






转自公众号:首席数据科学家
本篇文章和大家简单介绍一下标签数据的分类。
按照不同的分类方法,标签的分类也自然不同。本文主要介绍几种最常规的分类方式,包括按照来源方式、按照业务场景、按照标签的数据类型等。
01
—
按照来源分类
首先是按照标签的来源分类。主要分为以下的几类:
(1)用户自己填写的数据生成的标签
这部分标签是用户在注册产品或者在各个模块自行填写的信息。一般就是【性别】、【生日】、【真实姓名】、【居住地】、【身份证】等
例如下图是联想的官网,用手机号注册成功后,进入个人信息页面,可以看到各种信息的填写。
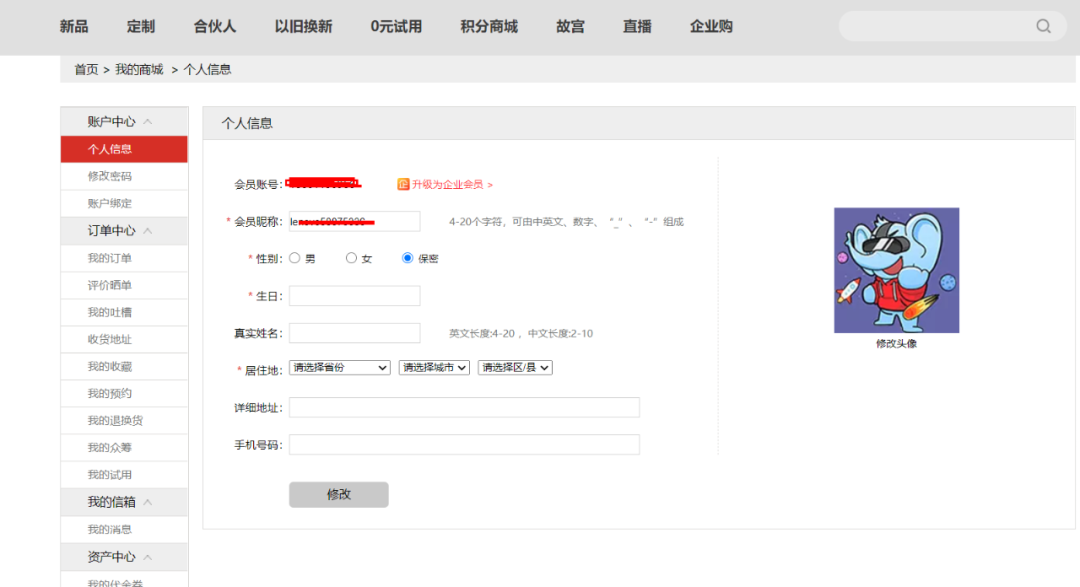
互联网早期,很多网站的注册比较麻烦,必填的信息项目较多,因此能拿到的数据也就多。但随着互联网红利的消失,用户的获取愈发困难,在注册阶段收集用户信息变得越来越简洁,目前绝大部分网站的收集就只保留了手机号,用手机号及验证码即可完成注册。后续则通过一些积分、优惠等方式激励大家主动填写。
【优缺点】这部分数据用来做标签,往往是最基础的。但存在的最大的问题是标签覆盖度过低,有意愿填写的用户常常比例不过半。而且对于部分敏感信息,例如身份证、地址等,如果逼迫用户填写,用户经常会填写虚假信息。这对于后续标签画像而言,不太好用。除非是12306这种强制性的网站,对身份信息能保障。
(2)通过统计用户行为,生成的统计标签
这类标签指标是最多的。
比如可以根据订单表,统计用户的订单金额;可以根据搜索表,统计用户的搜索次。
【优缺点】这部分数据用来做标签,是比较客观的,用户的行为不会说谎。但存在的一个问题是,要对标签画像系统产生价值,需要较多的逻辑处理。例如,想给用户打一个【购买力高低】的标签,是统计最近7天的成交金额,还是最近30天的?是按照订单口径还是金额口径?是大于1万算高,还是大于1000就算高?这里都需要大量的逻辑。如果只是一个统计值,只能算是一个宽口径的半加工的标签,真正用起来的时候,存在一些障碍。
(3)通过算法生成的标签
算法,很万能。
这玩意就是,很多场景不得不用。比如,想打一个【准妈妈】标签。这时,你咋办?你想尽各种逻辑,比如最近有搜索宝宝装行为的、最近有买孕妇服的……很多特征都能反映【准妈妈】的特点,但是通过简单的逻辑,是无法实现的。这个时候,就扔给算法团队吧……他们会基于大量的特征,训练模型,最后打上【准妈妈】的标签。
【优缺点】算法标签的缺点很突出,就是费时费力,做一个标签的时间可能要一两个月,做统计标签都做了几十个了……但如果算法靠谱,效果常常也不错,对业务的价值往往也比较大。如果公司算法资源富裕,那就做吧!当然,要有业务价值哦~
(4)通过第三方采购、积累的
土豪的方式很简单,买!
比如采购点身份证信息、采购点用户的征信信息等等。
【优缺点】优点就是省事。缺点就是费钱,而且能买的标签通常都是比较通用的,一些个性化的,例如网站的访问频次等,也是不太好采购的。当然还涉及数据安全的风险。
02
—
按照数据类型分类
按照数据类型,主要分为以下几类:
(1)数值型标签
刚才上文提到的【用户最近7天购买金额】、【用户近1天浏览天数】等,这些标签都是按照一定的规则统计生成的,均是数值型标签。其实本质上和指标没有太大区别。
组成公式是:【时间范围】+【行为方式】+【统计方式】。
下图是达摩盘标签中的部分统计标签:
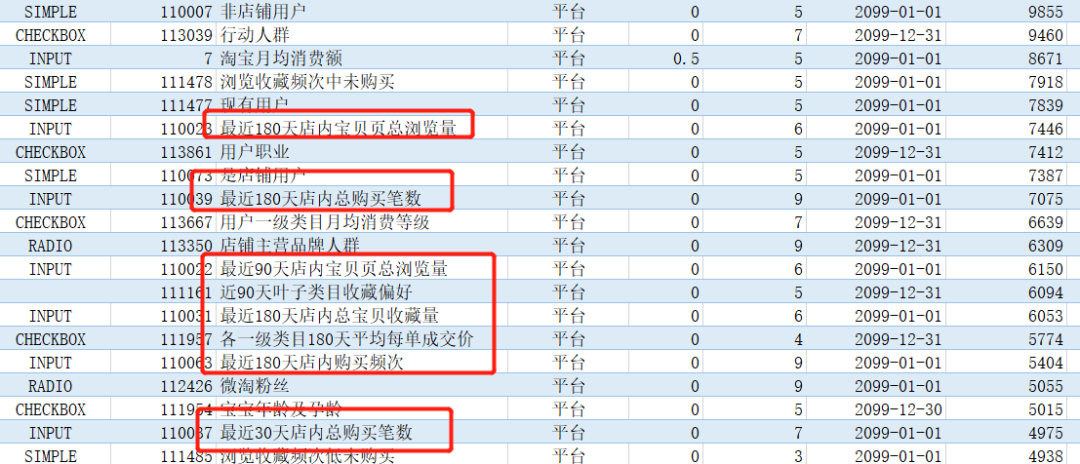
时间范围不说了,行为方式表示这个指标的含义,例如成交、搜索、点击等。统计方式是【计数】、【求和】、【最值】等
【优缺点】按照不同的时间范围、不同的行为方式、不同的统计方式,可以组成大量的标签。数量虽多,但是价值密度很低。因此,在成熟的标签系统中,这类标签不会大量在计算,往往是用户创建了啥就用啥。优点是比较容易生成。
(2)单值型枚举标签
这种标签可以是用户自己填写生成的,也可以是通过数值型标签进行加工,或者算法,生成的。
这类标签的最大特征,就是一个用户在这个标签中,只能有一个选项值。而且,和数值型标签的区别在于,单选型标签的选项值是可穷举的,是离散的。
例如:【用户的生命周期】,用户肯定是处于【成长期】、【成熟期】、【衰退期】、【沉睡期】其中的一个,不可能属于两个或者多个。
例如:【性别】
(3)多值型枚举标签
和单选型标签的区别就在于,一个用户可以有多个值。
同样,复选型标签也是离散值,选项是可穷举的。
例如:【用户的收货城市】,用户可以有多个城市
(4)文本型标签
这类标签最大的特征,是不连续、且不可穷举。
例如,【用户常用热搜词】,每个用户都可以有自己的常用热搜词,但热搜词的数量是巨大的,不能像单选型标签或者复选型标签那样,几个、甚至最多几十个选项,就能覆盖所有。
为啥要进行这个分类呢?
其实主要是在标签系统中,用标签筛选人群的时候有用。不同数据类型的标签,在前端的交互是一定要有区分的。这个后续详细展开。
03
—
按照业务场景分类
这种分类方式,根据各自业务的不同,就见仁见智了。
这个分类,主要是用于标签系统的标签管理,按照业务方式进行组织标签类别,有助于用户的便捷使用。
下面是阿里达摩盘的标签分类,仅供参考
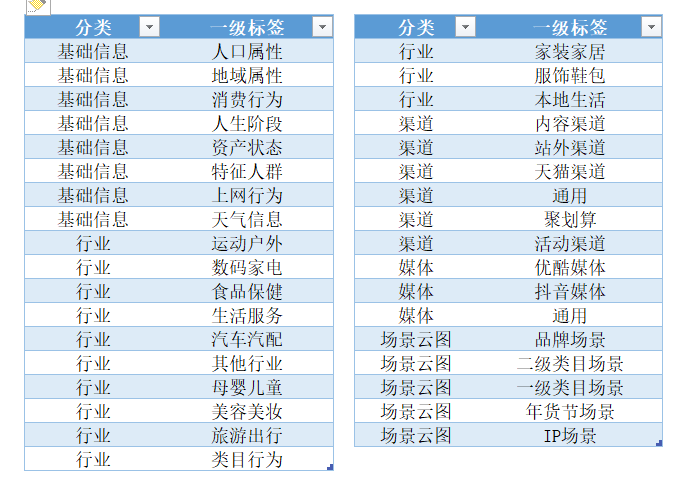
以下是某司内部的标签分类:

以上,先到这。后续标签画像系统的分享将继续。
















 8288
8288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









