






01
背景
互联网风控是一个高对抗的领域,黑产为了攫取高额利益会持续不断尝试突破风控体系,而风控体系中,特征数据是核心要素。特征生产的速度,直接决定了黑产对抗的效果。
风控特征通常是基于风险刻画沉淀的介质数据 (list) 或基于用户行为的累计数据 (velocity) 。举个例子,虚拟手机号名单,就是有「虚拟手机号」风险的手机号列表,而某个设备 ID 一小时内登录次数,就是基于用户登录行为的累计数据。风控特征会在风控规则及模型中使用,对于每一笔业务请求,风控规则和模型会基于特征数据和风险刻画的量化进行风险决策,最终决定是拦截还是通过。
爱奇艺业务风控团队从 2018 年起,陆续建设了离线特征平台(奇数)和实时特征平台(奇流海)两套系统,基于大数据 Spark 和 Flink 分别构建了离线特征生产、实时特征生产以及业务层特征运营能力,但随着风险运营迭代,两套平台的运营效率瓶颈逐渐凸显且特征计算延迟问题频发,造成多起黑产风险漏放案件。
因此,风控团队从 2023 年 Q2 起开始建设新一代的风控特征平台 RiskFactor,在爱奇艺 Opal 机器学习平台特征中心的基础上进行了流批一体化改造,合并取代了奇数、奇流海两个旧平台,新平台将特征生产提速了 15 倍,为黑产攻防赢得主动性,提升了业务风控的止损增收效果。
02
旧特征平台痛点
实时特征计算延迟高: 定制的模板化配置方式和手动分配运行资源,导致奇流海资源调度不合理,频繁出现 IO 阻塞,部分实时特征生产延迟高达 6 小时。
离线特征生产故障风险高: 在离线大数据平台上开发数据任务后再通过 SDK 写入特征平台,导致特征配置和特征计算跨平台,无法及时感知任务启停状态变更、管理任务代码,出现过多次故障,影响风控策略效果。
特征配置冗余:部分复杂特征需要同时配置实时特征和离线特征,在策略中采用多窗口组合的方式来使用,此时需要在奇数、奇流海平台上分别配置、分别生产,运营效率低下,且存储计算冗余。
03
新特征平台方案
新平台的目标是统一实时特征和离线特征的表达范式,实现特征生产速度的极大提升。核心设计要点如下:
简化特征配置:以 DAG + SQL 的形式提供,DAG 赋予开发者灵活的链路编排能力,SQL 则可以统一流批开发语义,降低开发门槛;
统一特征生产与管理:我们对接了爱奇艺 Opal 机器学习平台上的特征中心,Opal 为我们提供了特征流批一体调度生产、特征查询 SDK 等功能;
特征生产提速:通过多重优化策略,如下沉链路异步拆分、运行时任务自动合并、长窗口累计指标拓扑优化进行等;
高可用:研发特征发布版本化控制和统一发布管理,提升特征任务的资源效率、产出效能及运行稳定性。
以下是整体架构:
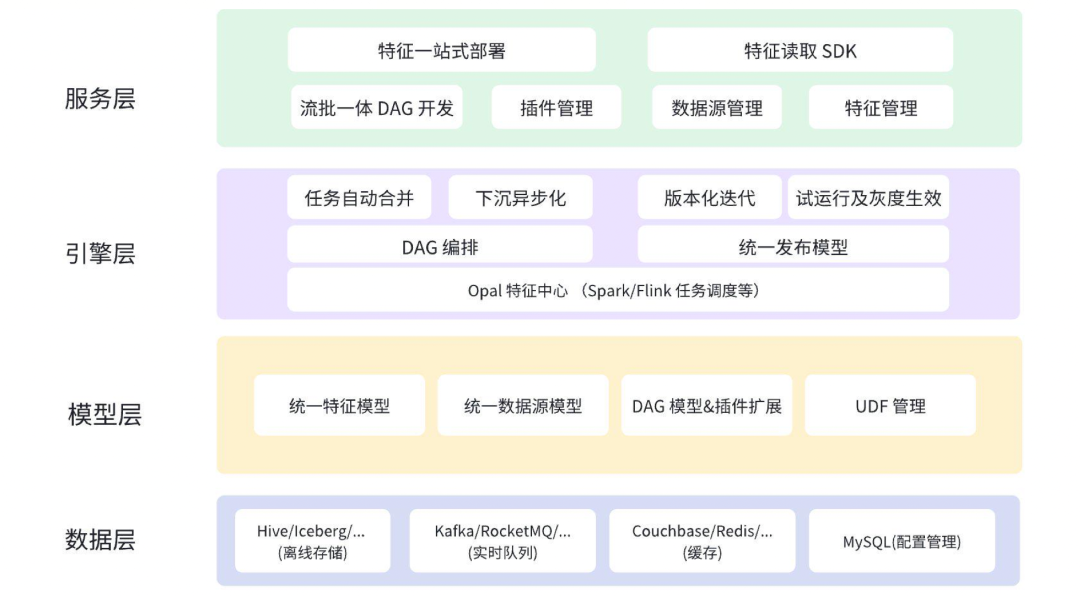
04
新特征平台核心增益
一体化开发运营
流批一体开发语义
通过 DAG + SQL 的模式,我们对流特征和批特征在开发语义上实现了统一。在数据源接入层和特征下沉层我们进行了 DAG 节点抽象,用户可以便捷地设定数据的来源与目标特征存储,而无需关注底层细节。中间的计算逻辑,则通过标准化的 SQL 计算节点来表达,这样不论是批量处理还是实时流处理任务,都能利用统一且熟悉的 SQL 语言来完成,降低了学习成本,提升了开发效率。
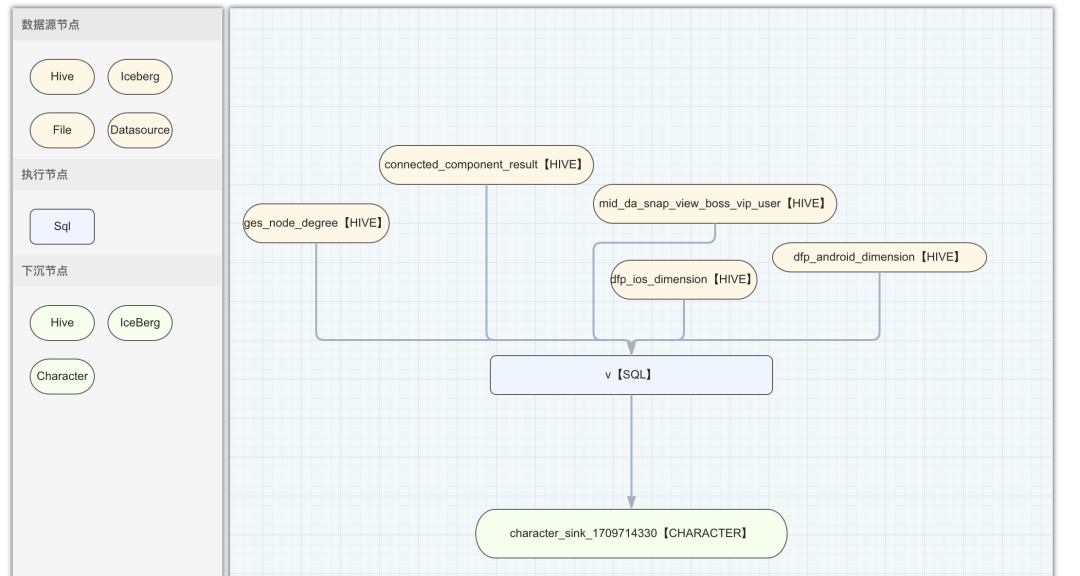
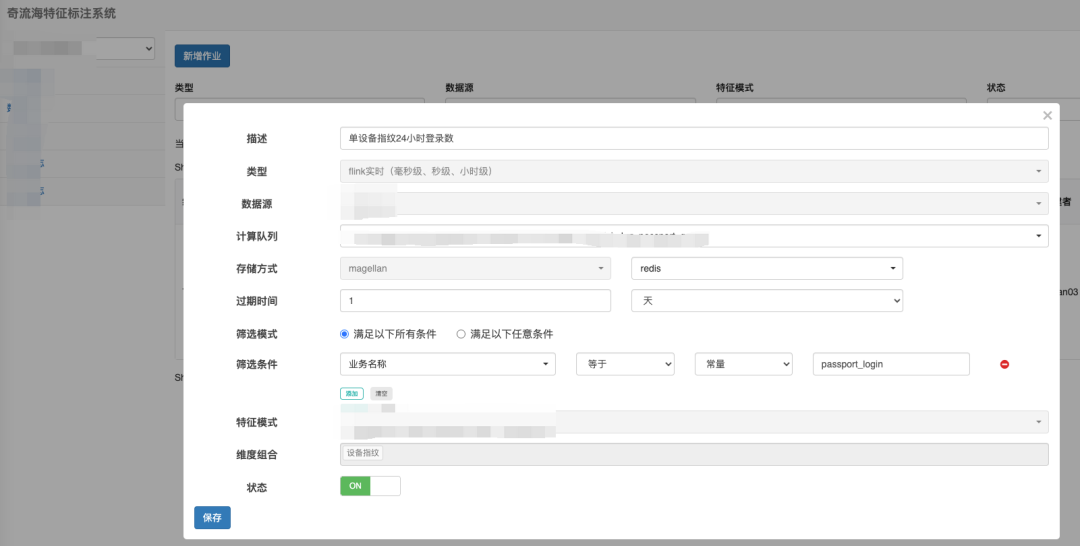
离线特征生产任务配置:
实时特征生产任务配置:
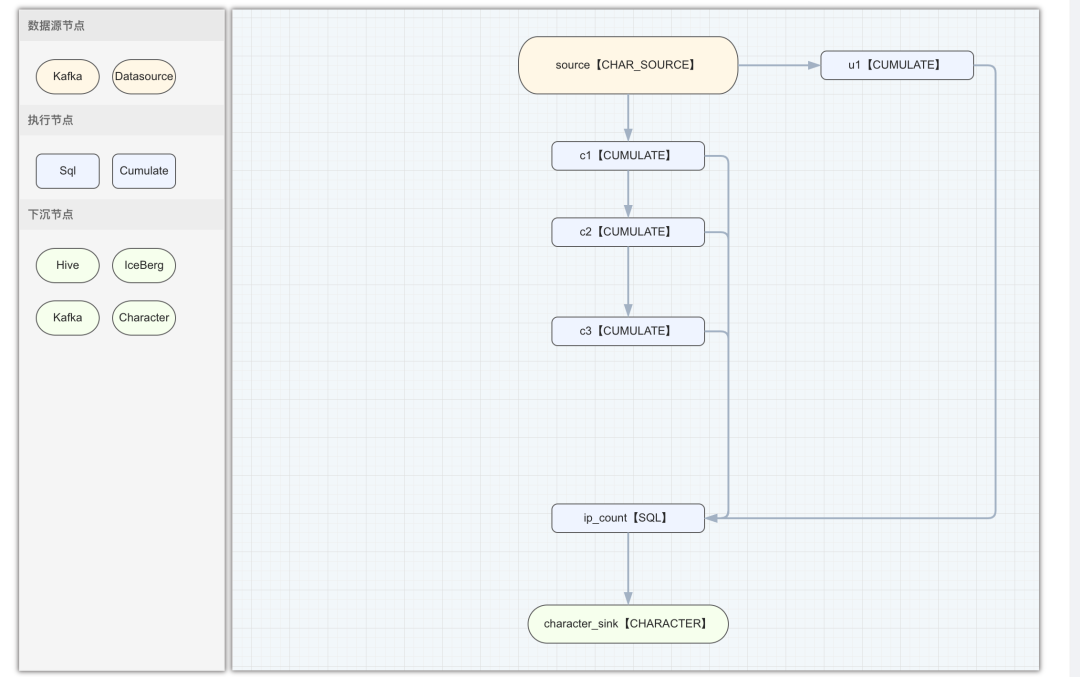
在我们的设计中,DAG 节点被清晰地划分为三大类别:数据源节点、计算节点,以及下沉节点。离线和实时特征任务,尽管它们共享了基本的节点分类框架,但在具体节点类型上有所区分:
数据源节点:离线特征任务专注于处理静态数据集,因而仅对接诸如 Hive 或 Iceberg 这类离线数据存储系统。相反,实时特征任务面向动态数据流,支持诸如 Kafka 这样的实时数据源,确保了对流式数据的即时处理能力。
下沉节点:延续这一区别,离线特征任务的下沉节点设计上同样偏向离线存储,而实时特征任务的下沉节点则展现出更高的灵活性,既可对接流式数据接收端,也能适应离线存储,满足多样化输出需求。
计算节点:双方均采用 SQL 配置节点,强调了易用性和灵活性,允许用户通过标准 SQL 来定制复杂的计算逻辑。实时特征在此基础上更进一步,引入了专用的累计节点类型 Cumulate,专门服务于实时数据窗口内的累加计算,尽管常规 SQL 节点也能实现累计功能,但 Cumulate 节点的引入为实时窗口计算提供了更加方便简洁的配置方案。
统一的部署能力
新平台统一收口了特征的部署链路,支持了特征的版本化迭代和一站式部署能力。这样一来,使用者无需关心底层的部署集群和复杂的任务上线链路;同时基于平台的统一信息管理,用户还可以直观了解任务的生命周期及当前状态,运行时上下游依赖。

优化效果
开发效能提升:新平台让我们摆脱了跨平台开发维护特征的历史,我们的特征运营平台数量从 4 个集中到了 1 个;统一的部署流程简化了上线链路:特征开发上线耗时从平均 5 小时缩短为最长 1 小时。
特征开发和维护成本降低:由于 DAG 中抽象了数据源和下沉节点,使用者可以聚焦于业务逻辑开发,灵活的链路编排能力让复杂计算链路的组合配置变得简单,统一的 SQL 开发语义也降低了开发门槛;特征的平均开发耗时从 3 小时降低为 30 分钟左右。
任务管理能力提升:新平台实现了特征任务的强管理,一方面特征和任务的映射关系变得明晰,另一方面由于统一了任务的打包和部署,基础组件(Kafka、Spark、Flink 等)升级及集群迁移将对使用者无感,平台侧能够进行统一升级。
流特征任务运行优化
合并相同前缀计算节点
得益于 DAG 编排的清晰任务结构,数据源得以明确界定,计算流程亦被精细分割,这为基于任务的拓扑结构进行运行时优化铺平了道路。为了最大限度提升计算效率并优化资源利用率,我们在多个任务间识别并合并重复的计算节点,详述如下:
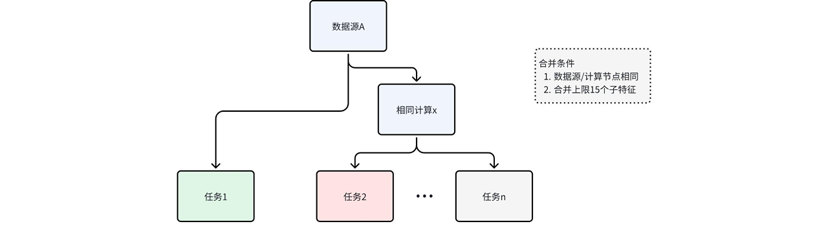
在我们的优化策略中,我们利用计算任务的共通性,通过以下方式进行任务整合:
基于计算前缀与数据源的一致性合并:识别那些源自相同数据源且执行相同计算逻辑的节点,将它们合并为单一运算单元。这样,相同的数据处理只需执行一次即可服务于多个下游任务节点,而其他不具备合并条件的节点则保持独立运行。被合并的任务作为一个整体提交执行,这不仅减少了调度开销,还降低了重复计算消耗并提升了单个任务的资源利用率。
风险控制与合并策略的审慎应用:尽管任务合并带来了效率的提升,但我们也意识到其潜在的风险,单个子任务的故障会导致整个合并任务集的中断,同时过多子任务合并会带来单个任务依赖资源过多,不利于计算调度。为平衡效率与稳定性,我们设立了合并任务的数量上限,并通过运行时监控和合并自动调整,动态管理了任务的运行规模,将任务大小控制在一定量级,同时也减少异常扩散的范围。
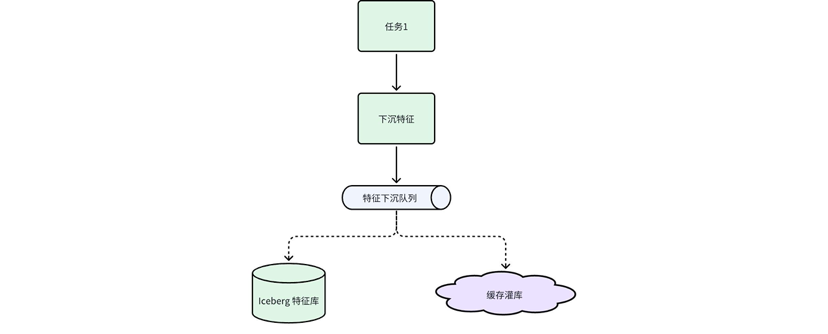
数据异步下沉
特征数据的下沉一般对接两类介质。一方面,我们利用如 Hive 和 Iceberg 这样的离线存储系统确保数据的持久化和可追溯;另一方面,通过存到 Redis 或 Couchbase 这类缓存系统保障特征数据的低延迟访问。
先前,特征生成任务在执行计算的同时直接负责数据下沉至存储介质,但实践中发现,尤其是在 Flink 任务框架内,数据下沉成为了较为耗时的瓶颈,特别是当需要对接多种存储介质时,数据积压问题尤为突出,严重时甚至会影响整个处理链路的流畅性。
鉴于此,我们将数据计算与下沉过程解耦,引入了 Kafka 作为中间件,构建了异步下沉机制。这一改变不仅减轻了计算任务的负担,提高了计算效率,而且通过 Kafka 的高吞吐量和低延迟特性,确保了数据持久化消费的顺畅。更重要的是,各存储介质的消费逻辑得以独立进行,特征缓存生效的及时性得到了保障。
优化效果
资源利用率提升:通过适当的任务合并和动态监控调整合并规模,我们将特征运行任务的资源利用率控制在了合理范围(目前特征任务的 CPU 利用率维持在 60% 左右),同时确保了运行的稳定性;
特征生效延迟降低:基于下沉链路的异步化和下沉消费隔离改造,实时特征缓存生效时间从之前最长 6 小时左右缩短到最长 4 分钟左右。
复杂任务计算优化
实时长窗口累计特征痛点
在业务实践中,频繁产生长窗口累计特征的需求尤为常见,例如,要求每分钟统计每个设备在过去 24 小时内的登录次数。然而,当设备基数膨胀至亿量级,这种高频率 24 小时数据的持续计算对计算和存储构成了巨大挑战。以往通过平台的模板化配置手段,我们不得不采取直接且消耗资源的计算策略,即将所有相关数据在 Flink 实例中维持长达 24 小时以上,并在每次计算周期中遍历全部数据集。
这种处理模式的困境不言而喻:由于数据体量庞大且计算频率极高,系统不得不依赖极其庞大的 CPU 与内存资源,同时,特征数据的实时性也难以保证,经常导致数据处理严重积压。
基于 DAG 开发模式的任务优化方案
在全新的特征平台设计中,得益于任务编排的灵活性,我们得以对长窗口累计型特征实施分层计算策略。具体优化方案如下:
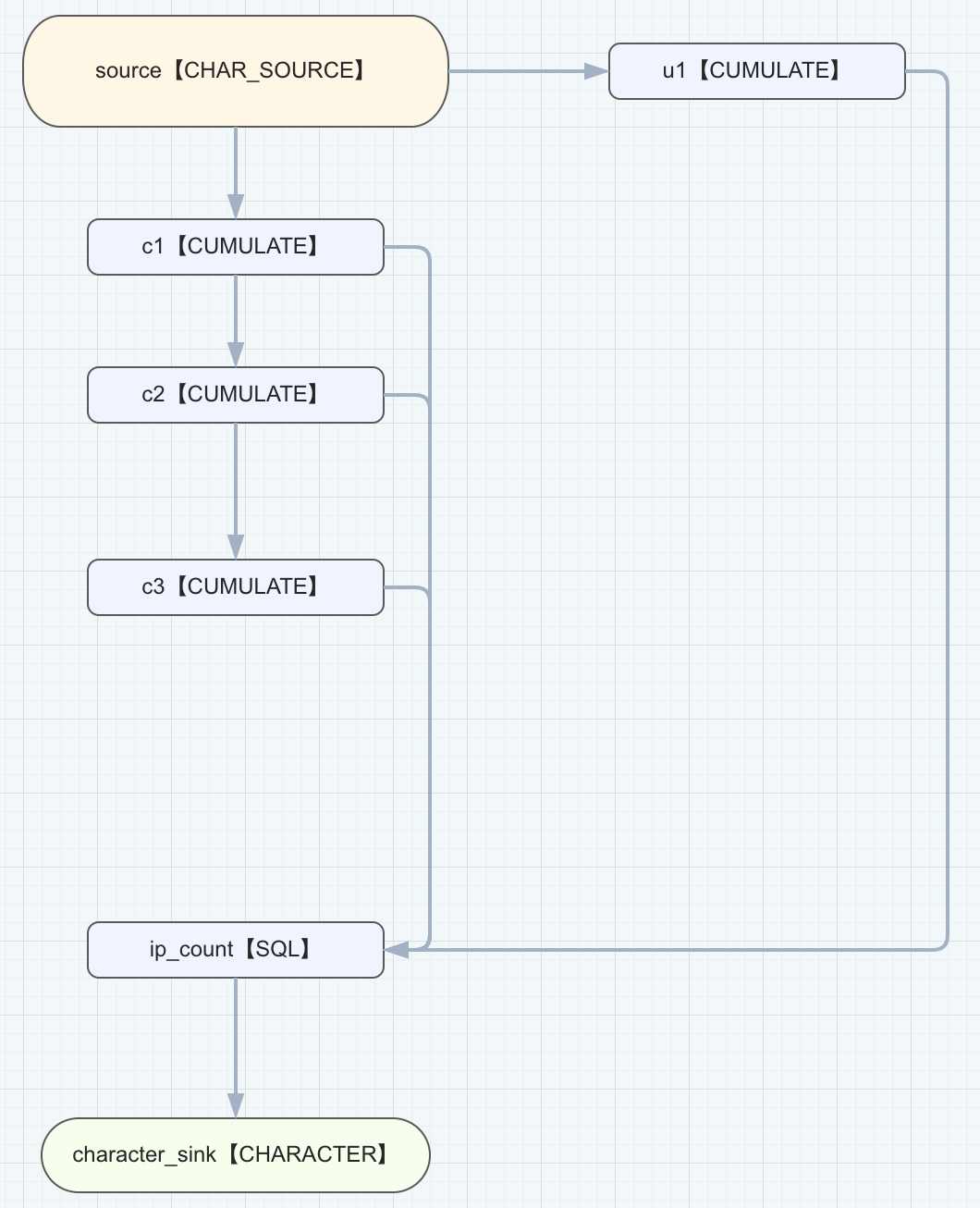
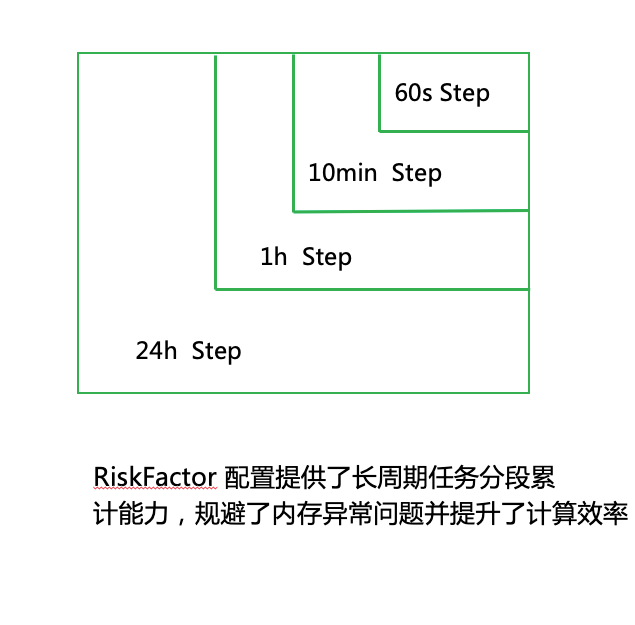
我们将 24 小时的长周期计算细分为四个递进的计算层级:
基础层:直接依托原始数据流,每分钟汇总每台设备过去 60 秒内的登录次数,生成即时数据集合 C1。这一层奠定了后续计算的基础。
中间层一:构建于 C1 之上,每分钟进一步汇总过去 10 分钟内每台设备的登录总和,形成数据集合 C2。
中间层二:以 C2 为输入,继续每分钟累计过去 1 小时内每台设备的登录总数,输出为数据集合 C3。
汇总层:最终层依赖于 C3,每分钟计算过去 24 小时内每台设备的登录总量,得出最终所需的长周期累计数据集合。
这样的分层计算架构通过前置层的计算降低了计算规模,同时通过对前置层计算结果的依赖,避免了长窗口数据累积带来的内存压力,最终实现了计算和存储压力的有效降低。
特征迭代版本化方案
新平台在特征变更方面做了灰度设计,以实现发布可灰度、指标可监控、异常可回滚。基于这套设计我们不仅可以实现增量特征的高可用迭代,也支持了存量特征的稳定迁移。
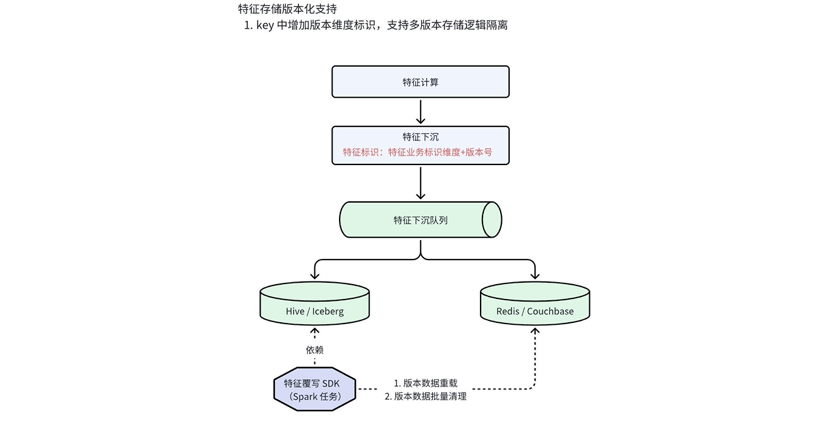
特征生产版本化隔离
特征存储层进行多版本隔离存储:
特征 key 设计增加版本号维度字段,实现存储逻辑隔离;
提供特征覆写 SDK,支持基于版本刷新和清理缓存数据。
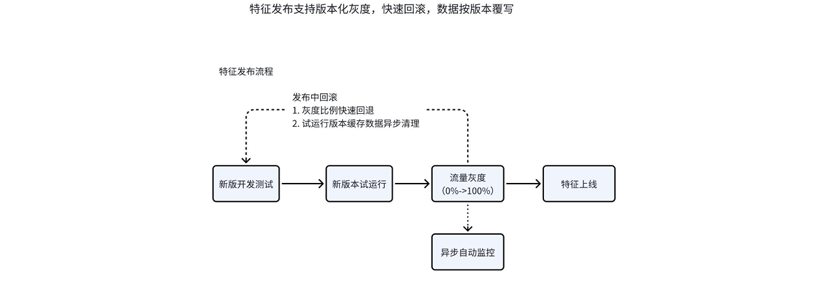
特征版本化灰度发布支持:
特征试运行阶段多版本任务共存;
灰度比例控制阶段支持对线上使用特征版本进行动态调整;
特征回滚操作基于灰度比例快速回退线上使用特征版本,同时通过特征覆写sdk异步清理试运行版本缓存数据;
上线阶段将只存在最新版特征任务。
注意:实际上我们只在试运行任务的下沉特征key中增加版本号标识,一旦任务上线,key 中将不再包含版本号。这样设计的好处有:
缓存中查询某个特征最多进行两个 key 点查就可获得数据;
历史稳定版本特征和最新稳定版特征 key 结构保持一致,确保缓存高效地被新数据覆写,查询时也无需进行多版本路由。反之,如果所有稳定版本特征任务都在 key 中包含版本号,查询缓存时就需要由新至老遍历版本,直至查到第一个数据。
特征查询版本化路由
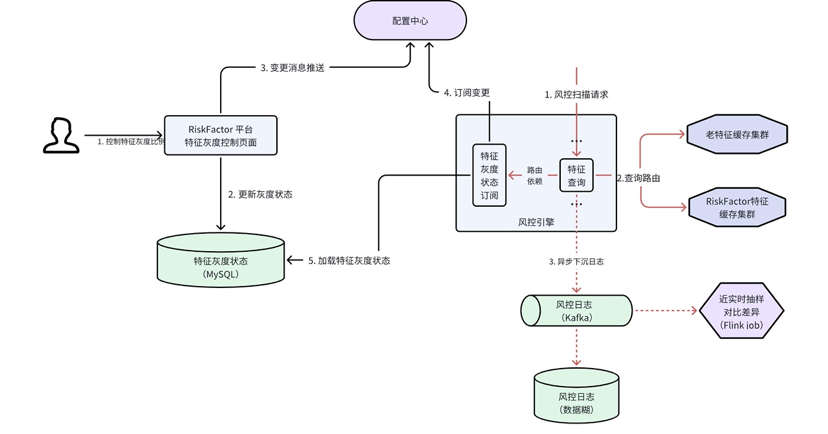
基于版本灰度的状态配置,引擎侧实现特征查询版本的动态控制,这不仅支持了新特征平台上特征的安全迭代,还支持了旧特征平台上 1000+ 特征的无故障迁移,实现了新旧特征平台的平稳切换。
05
未来规划
RiskFactor 平台目前已实现流批一体特征开发部署及运营的能力,特征任务的生产效能上也有了较大提升。后续我们将继续聚焦风控业务的发展需求,提升特征平台的业务支持维度和运营效率。规划中的关键功能如下:
图风控支持:图是计算群组特征的一大利器,新平台将摸索与图引擎的结合,利用图作为数据源或计算引擎生产图相关的特征,以支持图风控场景;
复合特征支持:针对运行时动态特征生成的诉求,我们将推出复合特征,这类特征将集成动态特征计算脚本,支持运行时依赖其他特征或数据接口计算出特征数据;
06
致谢
感谢爱奇艺 Opal 机器学习平台为风控特征平台提供了特征生产及查询的能力支撑,关于 Opal 的详细介绍,可阅读之前发表的《Opal 机器学习平台:爱奇艺数智一体化实践》、《爱奇艺 Opal 机器学习平台:特征中心建设实践》


















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









