推理毛刺。基于以上分析,通过设计内存分配隔离,将模型参数的内存分配和 RPC 请求的内存分配隔离开来,让它们在不同的独立内存空间进行分配和释放,从而解决了稀疏大模型热更新时的延时毛刺问题。
最后,采用稀疏大模型文件分片和同机房内 P2P 传输的形式进行模型分发,减少对存储后台和网络专线的压力,解决了稀疏大模型频繁更新导致的存储和带宽问题。
03
总体收益
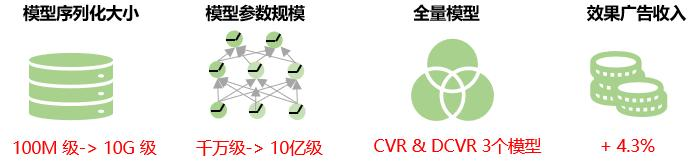
目前深度学习平台已高效稳定地支持 10 亿级参数模型的训练推理和部署更新。我们在效果广告 CVR 和 DCVR 场景已有 3 个稀疏大模型全量上线,在推理延时基本持平的情况下,直接驱动效果广告业务收入提升 4.3%。
04
未来展望
目前广告稀疏大模型中同一特征的所有特征值赋予了相同的 Embedding 维度。实际业务中,高维特征的数据分布极不均匀,极少量高频特征占比极高,长尾现象严重;所有特征值使用固定的 Embedding 维度会降低 Embedding 表示学习的能力。即对于低频特征,Embedding 维度过大,模型有过拟合的风险;对于高频特征,由于有丰富的信息需要表示学习,Embedding 维度过小,模型有欠拟合的风险。因此后续我们会探索自适应地学习特征 Embedding 维度的方法,进一步提升模型预估的精度。
同时我们会探索模型增量导出的方案,即仅将增量训练时产生变化的参数加载到 TensorFlow Serving,从而降低模型更新时的网络传输和加载耗时,实现稀疏大模型的分钟级更新,提高模型的实时性。

也许你还想看
















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









