







单层决策树:
基于单个特征来做决策,由于这棵树只有一次分裂过程,因此它实际上仅仅是一个树桩。
集成方法:
- 不同算法的集成;
- 同一算法在不同设置下的集成;
AdaBoost:
优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整。
缺点:对离群点敏感。
适用数据类型:数值型和标称型数据。
bagging 和boosting对比分析:
| 原理 | 差别 | |
| bagging | 从原始数据集选择S次后得到S个新数据集的一种技术。新数据集和原数据集的大小相等。每个数据集都是通过在原始数据集中随机选择一个样本来进行替换而得到的。这里的替换就意味着可以多次地选择同一样本,允许重复。(取出,放回)。将某个学习算法分别作用于每个数据集就得到S个分类器。每个分类器的权值相同 | 不同分类器是通过串行训练而获得的,每个分类器都根据已训练处的分类器的性能来进行训练 |
| boosting | 所有分类器加权求和结果,每个分类器的权值不同 | 集中关注被已有分类器错分的那些数据来获得新的分类器。 |
AdaBoost一般流程
- 收集数据:可以使用任意方法。
- 准备数据:依赖于所使用的弱分类器类型,本章使用的是单层决策树,这种分类器可以出来任何数据类型,当然也可以使用任意分类器作为弱分类器,作为弱分类器,简单分类器的效果更好。
- 分析数据:可以使用任意方法。
- 训练算法:AdaBoost的大部分时间都用在训练上,分类器将多次在同一数据集上训练弱分类器。
- 测试算法:计算分类的错误率
- 使用算法:同SVM一样,AdaBoost预测两个类别中的一个。如果想把它应用到多个类别的场合,那么就要像多类SVM的做法一样,对AdaBoost进行修改。
运行过程如下:
- 训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D。一开始,这些权重都初始化成相等值。
- 首先在训练数据上训练出一个弱分类器并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。
- 在分类器的第二次训练当中,将重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。
- 为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。
错误率 = 为正确分类的样本数据/所有样本数目
alpha = (1/2)ln((1-
错误率)/错误率)
样本权重更改:
正确时:
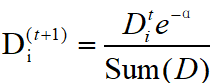
错误时:
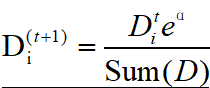
AdaBoost又开始进入下一轮迭代。AdaBoost算法会不断地重复训练和调整权重的过程,直到训练错误率为0或者弱分类器的数目达到用户的指定值为止。
adaboost.py
def loadSimpData():
datMat = matrix([[1.,2.1],[2.,1.1],[1.3,1.],[1.,1.],[2.,1.]])
classLabels = [1.0,1.0,-1.0,-1.0,1.0]
return datMat,classLabels
def draw(datMat,classLabels):
import matplotlib.pyplot as plt
x1,y1,x2,y2=[],[],[],[]
datMat = array(datMat)
for i in range(len(classLabels)):
if classLabels[i] == 1.0:
x1.append(datMat[i][0])
y1.append(datMat[i][1])
else:
x2.append(datMat[i][0])
y2.append(datMat[i][1])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(x1,y1,s = 30,c ='red')
ax.scatter(x2,y2,s = 30,c = 'green',marker = 's')
plt.show()
数据集分布:

找到具有最低错误率的单层决策树:
伪代码:
将最小错误率minError设为+oo
对数据集中的每一个特征(第一层循环):
对每个步长(第二层循环):
对每个不等号(第三层循环):
建立一个单层决策树并利用加权数据集对它进行测试
如果错误率低于minError,则将当前单层决策树设为最佳单层决策树
返回最佳决策树
#threshVal 阈值,将所有在阈值一边的数据分到-1,而另外一边的数据分到类别+1
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = ones((shape(dataMatrix)[0],1))#
if threshIneq =='lt':
retArray[dataMatrix[:,dimen] <= threshVal] =-1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = 1.0
return retArray#返回的是判断后各样本所属类别的结果
#目的是找到数据集上最佳的单层决策树
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0
bestStump = {}#空字典,单层决策树
bestClassEst = mat(zeros((m,1)))
minError = inf#错误率初始化为正无穷大,之后用于寻找可能的最小错误率
for i in range(n):#在数据集的所有特征上遍历
rangeMin = dataMatrix[:,i].min()
rangMax = dataMatrix[:,i].max()
stepSize = (rangMax-rangeMin)/numSteps#计算步长
for j in range(-1,int(numSteps) + 1):
for inequal in['lt','gt']:
threshVal = (rangeMin+float(j)*stepSize)#设置阈值
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T *errArr#分类器交互的地方
#计算加权错误率
# print(errArr,D)
# print("split: dim %d , thresh %.2f ,thresh inequal: %s ,the weighted error is %.3f \n"%(i,threshVal,inequal,weightedError),predictedVals)
if weightedError < minError:
minError = weightedError
bestClassEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClassEst
注意:weightedError = D.T * errArr能够计算出错误率的原因如下,D为样本权重向量,前面已把没有错误的errArr[]对应的位置设为0,根据矩阵乘法,错误率各权重相加之和即为错误率
得到结果如下图所示:
结果太长,相应省略了点。。。
生成S分类器:
伪代码:
对每次迭代:
利用buildStump()函数找到最佳的单层决策树
将最佳的单层决策树加入到单层决策数组
计算alpha
计算新的权重D
更新累积类别的估计值
如果错误率等于0.0,则退出循环
返回单层决策数组
def adaBoostTrainDS(dataArr,classLabels,numIt = 4.0):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m)#初始化样本权重
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error ,classEst = buildStump(dataArr,classLabels,D)
# print("D: ",D.T)
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
# print("classEst:",classEst.T)
#以下两行,为下一次迭代计算D
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon))
D = D/D.sum()
#以下五行,错误率累积计算
aggClassEst +=alpha *classEst
# print("aggClassEst:",aggClassEst.T)
aggErrors =multiply(sign(aggClassEst) !=mat(classLabels).T,ones((m,1)))
errorRate= aggErrors.sum()/m
# print("total error:",errorRate,"\n")
if errorRate == 0.0:
break
return weakClassArr
显示结果如下所示:

测试算法:
def adaClassfiy(datToClass,classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],classifierArr[i]['thresh'],classifierArr[i]['ineq'])#单层决策树下对于的类别结果
aggClassEst +=classifierArr[i]['alpha']*classEst
print(aggClassEst)
return sign(aggClassEst)
显示结果如下所示:
显示结果是各弱分类器权重与分类结果相乘之和。
非均衡分类问题
不同类别的分类代价并不相等。
其他分类性能度量指标:正确率、召回率及ROC
正确率:在所有测试样例中分对的样例比例
错误率:在所有测试样例中错分的样例比例(掩盖了样例如何被分错的事实)
混淆矩阵:也称为误差矩阵,是表示精度评价中的一种标准格式,用n行n列的矩阵形式来表示
召回率:
ROC(Receiver Operating Characteristic):接收者操作特征,用于度量分类中的非均衡性的工具
真阳率:TP/(FP+TN)
假阳率:FP/(TP+FN)
AUC(Area User the Crue)曲线下面积:对不同的ROC曲线进行比较的一个指标,给出的是分类器的平均性能值。
创建ROC曲线
- 将分类样例按照其预测强度排序;
- 先从排名最低的样例开始,所有排名更低的样例都被判为反例,而所有排名更高的样例都被判为正例;
- 将其移到排名次低的样例中去,如果该样例属于正例,那么对真阳率进行修改,如果该样例属于反例,那么对假阳率进行修改
def plotROC(predStrengths,classLabels):
#preStrengths代表分类器的预测强度
import matplotlib.pyplot as plt
cur = (1.0,1.0)#保留绘制光标的位置
ySum = 0.0#计算AUC
numPosClas = sum(array(classLabels) == 1.0)
yStrp = 1/float(numPosClas)#y轴上的步长,在0.0~1.0区间上绘点
xStep = 1/float(len(classLabels) - numPosClas)#x轴上的步长
sortedIndicies = predStrengths.argsort()
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0
delY = yStrp
else:
delX = xStep
delY = 0
ySum +=cur[1]
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY],c = 'b')
cur =(cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC curve for AdaBoost Horse Colic Detection System')
ax.axis([0,1,0,1])
plt.show()
print("The Area Under the Curve is:",ySum * xStep)
显示结果如下图所示:


基于代价函数的分类器的决策控制
总代价:TP*0 + FN*1 + FP*1 + TN*0(数字根据实际情况确定)
在构建分类器时,知道了这些代价值,那么就可以选择付出最小代价的分类器
处理非均衡问题是数据抽样方法
欠抽样:删除样例
过抽样:复制样例
抽样过程:随机或者某个预定方式来实现















 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









