







文章目录

摘要
-
洪水在世界各地肆虐,造成数十亿美元的损失,并连根拔起社区、生态系统和经济。美国国家航空航天局(NASA)的冲击洪水探测竞赛要求参与者在有监督的环境下使用合成孔径雷达(SAR)图像进行训练后,预测洪水像素。我们提出了一种半监督学习伪标记方案,该方案从U-Net集合(U-Net ensembles)得到置信度估计,逐步提高准确性。
-
具体地说,我们使用了一种包含多个阶段的循环方法(1)使用提供的高置信度手工标记数据和在整个未标记测试数据集上生成的伪标签或低置信度标签训练多个U-Net架构的集成模型,然后,(2)过滤掉高质量生成的标签和,(3)将生成的标签与之前可用的高置信度手工标记数据集相结合。这个同化的数据集用于下一轮的训练集成模型,并重复循环过程,直到性能改善的平台。我们使用条件随机场来处理我们的结果。我们的方法在Sentinel-1数据集上设置了最新的0.7654 IoU,比0.60 IoU基线有了令人印象深刻的改进。我们发布了所有代码和模型2的方法,也可以用作Sentinel-1数据集的开放科学基准。
引言
- 由于气候变化、海平面上升和极端天气事件的增加,洪水事件正在增加,每年造成100亿美元的损失。科学家和决策者可以通过Sentinel-1等卫星使用实时地球观测数据来制定实时响应和缓解策略,并了解洪水事件。计算智能(ETCI)的新兴技术2021年洪水检测竞赛提供了一个地理区域在洪水事件之前和之后的SAR Sentinel-1图像,带有标记像素。像Sentinel-1这样的SAR卫星可以穿透云层和夜间,因此可以随时随地使用,使其解决方案可以大规模部署。参与者被要求执行一个语义分割任务,识别被淹没的像素,并使用联合度量的交集(IoU)进行评估。
- 改进的洪水分割实时结果,圈定开阔水域洪水区域。确定洪水水位有助于有效应对和减轻灾害。将洪水范围图与当地地形相结合,就会产生一个行动计划,其下游结果包括预测水流方向、重新引导洪水、组织资源分配等。这样的系统还可以实时推荐最低洪水水位的路径,灾害响应专业人员可能会采用。
- 基于特征的机器学习技术在[27]中也很突出,但由于人类注释器和特征器无法扩展,所以很难处理。实时手动注释每天的费用很容易超过62,5003美元,手动解决方案很快就变得棘手。受现有技术[44,45,7,19]的启发,我们研究了半监督技术,该技术假设最大预测概率的预测标签为地面真实值,并将其应用于洪水分割。与[19,3]类似,我们将伪标签作为熵正则化器( entropy regularizer),最终在使用有标记数据的小子集时优于其他传统方法。对于实时部署,我们对我们的解决方案进行了基准测试,类似于[23,36],这两种解决方案都利用了worldflood等数据集或多光谱数据集来实现洪水检测,但都需要大规模的人工标注。与两者相反,我们的半监督工作减少了人在回路的负载,并允许我们以一种简单的方式利用大型未注释示例。有证据表明,使用条件随机场(CRF)[17,9,2,42]进行后处理可以提高性能,特别是对于语义分割和卫星数据[12]。当我们使用crf进行洪水分割时,我们的工作遵循了类似的路线。
- 我们的贡献是:(1)我们提出了一个带有伪标记的半监督学习方案,该方案从U-Net集合中得到置信度估计。基于此,我们建立了新的最先进的洪水分割器,据我们所知,我们相信这是第一次尝试半监督学习来改进洪水分割模型。(2)我们表明,我们的方法通过伪标签可伸缩,通过不同地理位置的不同数据分布可推广,因此可伸缩部署的成本较低。(3)此外,我们对推理管道进行了基准测试,表明它可以实时执行,帮助实时的减灾工作。我们的方法还包括不确定性估计,使灾害响应团队了解其可靠性和安全性。为了促进开放科学和交叉协作,我们发布了所有的代码和模型。
数据
- 竞赛数据集由来自不同地理位置的66k平铺图像组成。每个RGB训练tile都是由Sentinel-1 C波段SAR图像通过Hybrid Pluggable Processing Pipeline hyp3生成的VV和VH GeoTIFF文件(原始图像见附录C,图4)。数据还包含条带间隙(见附录C图5中的图像),其中图像的面积小于0.5%;这样的图像不用于训练。
- 由于数据集是不平衡的,即存在洪水区域的图像比不存在洪水区域的图像所占的比例要低,因此在训练时,我们通过分层抽样,**确保每批图像中至少包含50%的具有一定洪水区域的样本。由于添加了碎片,被淹没的水可能会改变外观,而这些数据可以由不同的传感器捕捉到,但在我们的工作中,我们不假定有区别。在测试集中占主导地位的红河地理区域,主要是一个农业中心,由于VV和VH极化的低后向散射,最近收获的田地可能看起来像洪水。同样,佛罗伦萨由验证集组成,主要是城市设置。这种变化的后向散射与性能优化和测试图像的概括性相关(见图4中的组合图像),因此我们将不同形式的集成与叠加结合起来(combine different forms of ensembling with stacking),**并且,测试时间增强有助于模型的不确定性,并使预测稳健。训练增强包括水平翻转、旋转和弹性变换,测试时间增强由Dihedral Group D4[32]组成。
方法
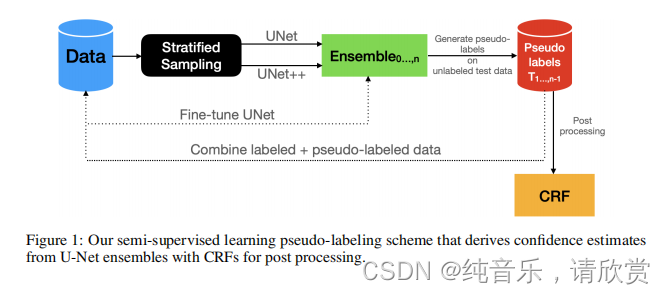
图1:我们的半监督学习伪标记方案从U-Net集合中获得置信度估计,并使用crf进行后处理。
-
我们开发了一个带有伪标记的半监督学习方案,该方案从[18]激发的U-Net集合中得到置信度估计。首先,我们使用提供的高置信度手工标记数据训练一个多U-Net架构的集成模型( train an ensemble model of multiple U-Net architectures),并在整个未标记测试数据集上生成伪标签或低置信度标签。然后,我们过滤掉高质量生成的标签,最后,将高质量生成的标签与之前提供的高置信度手工标记数据集结合起来。此同化数据集将用于下一轮的训练集成模型。这个循环过程会一直重复,直到性能提升达到稳定水平(参见图1)。此外,我们还会使用条件随机场(CRF)对结果进行后期处理。
-
步骤1:训练可用数据,对整个测试数据执行推断,并生成伪标签。所提供的测试数据仅来自红河北部地区,未出现在训练(孟加拉国+北阿拉巴马+内布拉斯加州)或验证数据集(仅佛罗伦萨)中,因此分布外(out-of-distribution)影响迫在眉睫。分布上的这些差异促使我们使用集合。首先,我们使用U-Net[30]和U-Net++[43]训练两个模型,两者都使用MobileNetv2骨干[31],并结合骰子和焦点损失( combined dice and focal loss)的可用训练数据。U-Net和U-Net++都有类似的归纳偏置( inductive biases),由于不同的地理位置和人为因素,如最近收获的田地、城市和农村场景(见附录,图4)等,我们使用它们来处理分布转移。然后,用这两个训练过的模型创建一个整体(ensemble)。
-
步骤2:过滤优质伪标签。接下来,我们过滤预测的softmax输出,使图像中至少90%的像素是有洪水或没有洪水的高置信度。在第0次训练迭代中,没有可用的伪标签,只在提供的训练数据集上进行训练。对于下一步,即步骤1或训练迭代1,可以使用迭代0中的伪标签。这样,训练迭代n可以合并步骤n-1中的伪标签。对于标准图像分类任务,通常会根据预定义的置信阈值[38,33,46]过滤软最大预测。在语义分割中,我们将分类任务扩展到逐像素的情况,即图像的每个像素都需要分类。为了过滤掉低置信预测,我们检查每个预测中预先指定的像素值的%(在[0,1]范围内)是否高于预定义的阈值;数学表示为(1)。
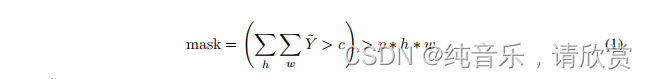
其中Y是预测向量,c和p分别表示置信阈值和像素比例阈值(在本例中均为0.9),h和w是预测的分段映射的空间分辨率。我们用(2)计算Y,其中Z是logit向量。
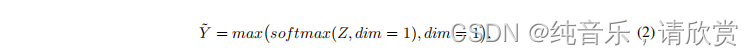
-
步骤3:伪标签+原始训练数据的组合。 现在,前一阶段过滤的伪标签被合并到训练数据集中。这样,就创建了一个新的训练数据集,它由(1)具有可用ground truth的原始训练数据,称为高置信度标签,和(2)在未标记的测试数据集上过滤的伪标签或低置信度标签组成。此同化数据集用于下一轮的个体U-Net、U-Net++和集成模型的训练。
-
重复步骤1、2、3和crf的后处理。现在,训练数据由原始训练数据集和测试数据集的伪标签组成,我们从头开始训练U-Net和U-Net++模型,并从上一次迭代中对U-Net进行微调。训练和微调都在原始训练数据和伪标记测试数据的同一个数据集上。
-
请注意,集成模型只用于生成预测,而不是用于微调。现在,有了三个训练好的模型,就像以前一样,生成平均的预测,并进行过滤,以创建新的弱标签集。所有用于训练U-Net、U-Net++和微调U-Net的数据都像之前一样进行分层抽样处理。这个循环过程(步骤1、2、3…)会一直重复,直到性能提升的平台,大约20个时期,之后我们会用crf执行额外的处理。最终,对于我们预测的被淹或未被淹的每一个像素,我们还生成了可信区间,这可能有助于灾害响应团队理解可靠性和安全性。
全连接CRFs后处理
- 目前图像像素级语义分割比较流行使用深度学习全卷积神经网络FCN或者各种FCN的改进版U-Net、V-Net、SegNet等方法。这些模型中使用了反卷积层进行上采样操作,虽然能够将特征图恢复至原图尺寸,但也造成了特征的损失,自然而然产生了分类目标边界模糊的问题。
- 为了得到更精确的最终分类结果,通常要进行一些图像后处理。全连接CRFs是在目前深度学习图像分割应用中常用的一种图像后处理方式,它是CRFs的改进模式,能够结合原始影像中所有像素之间的关系对深度学习得到的分类结果进行处理,优化分类图像中粗糙和不确定性的标记,修正细碎的错分区域,同时得到更细致的分割边界。
例如:

处理前的结果:

处理后的结果:
仔细看变化还是挺大的,去掉了很多杂质,让类别分布更纯粹

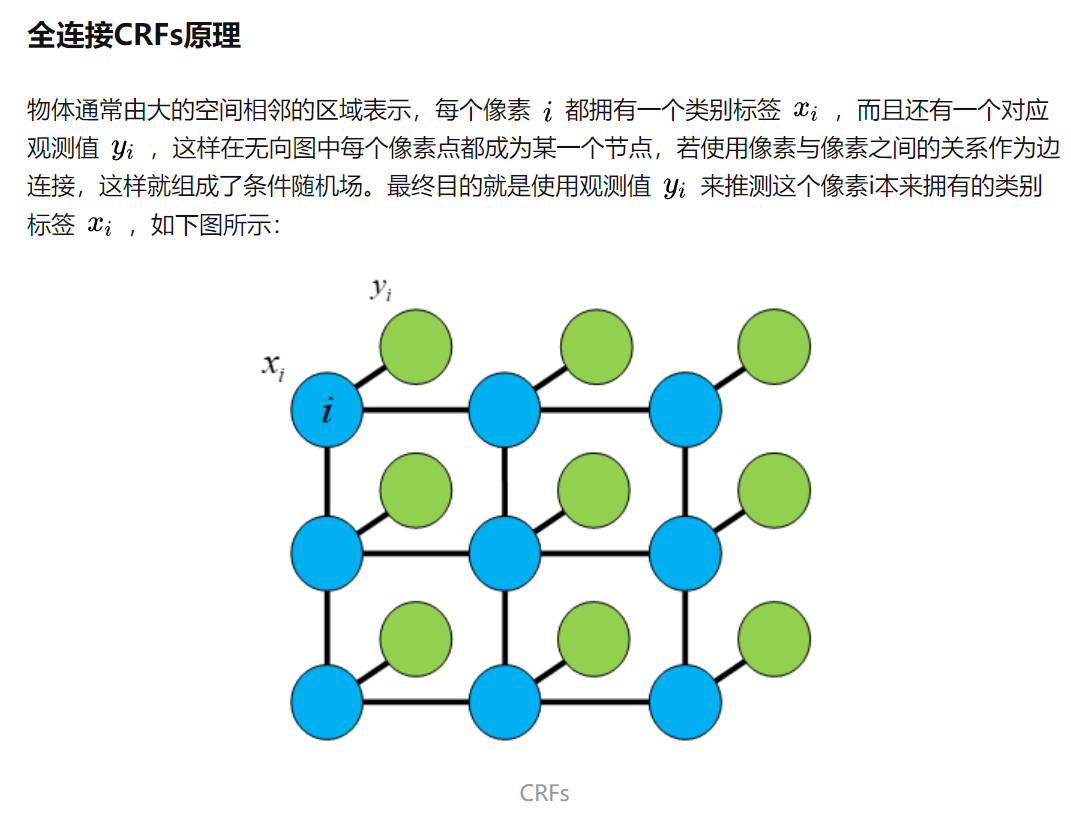


全连接条件随机场使用二元势函数解释了一个像素与另一个像素之间的关系,给像素关系紧密的两个像素赋予相同的类别标签,而关系相差很大的两个像素会赋予不同的类别标签,这个“关系”的判断与像素的颜色值、像素间的相对距离都有关系。全连接条件随机场中二元势函数解释了每一个像素与其他所有像素的关系,与条件随机场相比,“全连接”更加紧密一些。
在全连接CRFs进行影像后处理的实际操作中,一元势能为概率分布图,即由模型输出的特征图经过softmax函数运算得到的结果;二元势能中的位置信息和颜色信息由原始影像提供。当能量E(x)越小时,预测的类别标签X就越准确,我们通过迭代最小化能量函数,得到最终的后处理结果。
@ray.remote
def custom_crf(mask_img, shape=(256, 256)):
# Converting annotated image to RGB if it is Gray scale
if(len(mask_img.shape)<3):
mask_img = gray2rgb(mask_img)
# Converting the annotations RGB color to single 32 bit integer
annotated_label = mask_img[:,:,0] + (mask_img[:,:,1]<<8) + (mask_img[:,:,2]<<16)
# Convert the 32bit integer color to 0,1, 2, ... labels.# 将uint32颜色转换为1,2,...
colors, labels = np.unique(annotated_label, return_inverse=True)
n_labels = 2
# Setting up the CRF model
d = dcrf.DenseCRF2D(shape[1], shape[0], n_labels)
# Get unary potentials (neg log probability)# 得到一元势(负对数概率)一元势即网络预测得到的结果,进行-np.log(py)等操作
U = unary_from_labels(labels, n_labels, gt_prob=0.7, zero_unsure=False)
d.setUnaryEnergy(U)
# This adds the color-independent term, features are the locations only.
# 增加了与颜色无关的术语,只是位置-----会惩罚空间上孤立的小块分割,即强制执行空间上更一致的分割
#二元势即用于描述像素点和像素点之间的关系,鼓励相似像素分配相同的标签,而相差较大的像素分配不同的标签。这个相似的定义与颜色值srgb和实际相对距离sxy相关,所以CRF能够使图片尽量在边界处分割。
#d.addPairwiseGaussian这个函数创建的是颜色无关特征,这里只有位置特征(只有参数实际相对距离sxy),并添加到CRF中
d.addPairwiseGaussian(sxy=(12, 12), compat=4, kernel=dcrf.DIAG_KERNEL,
normalization=dcrf.NORMALIZE_SYMMETRIC)
# Run Inference for 20 steps
Q = d.inference(20)
# Find out the most probable class for each pixel.
# 找出每个像素最可能的类
MAP = np.argmax(Q, axis=0)
return MAP.reshape((shape[0], shape[1]))


Results

- 我们在表1中报告了从各种方法中获得的所有结果,并与一个随机的(所有的0表示非淹没像素,因为大多数像素没有被淹没)和竞争提供的基线(FPN[20]与U-Net的组合)进行比较。我们还提供了一些与图2中的预测进行随机比较的基本事实。由于数据集是倾斜的,即大多数像素没有被淹没,我们只报告被淹没像素的iou。在使用U-Net、U-Net++、集成模型和来自集成的平均预测执行测试推断时,我们注意到在每个步骤中平均预测的性能平均提高了2-3%。测试数据测试时间的增加使我们的IoU提高了5%,并进一步减少了不确定性。我们的结果在数据集中所有可用的数据分布漂移中是一致的,初始基准测试表明,对于一个Sentinel-1瓦片,分割掩模大约在3秒内生成,覆盖面积约63,152平方公里,比Huron湖覆盖的面积大,北美第二大淡水大湖。我们的研究表明,crf是预测后期处理的一个关键元素,因为它们提供了实质性的性能改进。

图2:随机选择Ground Truth与我们在hold-out测试集上的预测进行比较,在hold-out测试集上显示最终排行榜结果
Conclusion
我们认识到,参与跨学科研究以减少洪水事件的影响是一种荣幸,因此,可扩展的部署解决方案是一个巨大的组成部分。我们开发了一个半监督学习伪标记方案,从U-Net集合中得到置信度估计。我们使用提供的高置信度手工标记数据训练一个多U-Net架构的集成模型,并在整个未标记测试数据集上生成伪标签或低置信度标签,然后过滤掉高质量生成的标签,最后,将高质量生成的标签与之前提供的高可信度手工标记数据集相结合,并使用crf对我们的结果进行后期处理。我们展示了我们的方法可以使用数据分布漂移实现可伸缩的训练。此外,在保持结果质量的同时,缺乏带注释的数据和可伸缩性也是必要的。因此,我们未来的工作包括与竞赛组织者和UNOSAT团队合作,对实时运行时进行基准测试,并评估我们的解决方案的可伸缩性。
Appendix
A Implementation Details
-
抽样。训练数据集存在不平衡问题,即存在洪水区域的卫星图像的数量小于不存在洪水区域的卫星图像的数量。这就是为什么我们在数据加载过程中遵循分层采样策略(stratified sampling strategy),以确保任何给定BATCH中的一半图像总是包含一些洪水区域。根据经验,我们发现这种抽样对收敛有很大帮助。在我们的设置中使用这种抽样策略的动机来自于一个在之前的Kaggle竞赛中获胜的解决方案[1]。在减少条带间隙[11]的影响方面也存在研究,但由于时间有限,我们将在未来的工作中探索这一领域。
-
编码器骨干(Encoder backbone)。在整个工作中,我们坚持使用MobileNetV2作为编码器骨干,因为它使用的点向卷积,这是一个很好的问题。由于哨兵-1图像内部的边界细节非常精细,点向卷积(point-wise convolutions)非常适合于此。根据经验,我们试验了许多不同的主干,但它们的性能一致性都比不上MobileNetV2主干。
-
分割的体系结构。我们使用U-Net[30]和U-Net++[43]。和以前一样,点向卷积的优先级仍然有效。我们避免使用扩大卷积的架构,例如DeepLab架构家族[10]。我们尝试的其他架构包括LinkNet[8]和MANet[41],但它们都没有产生好的效果。使用基于u - net的体系结构和MobileNetV2编码器后端的影响在表2中有经验的报告。我们的结论是,将基于u - net的架构与MobileNetV2编码器后端相结合,用于具有极细分段的数据是有效的。

表2:比较模型架构和编码器骨干的各种组合的影响。在相同的培训配置下,使用带有MobileNetV2编码器后端的U-Net优于所有其他的。
-
损失函数。在医疗流程[25]中引入骰子系数(Dice coefficient),主要处理数据不平衡问题。洪水图像类似于器官或医学体素分割,有大量的不平衡,每个图像只有几个像素被识别为洪水。Focal loss [21]将权重分配给有限数量的正例子(在我们的例子中是淹没的像素),同时防止大多数非淹没像素在训练期间淹没分割管道。我们根据经验注意到,使用Dice损失相比Focal损失和两者结合时略有改善。
-
基线模型Baseline model。U-Net具有MobileNetV2骨干和测试时间扩展。后处理没有使用伪标记或条件随机场(CRFs)。这在测试集排行榜上的IOU为0.57。对于U-Net和U-Net++的初始训练(见第3节),我们使用Adam[16]作为优化器,学习率(LR)为1e-3,我们对这两个网络进行了15个epoch的训练,批大小为384。对于使用初始训练集和生成的伪标记数据集的第二轮训练(根据第3节,我们保持所有设置相似,除了epoch和LR调度的数量。在这一轮中,我们对网络进行了20个epoch(相同的批大小为384)的训练,以考虑更大的数据集,并且还使用了余弦衰减LR调度(cosine decay LR schedule )[22],因为我们正在微调预先训练的权值。我们在这些阶段中都不使用重量衰减( weight decay )。关于其他超参数的更多细节,请参考我们在GitHub8上的代码库。
-
修改后的架构。使用与基线完全相同的配置,我们训练了一个U-Net++,得到了0.56的IoU。
-
集成。基线U-Net和U-Net++的集合使性能提高了0.59个IoU。我们遵循一种基于堆叠的集成方法,在从每个集成成员导出预测后,我们简单地取这些预测的平均值。

我们引入了另一种带有测试时间增强的集成形式。在推断过程中使用测试时间增强的动机是由于数据分布差异,并且,为了更好地建模不确定性,我们在表3中强调了它的影响。

表3:在我们的例子中,在推断期间使用测试时间增强(TTA)可以显著地提高性能。两种情况下的训练模型都与后端为MobileNetV2的U-Net架构一致。
- 代码。我们的代码在PyTorch 1.9[28]中。我们使用许多开源软件包来开发我们的培训和推断工作流。在这里,我们把所有主要的因素都纳入进来。对于数据增强,我们使用albumentations包[6]。Segmentation_models_pytorch(简称smp)包[40]用于开发分割模型。timm包[37]允许我们在smp中快速试验不同的编码器骨干。使用ttach[39]包执行推断期间的测试时间增强,并提供大约5%的改进。对于初始预测的后期处理,我们利用pydensecrf包[5]应用crf。为了进一步加快后期处理时间,我们使用Ray框架[26]来实现对单个预测应用CRF的并行性。我们的硬件设置包括4块NVIDIA Tesla V100 gpu。 通过使用混合精度训练24和分布式训练设置(通过torch.nn.parallelDistributedDataParallel),我们可以显著提高总体模型训练时间。
B Experiments with Noisy Student Training
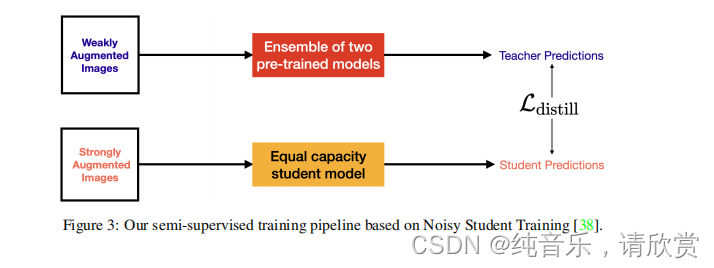
- 为了统一我们的迭代训练过程,我们还尝试了像嘈杂的学生训练[38]方法这样的技术,但是这种方法效果不太好。按照[38]的方法,我们执行了只向训练数据注入噪声的自我训练(在嘈杂的学生训练中,噪声也以随机深度[15]和Dropout[34]的形式注入到模型中。)。我们使用U-Net和u - net++模型的集合作为教师,使用U-Net模型(具有MobileNetV2后端)作为学生。在训练学生模型时,我们的数据包括训练数据和测试数据。这个培训管道如图3所示。通过这种方法,我们得到了0.75的IOU,这低于我们最终遵循的方法。我们还注意到,与我们最终解决的方法相比,这种方法需要的计算量要少得多。所以,如果IOU可以交易有限的计算需求,这种方法仍然产生竞争的结果。对于图3,Ldistill的定义为(3)。

其中,s_preds和t_preds分别表示来自学生和教师网络的预测,y是包含地面真值分割映射的向量,α是控制L_dice和L_KL贡献的标量(KL-Divergence), τ是表示温度[14]的标量。请注意,在3中计算l_dice时,我们使用了从强增强原始训练集及其地面真值分割映射中获得的预测。
- 从我们的实验中,我们相信,在[47,4]的启发下,有可能进一步推动这种性能,我们的目标是将其作为未来的工作进行探索。
C Supplemental Figures

图4:竞赛提供的原始数据(VV和VH tiles),以及洪水前后水体状态。我们用于训练的合成RGB或彩色图像,是使用ESA偏振测量指南生成的,其中红色为VV通道,绿色为VH通道,蓝色为|V V |/|V H|。所有图像都是从训练集中随机抽取的样本。我们注意到不同方向可见的谷物可能是由于孟加拉国最近收获的农田。北阿拉巴马州显示了各种人工制品,包括由于卫星覆盖范围的差异而可能出现的带状间隙,而内布拉斯加州的RGB颜色范围是独特的。北阿拉巴马州的图像带有带状的缺口被保留下来,因为至少有一些正面的地面真实图像(洪水过后)可用。
图5:噪声图像可能是由于带状间隙,也可能是由于VV和VH图像没有对齐而被过滤掉时出现的完全空白的图像。请注意,地面真相工件是不可取的,因为它们不能提供一个积极的例子。

















 3064
3064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











