







一 什么是时间序列(一元/多元)?
时间序列是现实世界中的某个观测变量随着其发生的时间先后顺序而形成的一组数字序列。
多元时间序列可以认为是一次采样中不同来源的多个观测变量的组合。
二 什么是因果关系分析,为什么要进行因果关系分析?
因果关系分析是一个系统(因)与另一个系统(果)之间的作用关系,其中第一个系统是第二个系统的原因,第二个系统依赖于第一个系统。
- 时间序列维度高,冗余和无关变量多,容易掩盖重要变量的作用,通过分析可观测变量之间的关系,可以找出对建模贡献度大的相关变量;
- 分析具有方向性的直接因果关系,有利于研究系统各个变量之间的驱动响应关系,适用于多变量系统的分析和建模。
三 因果关系分析方法
1 Granger因果关系分析
1.1 基本方法
基本原理: 若采用时间序列X和Y的历史信息对Y进行预测,优于仅采用Y的历史信息对Y进行预测的结果,即时间序列X有助于解释时间序列Y的未来变化趋势。通过建立的两个向量自回归模型,求解模型的残差,利用残差计算Granger因果指数。
Granger因果指数(GCI)定义为:
G
C
I
X
→
Y
=
I
n
v
a
r
(
ε
Y
)
v
a
r
(
ε
Y
∣
X
)
GCI_{X\rightarrow Y}=In\frac{var\left( \varepsilon _Y \right)} {var\left( \varepsilon _{Y|X} \right)}
GCIX→Y=Invar(εY∣X)var(εY)
类似的,也可以对
Y
→
X
{Y\rightarrow X}
Y→X进行Granger因果检验。
适用范围: 线性模型,二元平稳时间序列,否则可能出现虚假因果(即二元变量之间本没有因果性但呈现出一定的因果性)。
1.2 条件Granger因果模型
基本原理: 建立在多变量回归模型基础上,通过将条件变量加入到回归模型中,有效区分变量的直接和间接关系,得到直接因果关系。在建立向量自回归模型时,引入条件变量,求出模型的残差。
条件Granger因果指数(CGCI)定义为:
G
C
I
X
→
Y
∣
Z
=
I
n
v
a
r
(
ε
Y
∣
Z
)
v
a
r
(
ε
Y
∣
X
Z
)
GCI_{X\rightarrow Y|Z}=In\frac{var\left( \varepsilon _{Y|Z} \right)} {var\left( \varepsilon _{Y|XZ} \right)}
GCIX→Y∣Z=Invar(εY∣XZ)var(εY∣Z)
式中,
Z
Z
Z是条件变量。
适用范围: 线性模型,多元平稳时间序列。需要对时间序列中的多个变量中的任意两个变量进行Granger因果检测,计算复杂度很高。
1.3 Lasso-Granger因果模型
基本原理: 应用全部输入变量进行Lasso回归,根据模型回归系数识别Granger因果关系的强弱。目标函数如下所示:
min
{
∥
Y
−
X
α
∥
2
2
+
λ
∥
α
∥
1
}
\min \left\{\left\| Y- \boldsymbol{X\alpha } \right\| _{2}^{2}+\lambda \left\| \boldsymbol{\alpha } \right\| _1 \right\}
min{∥Y−Xα∥22+λ∥α∥1}
Y
Y
Y是预测变量,
X
\boldsymbol{X}
X为全部输入变量,
α
\boldsymbol{\alpha}
α为回归系数,
λ
\lambda
λ为正则化参数,用于控制惩罚性大小。如果时间序列
X
j
X_j
Xj对应的系数
α
j
\alpha_j
αj为零或者接近于零,则表明时间序列
X
j
→
Y
{X_j}\rightarrow Y
Xj→Y不存在Granger因果关系,反之存在因果关系。
优点: 相较于基本Granger因果模型和条件Granger因果模型,该模型能够分析出全部输入变量对预测变量的因果关系,大大缩减了计算量。
适用范围: 线性以及非线性模型,多元平稳时间序列
1.4 非线性Granger因果模型(还有不懂的地方需要学习…)
基本原理: 建立非线性预测模型,用于衡量二变量之间的非线性Granger因果关系。如基于径向基函数的非线性预测模型,基于核方法的非线性Granger因果模型,基于Copula的Granger因果模型…
适用范围: 非线性,多变量系统因果分析,平稳时间序列
1.5 频域Granger因果模型
基本原理: 通过傅里叶变换等方式将建立的时域模型转换为频域模型,进而分析因果关系。
基于直接传递函数的方法,对建立的向量自回归模型系数进行傅里叶变换,定义
H
(
f
)
=
A
−
1
(
f
)
H\left(f \right) = A^{-1}\left(f \right)
H(f)=A−1(f)为传递系数矩阵,则时间序列
X
j
→
X
i
X_j\rightarrow X_i
Xj→Xi的因果关系为:
D
T
F
X
j
→
X
i
∣
Z
(
f
)
=
∣
H
i
,
j
(
f
)
∣
2
∑
k
=
1
K
∣
H
K
,
j
(
f
)
∣
2
DTF_{X_j\rightarrow X_i|Z}\left(f \right) = \frac{\left| H_{i, j}\left(f \right) \right|^2}{\sum_{k=1}^K{\left| H_{K,j}\left(f \right) \right|^2}}
DTFXj→Xi∣Z(f)=∑k=1K∣HK,j(f)∣2∣Hi,j(f)∣2
描述的是在频率
f
f
f下时间序列
X
j
→
X
i
X_j\rightarrow X_i
Xj→Xi的直接因果关系,其值接近于0,表示无因果,大于一定的阈值表示有因果关系。
适用范围: 线性,多变量系统因果分析
2 基于信息理论的因果分析
熵能够表示一个系统混乱的程度,系统混乱程度越高,其熵值越大,包括信息熵 H ( x ) H(x) H(x), 联合熵 H ( X , Y ) H(X,Y) H(X,Y), 条件熵 H ( X ∣ Y ) H(X|Y) H(X∣Y), 互信息 I ( X ; Y ) I(X;Y) I(X;Y)等。
2.1 转移熵
基本原理: 通过信息转移来判断变量之间的因果关系,是一种非参数模型方法,能够很好地分析两个系统的耦合强度和非对称驱动响应关系。对于时间序列
X
X
X和
Y
Y
Y的转移熵定义为:
T
E
X
→
Y
=
∑
y
t
+
1
,
x
t
,
y
t
p
(
y
t
+
1
,
x
t
,
y
t
)
log
p
(
y
t
+
1
∣
x
t
,
y
t
)
p
(
y
t
+
1
∣
y
t
)
=
H
(
Y
t
+
1
∣
Y
t
)
−
H
(
Y
t
+
1
∣
X
t
,
Y
t
)
=
I
(
Y
t
+
1
;
X
t
∣
Y
t
)
TE_{X\rightarrow Y}=\sum_{y_{t+1},x_t,y_t}{p\left(y_{t+1},x_t, y_t \right)\log \frac{p\left(y_{t+1}|x_t,y_t \right)}{p\left(y_{t+1}|y_t \right)}} \\ =H \left(Y_{t+1}|Y_t \right)-H\left(Y_{t+1}|X_t,Y_t \right) \\ =I \left(Y_{t+1};X_t|Y_t \right)
TEX→Y=yt+1,xt,yt∑p(yt+1,xt,yt)logp(yt+1∣yt)p(yt+1∣xt,yt)=H(Yt+1∣Yt)−H(Yt+1∣Xt,Yt)=I(Yt+1;Xt∣Yt)
其中,
x
t
x_t
xt和
y
t
y_t
yt分别表示时间序列
X
X
X和
Y
Y
Y的历史观测值。
p
(
y
t
+
1
,
x
t
,
y
t
)
p\left(y_{t+1},x_t, y_t \right)
p(yt+1,xt,yt),
p
(
y
t
+
1
∣
x
t
,
y
t
)
p\left(y_{t+1}|x_t,y_t \right)
p(yt+1∣xt,yt)和
p
(
y
t
+
1
∣
y
t
)
p\left(y_{t+1}|y_t \right)
p(yt+1∣yt)分别表示联合概率密度函数和条件概率密度函数。转移熵越大表明
X
X
X到
Y
Y
Y的因果关系越强。
适用范围: 二变量平稳时间序列,非线性因果关系
2.2 多变量转移熵(偏转移熵)
基本原理: 考虑中间变量的影响,引入给定时间序列
Z
Z
Z的条件下,
X
→
Y
X \rightarrow Y
X→Y的转移熵为:
P
T
E
X
→
Y
∣
Z
=
∑
y
t
+
1
,
x
t
,
y
t
,
z
t
p
(
y
t
+
1
,
x
t
,
y
t
,
z
t
)
log
p
(
y
t
+
1
∣
x
t
,
y
t
,
z
t
)
p
(
y
t
+
1
∣
y
t
,
z
t
)
=
H
(
Y
t
+
1
∣
Y
t
,
Z
t
)
−
H
(
Y
t
+
1
∣
X
t
,
Y
t
,
Z
t
)
=
I
(
Y
t
+
1
;
X
t
∣
Y
t
,
Z
t
)
PTE_{X\rightarrow Y|Z}=\sum_{y_{t+1},x_t,y_t,z_t}{p\left(y_{t+1},x_t, y_t, z_t \right)\log \frac{p\left(y_{t+1}|x_t,y_t, z_t\right)}{p\left(y_{t+1}|y_t, z_t \right)}} \\ =H\left(Y_{t+1}|Y_t,Z_t \right) - H\left(Y_{t+1}|X_t,Y_t,Z_t \right) \\ =I\left(Y_{t+1};X_t|Y_t,Z_t \right)
PTEX→Y∣Z=yt+1,xt,yt,zt∑p(yt+1,xt,yt,zt)logp(yt+1∣yt,zt)p(yt+1∣xt,yt,zt)=H(Yt+1∣Yt,Zt)−H(Yt+1∣Xt,Yt,Zt)=I(Yt+1;Xt∣Yt,Zt)
适用范围: 多变量平稳时间序列,非线性因果关系
2.3 符号转移熵
基本原理: 将输入变量转化为秩向量,计算方式如2.1节所示。
适用范围: 二元非平稳时间序列,非线性因果关系
2.4 偏符号转移熵
基本原理: 将输入变量转化为排序后的秩向量,计算方式如2.2节所示。
适用范围: 多元非平稳时间序列,非线性因果关系
2.5 其他信息测度
(1) 基于条件熵的因果关系分析,可以看作是偏转移熵的归一化形式。
(2) 基于偏互信息的因果关系分析,在互信息的基础熵,引入条件变量,采用条件互信息检测因果关系。
…
适用范围: 多元非平稳时间序列,非线性因果关系
问题: 在实际应用中,如何解决输入变量维度增加造成高维概率密度函数计算困难的问题?
3 基于状态空间的时间序列分析
状态空间模型是一类线性或非线性的时域模型,用状态方程描述系统内部结构和信号的作用方向。可以利用状态变量表示一个时间序列,其包含了与预测值相关的所有历史信息。
状态空间模型参数估计方法主要有Kalman滤波,贝叶斯推理,EM模型。
3.1 非线性相互依赖指标
该指标是基于状态空间重构和近邻距离的方法。首先根据状态空间重构建立系统
X
\boldsymbol X
X和系统
Y
\boldsymbol Y
Y的状态空间,然后计算状态空间
X
\boldsymbol X
X中样本点
x
n
x_n
xn与
k
k
k个近邻点的欧氏距离平均值
R
n
(
k
)
(
X
)
R_n^{(k)}(\boldsymbol X)
Rn(k)(X),计算状态空间
Y
\boldsymbol Y
Y中的样本点
y
n
y_n
yn的
k
k
k个近邻点映射到状态空间
X
\boldsymbol X
X后与
x
n
x_n
xn的欧式距离平均值
R
n
(
k
)
(
X
∣
Y
)
R_n^{(k)}(\boldsymbol X| \boldsymbol Y)
Rn(k)(X∣Y),最后计算评价因果性的指标
S
S
S:
S
X
→
Y
=
1
N
∑
n
=
1
N
R
n
(
k
)
(
X
)
R
n
(
k
)
(
X
∣
Y
)
S_{\boldsymbol {X}\rightarrow \boldsymbol{Y}}=\frac{1}{N}\sum_{n=1}^N{ \frac{R_{n}^{\left ( k \right)} \left( \boldsymbol{X} \right)}{R_{n}^{\left( k \right)}\left( \boldsymbol{X}| \boldsymbol{Y} \right)}}
SX→Y=N1n=1∑NRn(k)(X∣Y)Rn(k)(X)
当
S
S
S处于0和1之间,趋近于0时,两个系统相互独立,明显大于0时,存在因果关系。
(非线性相互依赖指标有很多,可自行查阅)
适用范围: 二元非线性时间序列、平稳/非平稳时间序列
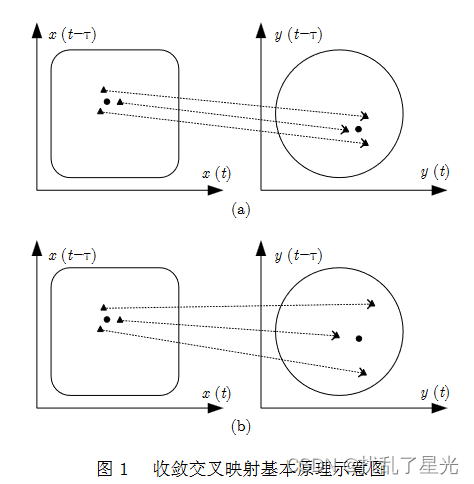
3.2 收敛交叉映射
基本思想: 如果系统 X \boldsymbol X X对系统 Y \boldsymbol Y Y有因果关系,则认为系统 X \boldsymbol X X中包含系统 Y \boldsymbol Y Y的演化信息,通过分析系统 X \boldsymbol X X和 Y \boldsymbol Y Y重构流形之间的相关性,进而检测出系统之间的因果关系。
如下图所示,图1(a)展示的为流形 X \boldsymbol X X的样本点 X ( i ) \boldsymbol X(i) X(i)及其邻近点映射到流形 Y \boldsymbol Y Y后,对应邻近点收敛于样本 Y ( i ) \boldsymbol Y(i) Y(i),表明存在由系统 Y \boldsymbol Y Y到系统 X \boldsymbol X X的因果关系;图1(b)中邻近点呈发散现象,不存在因果关系。
适用范围: 二变量非线性时间序列、平稳时间序列
参考文献: 任伟杰, 韩敏. 多元时间序列因果关系分析研究综述[J]. 自动化学报, 2021, 47(1): 64-78.














 2164
2164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









