






导语:
爱奇艺作为网络视频播放平台,其核心服务是播放用户选择的视频内容。VRS(Video Relay Service)是公司所有平台播放功能的入口服务,它的主要功能包括播放策略控制(播控)、码流选择和下发视频文件地址等。VRS 系统的正常运行直接关系到爱奇艺的正常使用,因此对故障发生和故障时长的容忍度极低。在业务迭代过程中,保障并不断提高VRS系统的高可用、容灾和故障恢复能力一直是VRS团队最重要的工作内容和最大挑战。本文首先概述了VRS的系统架构,然后从系统部署、存储设计、重试机制、系统韧性、监控巡检和能力验证等方面介绍了 VRS 系统在高可用性和容灾能力建设方面的探索与实践。
01
VRS系统概述
爱奇艺所有客户端在播放视频或切换码流时,都需要调用 VRS 系统的 HTTP 接口(/dash,后统称 dash 接口或入口服务)。该接口根据视频 ID 返回播放器所需的音视频码流、码流文件地址、字幕地址等数据。同时,VRS 系统在处理播放请求时,还会根据既定规则对播控、用户视频和码流权益进行判断。总体来看,见图 1-1,VRS 系统是爱奇艺视频播放的入口和枢纽服务。
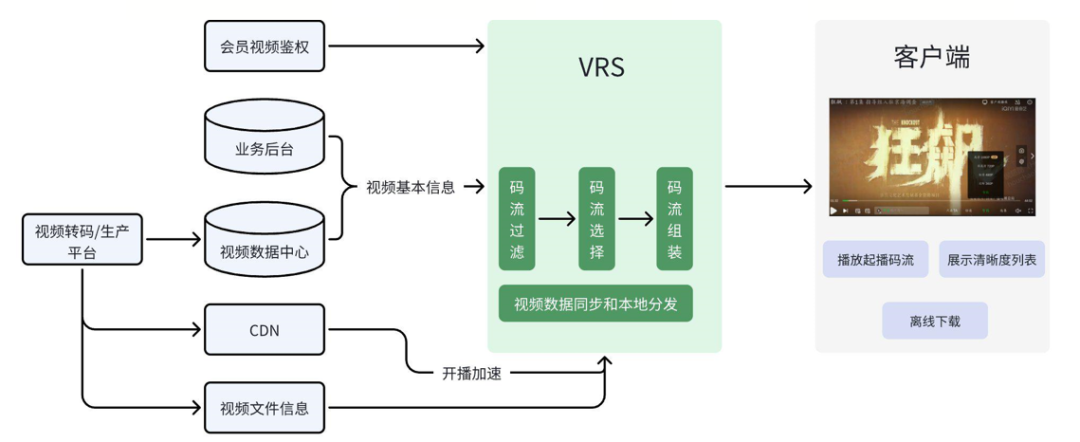
图1-1 VRS系统在爱奇艺视频播放链路中
的位置示意图
而当VRS系统无法正常提供服务时,将直接阻断用户对爱奇艺最核心服务的使用。几分钟的故障就可能造成极大的负面舆论,继而损害公司的声誉和利益。因此,VRS系统在系统设计和业务迭代中,永远将稳定和高可用性放在首位。同时,对故障的高敏感性使其在应对各种故障时的快速恢复能力极其重要。
如表1-1所示,VRS系统的特点决定了它对各项系统能力的要求优先级不尽相同。
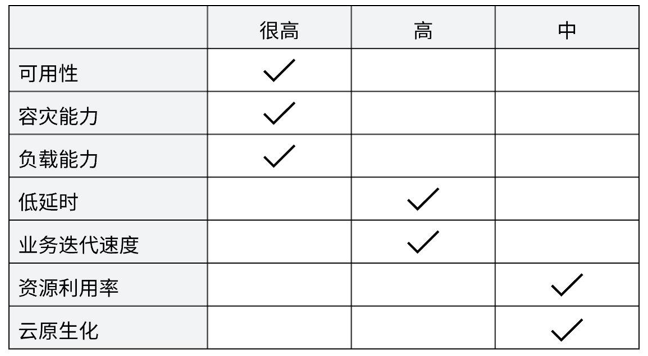
表1-1 VRS系统能力要求
本文将从系统部署、存储架构、重试机制、系统韧性、监控巡检和能力验证六个方面,介绍VRS在系统容灾能力建设方面的探索与实践。
02
系统部署
基于对高可用性、容灾能力和负载能力的需要和数据中心资源规划,VRS系统采用两地三中心、容器与虚拟机混合、公私有云混合的部署方案。
异地多活:两地三中心
在所有可预见的灾难中,地域(Region)级别的灾难对系统可用性的挑战最大,其次是AZ或机房级别的故障。两地三中心是应对此类问题的优解方案。如图2-1所示,VRS系统的两地包含Region1和Region2两个Region,三中心则是Region1 AZ1,Region1 AZ2和Region2 AZ。
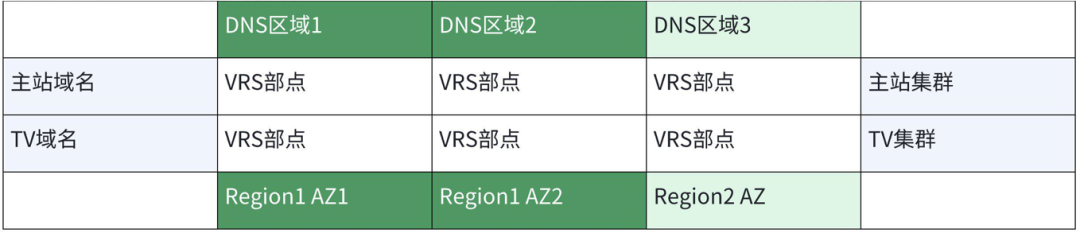
图2-1 VRS两地三中心部署示意图
VRS的两地三中心方案具体实施方案包括:
每个AZ均可自活且提供完整服务能力;
每个AZ的容量均可支撑全站峰值流量;
每个地域支持所有运营商入口,每个AZ尽量支持所有运营商入口;
通过播放全链路专项治理,推进并已完成依赖的上下游服务对齐部署方案及容量;
持久化数据同步(自研KV存储HiKV,MySQL,MongoDB)主要依赖数据库的两地三中心方案,个别无成熟集群方案的存储介质(Couchbase)通过多写实现数据同步。
灾备方案:AZ或地域级别的故障,网关正常时在网关层(七层负载均衡服务/API网关)实现流量切换,网关同时故障时在DNS层实现流量切换。如图2-2所示,是VRS系统使用七层负载均衡服务时的灾备方案。
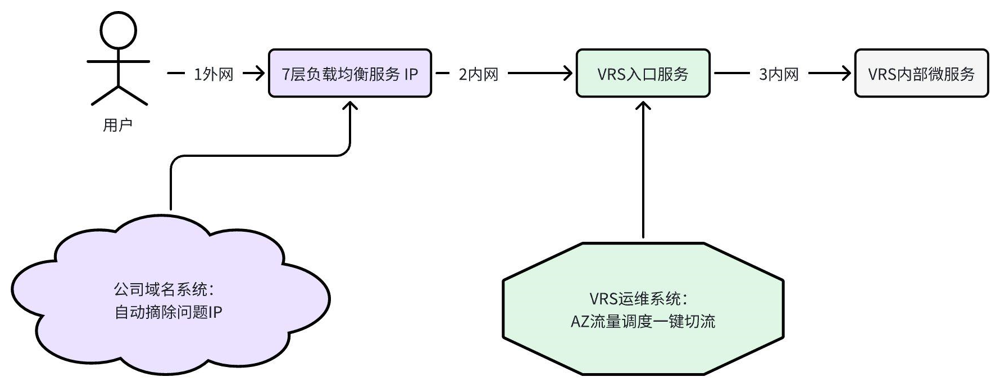
图2-2 VRS系统两地三中心灾备方案
底层异构:虚拟机与容器混合部署
同大多数服务一样,服务容器化也是VRS系统的既定方向。在演进过程中,虽然已经完成了容器化需要的服务改造,具备了全量容器化的技术条件,但出于需要保留虚拟机的现实必要性考虑,VRS系统当前还处于容器与虚拟机混合部署的阶段。混合部署条件下,需要具备在虚拟机和容器集群间流量灵活切换的能力。如图2-3所示,VRS系统通过在网关层(七层负载均衡服务和API网关)实现虚机或者容器集群的流量调度,并以此作为虚机或者容器集群故障时的灾备方案。
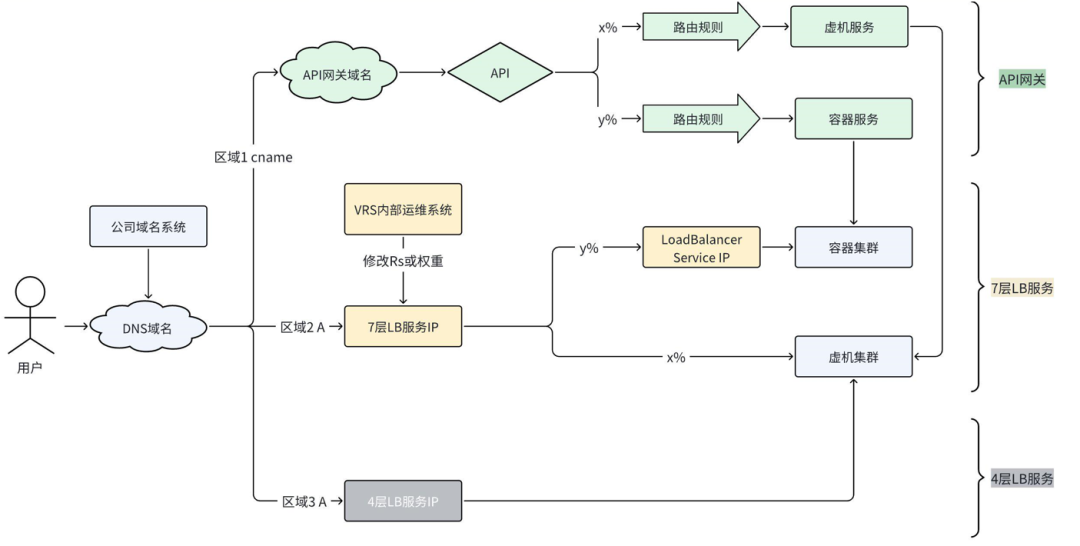
图2-3 VRS系统虚机和容器混合部署下
的网关方案示意图
多云混合:公私有云混合部署
如前所述,VRS对系统容量的要求很高,在重保期如春节或重大活动时更是如此。当前公司计算资源整体规划已开始使用公有云,当需要大量资源时,多云混合部署,有利于资源快速调配和交付。最开始引入新的云环境时,因为没有经过长期线上使用的验证,新使用的云环境稳定性存在不确定性。因此,VRS系统在最开始做多云混合部署时,也同时设计了应对单云故障时的流量切换预案。
VRS系统私有云公有云混合部署的具体落地方案包括:
对于在同AZ下已经做了单元化部署和流量调度的层级,如VRS入口服务(Dash)层,私有云和公有云单独部署不同单元;
对于AZ内部署为1个单元,暂不支持同AZ内多单元流量调度的微服务模块,通过实现健康检查接口状态云配的方式,支持对指定云环境的所有服务实例强制上下线;
制定单云故障预案,并将预案操作白屏化。
图2-4展示了VRS系统混合云部署和切流预案示意图。
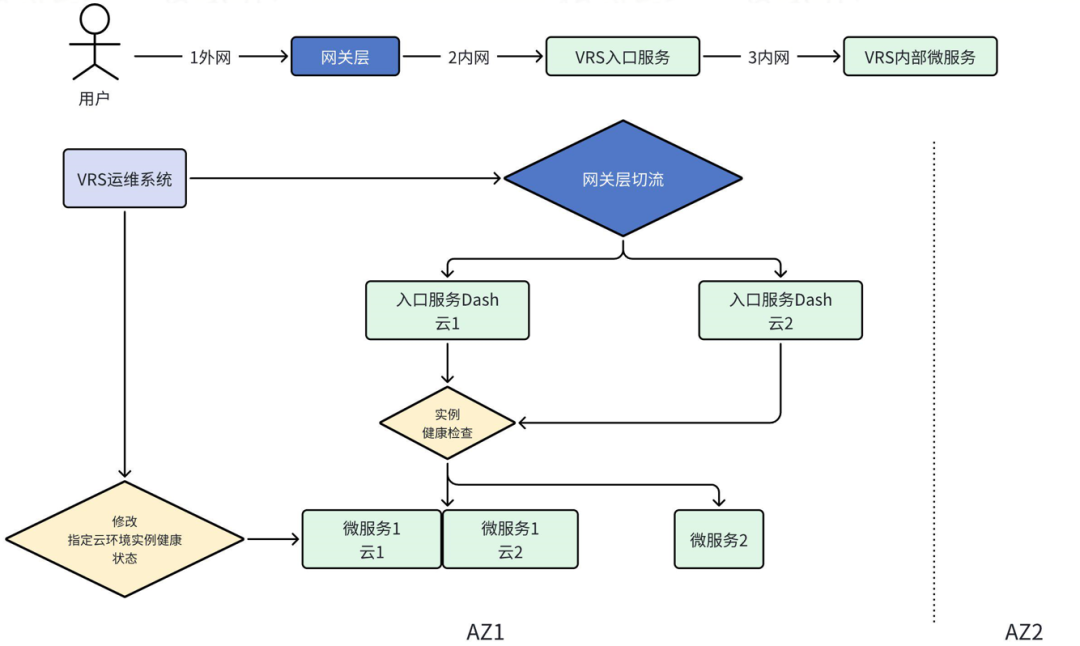
图2-4 VRS系统混合云部署和切流预案示意图
03
存储架构
数据库存储的异常是最常见的引发系统故障的原因之一。为应对此类故障,VRS系统在存储架构上做了以下工作:
多层缓存:避免极高并发请求对底层存储服务的冲击,同时提高响应速度;
异构互备:包括缓存的每层存储,除了Hikv是同Region内,其它存储介质在同AZ内都选择了异构的存储介质作为冷备使用;
图3-1以视频信息数据为例,展示了多层缓存和存储介质的异构互备是VRS系统对数据库存储灾备的主要手段,其中Hikv为内部自研KV存储。
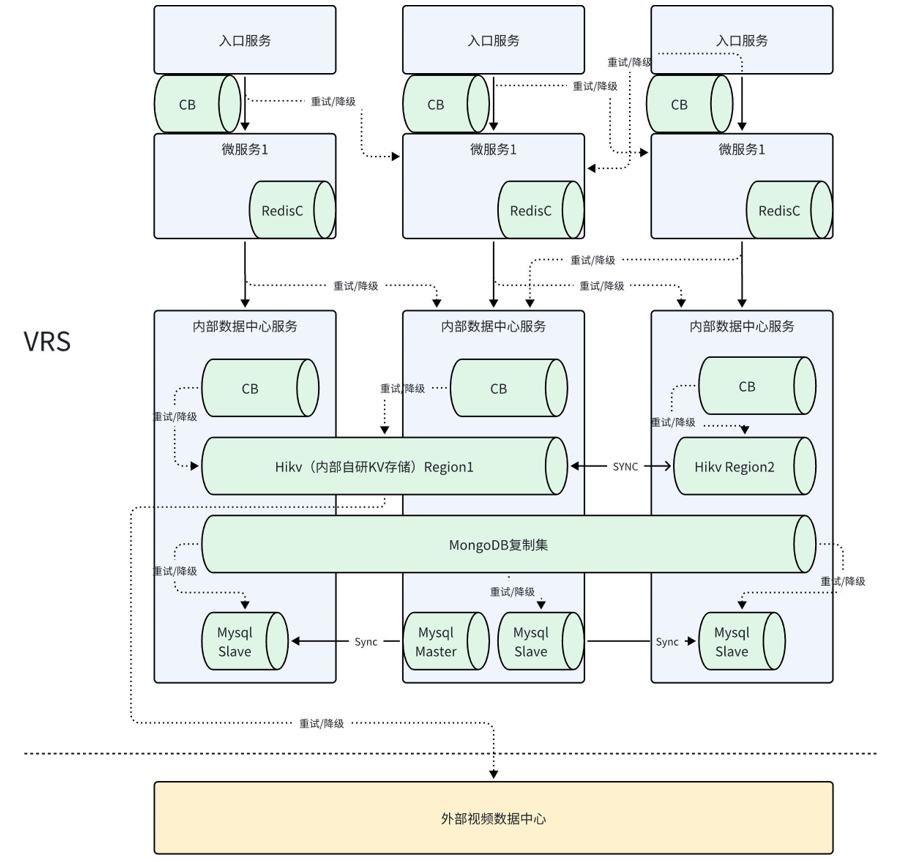
图3-1 VRS系统中视频信息数据存储架构
04
重试机制
在应对机房或地域类故障时,网关层的流量切换大多需要人工介入,即使有预案,处理的时效性也会较差。访问异常时的重试机制是保障服务可用性的重要手段。VRS系统服务类异常的重试机制可以分为两种:系统内微服务间的跨AZ重试机制和VRS系统的retry域名重试机制。
服务端重试:微服务间的跨AZ重试
如果某个微服务在请求上游服务时失败,会自动重试请求到邻近AZ的该上游服务。如图4-1所示为VRS系统内的微服务间的跨AZ重试示意,Dash服务作为系统入口,在处理用户请求时,当调用某个上游微服务时,请求的超时、异常状态码或者响应内容非法,都会被认为请求失败。失败后Dash会根据预先的配置,重试到该上游服务的邻近AZ。当发生大量异常时,触发熔断直接访问邻近AZ的上游服务,直至本AZ上游服务恢复。
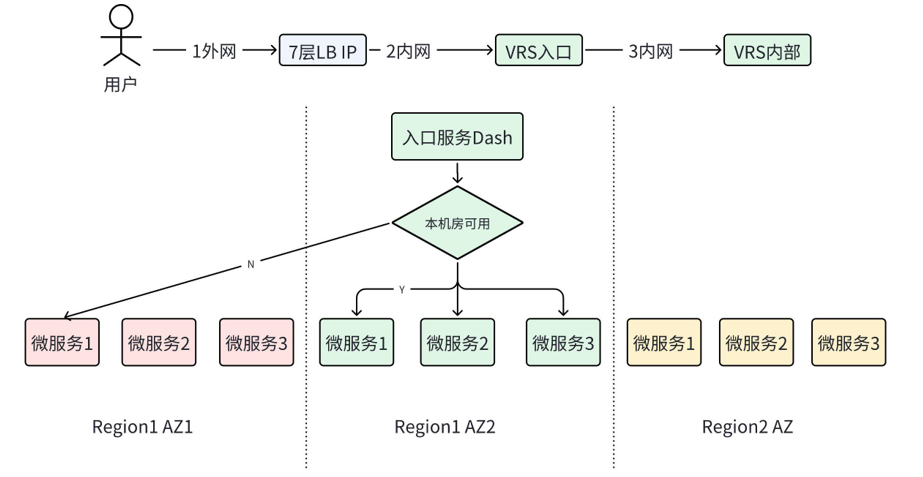
图4-1 VRS系统内微服务间的
跨AZ重试机制示意图
客户端重试:Retry域名重试机制
VRS系统的Retry域名,是一个DNS配置与主域名不同的独立域名。Retry域名DNS配置的原则是,相同区域用户分别请求主域名和Retry域名时,能够访问到不同AZ的VRS系统。如VRS系统主域名区域A中配置的是AZ1的负载均衡服务IP,用户通过该主域名访问时会访问到AZ1部署的VRS系统。而Retry域名在区域A中配置的是AZ2的负载均衡服务IP,同一区域用户访问Retry域名时,则会请求到AZ2部署的VRS系统中。因此,通过Retry域名,可以实现客户端请求的跨AZ重试。
VRS系统的Retry域名重试机制即是通过与客户端约定,当服务端响应内容中明确指示客户端本次请求需要进行重试时,客户端会通过retry域名重新发起请求。所以是否重试以及重试的条件完全是由服务端控制的,可以达到灵活配置和变更。如图4-2,展示了VRS系统的Retry域名重试机制中的重试流程。
需要说明的是,该重试机制是为了解决VRS系统应用层的异常和故障设计的,并非网络连通性的问题(如DNS劫持、弱网、负载均衡服务ip不可达等),在客户端访问VRS系统时对后者的应对,依赖于公司系统网络提供的QTP(Qiyi Transfer Protocol)网络库的容灾能力。QTP网络库依托其自研的FastDNS、超级管道等技术,通过缓存、重试、代理等手段,改进和应对诸如弱网环境、DNS劫持异常状况下网络请求的表现,最终使请求能够到达VRS系统。
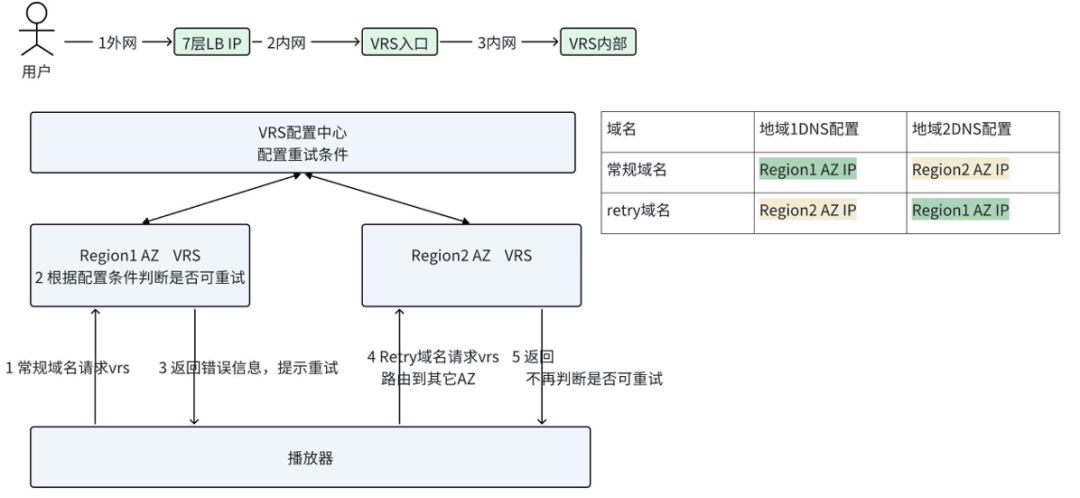
图4-2 VRS系统retry域名重试机制示意图
05
系统韧性
作为对应公司主要业务的核心系统,即使做了相当的系统容量冗余,但是线上系统实际流量超出系统容量上限的可能性依然存在,且该时刻往往是公司业务的高光时刻(比如爱奇艺的一部新剧热播,刷新历史最高热度新纪录时)。VRS系统主要通过保护和降级两种手段,来提高流量过载情况下的系统韧性。
系统保护
限流是系统保护的最常见且重要的手段,通过限流,可以避免流量过载情况下系统整体崩溃带来的服务完全不可用。VRS系统对各个微服务分别进行了单机限流。在实施中,单机限流的有效性主要取决于两个因素:限流的维度和限流的阈值。限流维度方面,除了常见的QPS和线程维度的限流,考虑到VRS主要性能瓶颈是CPU,同时不同请求对资源消耗不同这一特点,VRS同时增加了CPU利用率维度的限流。三个维度指标,每一个维度达到预设置的阈值均会触发请求被拒绝,以此来保证单机不会因为过载出现崩溃,进而保护系统。另外,每个维度合理且与线上流量匹配的上限阈值同样至关重要。VRS系统对各个微服务分别进行了基于线上流量拷贝的单机性能压测,以获取其在极限性能下前述三个限流维度的上限值,最终基于该值设置一个在保证稳定和避免资源浪费之间平衡的阈值。
VRS进行系统保护另一个手段是流量分级治理,即按照重要性对流量进行划分并进行独立管理。例如,除了用户主动触发的播放请求,VRS系统流量中也有相当一部分请求是产品层面为了提高用户体验或者技术层面做性能优化而产生的,这部分流量并不会阻塞用户在爱奇艺应用上的播放功能,因此其重要性和优先级要低于用户主动触发的请求。图5-1展示了VRS系统通过网关参数调度能力,实现的对预加载和自动播放请求独立管理的示意图。通过对流量进行分级治理,系统能够具备对以下异常情况的处理能力:
保障服务过载时的用户体验。当系统将要或已经出现过载,同时因不可预测原因资源无法满足扩容需求时,可以将低优先级流量调度到别的单元,以此达到高优先级流量能够拥有足够资源处理的目的。而低优先级流量即使因过载而被限流,不会阻塞用户功能,用户几乎无感。
降低系统变更风险。系统新代码上线、配置修改、架构调整等变更,先对低优先级流量处理单元进行灰度,以降低变更潜在风险发生时对用户的影响。
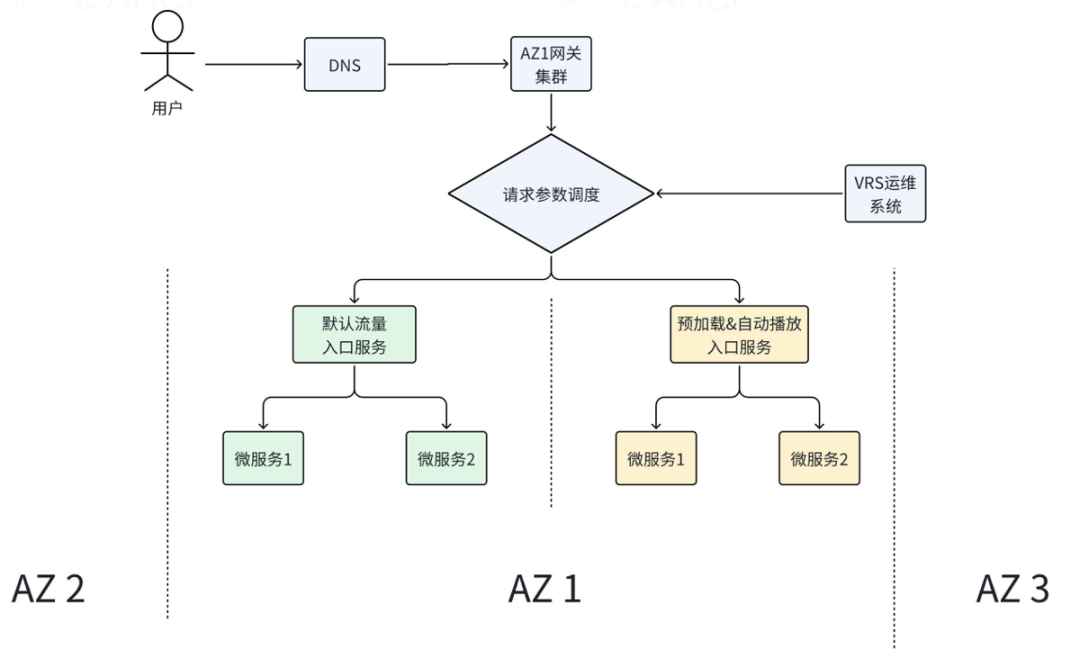
图5-1 VRS流量分级治理流程示意图
功能降级
系统保护的工作是基础,在此之后,还需要对溢出流量尽量妥善处理,避免简单的提示用户“稍后重试”而已。VRS系统通过构建功能降级体系来应对该问题。与重试机制功能无损不同的是,降级体系对业务完整的播放特性是有损的,目的是为了保证基础的播放能力。如在VRS中,DRM(Digital rights management)作为一个内部加密流微服务,是为了增强视频介质安全的,以此增加盗播的难度和追溯盗播源。高质量码流和部分重要视频内容的播放请求正常情况下都需要通过DRM加密流微服务来实现。当DRM加密流微服务因为不可预测的原因服务不可用且短时间无法恢复时,需要有相应手段降级处理,保证用户的播放权益。如图5-2中降级手段1所示,DRM加密流微服务不可用时,VRS系统会降级使用清流微服务进行清流播放。
同时,VRS系统搭建了一个基础播放能力Java异构系统,作为降级体系中重要也是最终一环。异构系统具有低频发版、清流预生产和单机性能高的特性。如图5-2降级手段2所示,当清流微服务出现问题,或者Dash入口服务模块有问题时,可以通过降级到异构系统,达到满足用户基本播放需求的目的。
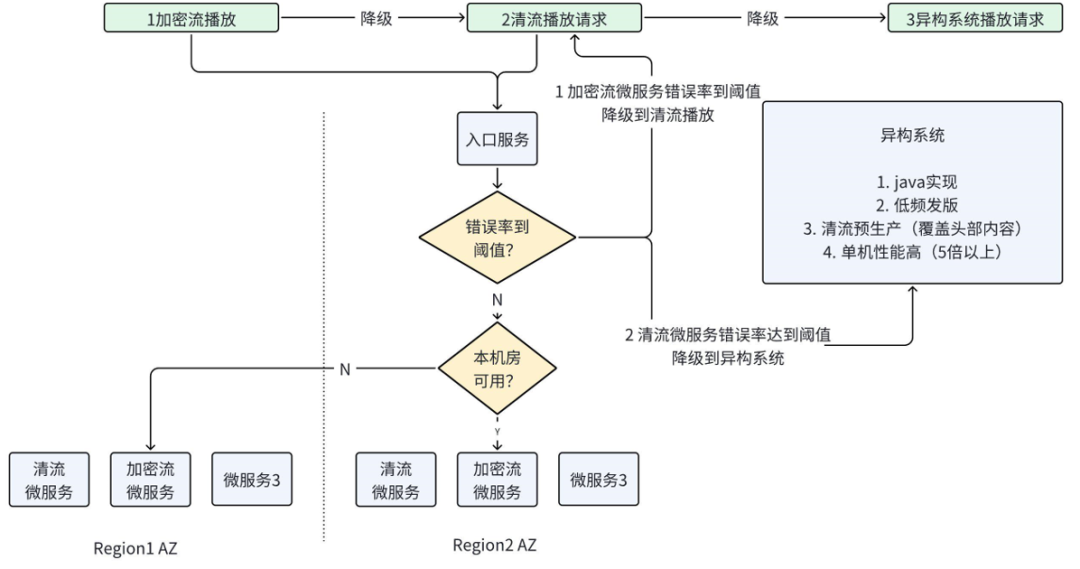
图5-2 VRS播放请求降级链路
06
监控巡查
监控报警
在VRS的灾备体系建设中,虽然已经构建了大量的自愈化机制,但是完善的监控体系打造,也是不可缺少的。
VRS的监控体系,大体分为:基础监控,服务监控,外部依赖监控和功能监控四个部分。其中:
基础监控是指CPU使用率、内存占用率、网络带宽和代码版本等对应到各计算节点的监控项。
服务监控是指QPS、请求错误率和响应延时等对应到各服务的监控项。
外部依赖监控是指对VRS系统外的其他服务的调用情况监控,同样包括QPS、请求错误率和响应延时等项目。
功能监控是指面向产品功能的监控项,在VRS系统内,有播放时长占比、自动播放占比和下沉播放占比等。
以上的各项监控,均按照不同的阈值对应到相应级别的报警,报警发生时,通过IM消息或者电话等方式通知到值班人员。
系统巡检
重大故障发生前,往往存在多个预警信号或小的故障。这些较小事故如果得到妥善处理,可以预防严重的事故发生。基于海因里希法则的精神,我们构建了系统巡检体系,以便值班同事在监控项触发报警之前,更早的发现可能的风险。
巡检页面包括:VRS全局的状态查询页面,及对应各监控项的当前状态查询页面。并协同播放链路的其他环节的系统团队,构建了爱奇艺播放链路的监控大盘及对应状态查询页面。
07
能力验证
VRS系统分别通过全链路压测和混沌工程来实现对系统负载和灾备能力的验证。
全链路压测
全链路压测对于验证系统在设计负载能力下的服务表现至关重要,对VRS这种重要性和负载能力要求都很高的系统来说更是如此。VRS在设计和实施全链路压测过程主要挑战和解决方式包括:
压测词表的构建。词表是生成最终压测请求的基础。VRS系统压测的词表,是通过大量线上真实请求日志,抽取出影响系统表现的各类参数值(如视频id,用户),以此为基础,最终生成符合真实线上分布的词表和满足特定要求(比如超长视频)的词表。
发压能力。VRS系统借助公司基于Hadoop/Spark构建的分布式压测平台,并协调了闲时大量的计算资源,最终具备了超高并发的发压能力。
外部服务依赖的能力匹配。在项目层面通过成立播放链路治理专项,协调播放链路相关各方,定期沟通同步压测事项,最终共同完成了包括部署对齐、容量匹配、上下游监控等各项工作。
对线上环境可控的影响。通过在架构上隔离网络环境、在方案上制定压测预案的方式,做到对线上环境可控的影响。如图7-1所示为VRS全链路外网压测的网络方案。
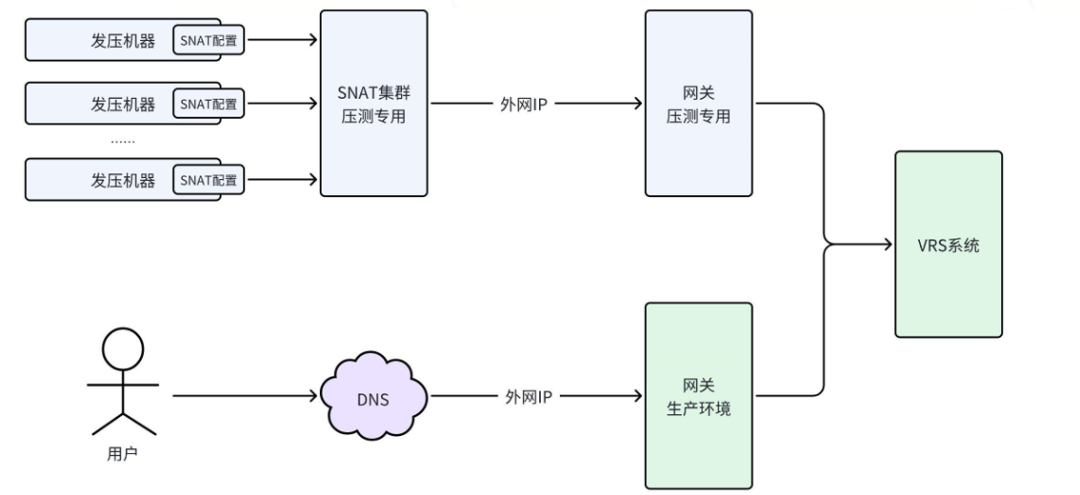
图7-1 VRS全链路外网压测网络方案示意图
全链路压测的极限条件对系统的挑战非常大,也因此对验证系统的容量规划、服务限流、上下游依赖表现很有说服力。同时在压测的有限时间内,VRS系统还设计注入了一些特定场景的故障,部分验证了极限流量场景情况下系统的灾备表现。
混沌工程
混沌工程演练对保持系统在不停迭代更新背景下灾备能力的有效性具有重要意义。VRS系统会定期基于公司混沌工程系统进行攻防演练,以验证已有灾备能力和发现系统薄弱环节。VRS系统通常进行的演练项目包括:
数据库和中间件攻击,以此验证存储架构方面的灾备能力。
外部依赖故障,来验证服务间调用的重试和熔断能力。
机房灾备切流,验证系统在应对AZ级别故障时服务表现。
突发流量攻击,验证了单机限流能力。
08
总结和展望
VRS系统在爱奇艺播放链路中的定位,决定了它最重要的系统能力要求:稳定高可用。本文通过对VRS系统在部署方案、存储架构、重试机制、系统韧性、监控巡检和能力验证六个方面工作的总结,描述了其依据自身业务特点,在灾备能力建设方面的具体实践。当然,系统建设没有通用完美的方案,经得住线上考验的才是最适合的。
在下一阶段,VRS系统会继续在性能提升,基于API网关的流量分级治理,基于云原生化和单元化的多活架构,基础播放能力Java异构系统优化,反盗播等方面继续发力,做到稳定可靠安全的同时,高效支持爱奇艺用户的高品质观影体验。


















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









