









A Benchmarking Study of Embedding-based Entity Alignment for Knowledge
摘要:
实体对齐旨在在不同的知识图谱 (KG) 中找到指代现实世界中表示相同对象的实体。 基于嵌入的实体对齐在连续的嵌入空间中对实体进行编码,并根据学习到的嵌入来衡量实体的相似性。在本文中,我们对这一新兴领域进行了全面的实验研究。我们调查了最近 23 种基于嵌入的实体对齐方法,并根据它们的技术和特征进行分类。我们还提出了一种新的 KG 采样算法,通过该算法我们生成了一组具有各种异质性和分布的专用基准数据集,以进行实际评估。我们开发了一个开源库,包括 12 种代表性的基于嵌入的实体对齐方法,并广泛评估这些方法,以了解它们的优点和局限性。此外,对于当前方法中尚未探索的几个方向,我们进行了探索性实验并报告了我们的初步研究结果以供未来研究。基准数据集、开源库和实验结果都可以在线访问并得到适当维护。
1. INTRODUCTION
基于嵌入的实体对齐方法基于 KG 嵌入技术,将 KG 的符号表示嵌入为低维向量,捕获实体的语义相关性。图 1 描绘了基于嵌入的实体对齐的典型框架。
- 将两个不同的 KG 作为输入
- 使用owl:sameAs 链接等来源收集它们之间的种子对齐
- 将两个 KG 和种子对齐输入嵌入模块和对齐模块,以捕获实体嵌入的对应关系

嵌入模块和对齐模块有两种结合方式:
- 嵌入模块将两个KG编码为两个独立的嵌入空间,对齐模块用种子对齐学习他们的映射。
- 对齐模块指导嵌入模块将两个KG表达在统一的嵌入空间,具体做法为迫使种子对齐中的对齐实体的嵌入非常相似。
可以使用欧几里德距离等距离度量,通过对目标实体嵌入进行最近邻搜索来预测与源实体对齐的实体。 此外,针对种子对齐数量的不足,一些工作利用半监督学习来迭代增加新的对齐。
贡献:
1)综述:调研23个最近的基于嵌入的实体对齐方法,从不同角度分类他们的核心技术和特征。回顾了每个技术模块的流行选择,提供了该领域的简要概述。
2)基准数据集:为了公平和真实的比较,我们通过对现有KGs DBpedia,Wiki Data和YAGO进行抽样,综合考虑异质性的各个方面:实体的度、多语言、schema和数据规模,构建了一个5 folds专用基准数据集。 提出一种采样算法,使样本的属性(如度分布)接近其源 KG。
3)开源库:Python + TensorFlow。12个代表性的基于嵌入的实体对齐方法
4)探索实验:比较分析12种对齐方法。1.分析实体嵌入的几何特性,以了解它们与最终性能的潜在联系。 2.探索 8 个流行的尚未用于实体对齐的 KG 嵌入模型。 3.将基于嵌入的方法与几种传统方法进行比较,探索它们的互补性。
5)未来研究方向:对未来工作的几个有前途的研究方向提供了全面的展望,包括无监督实体对齐、长尾实体对齐、大规模实体对齐和非欧几里德嵌入空间中的实体对齐。
2. PRELIMINARIES
定义:
对齐两个KGs(KG1,KG2)的实体,他们的实体集分别为E1,E2。找到1对1的实体对齐S_{KG1,KG2} = {(e1, e2) ∈ E1 × E2 | e1 ∼ e2},∼表示等价关系,S_{KG1,KG2}的一个已知的对齐子集S’_{KG1,KG2}作为种子对齐,用于训练。
2.1 Literature Review
2.1.1 图谱嵌入表示 Knowledge Graph Embedding
方法:1)翻译模型:TransE,TransH,TransR,TransD;2)语义匹配模型:DistMult,ComplEx,HolE, SimplE, RotatE,TuckER;3)深度模型:ProjE, ConvE,R-GCN,KB-GAN,DSKG。
数据集:边预测基准数据集FB15K和WN18(测试泄露)衍生数据集FB15K-237和 WN18RR。
评测指标:1)Hits@m;2)正确边的平均排名mean rank(MR);3)平均倒数排名(MMR)
2.1.2 传统实体对齐 Conventional Entity Alignment
方法:1)基于 OWL 语义要求的等价推理;2)比较实体的符号特征的相似度计算。 最近的研究还使用统计机器学习和众包来提高准确性。 此外,在数据库领域,检测重复实体,即记录链接或实体解析,已被广泛研究 [16, 20]。 这些方法主要依赖于实体的字面信息。
本体对齐:OAEI2 http://oaei.ontologymatching.org/
评测指标:P,R,F1
2.1.3 基于嵌入的实体对齐 Embedding-based Entity Alignment
方法:1)翻译模型;2)图卷积神经网络GCN;3)利用属性与值嵌入;
数据集:无广泛应用基准数据集,应用较多的两个数据集DBP15K和WK3L的实体度与真实KG相差很大。
评测指标:Hits@m,MR 和 MRR,HITs@1等同与查准率P。
2.2 技术分类 Categorization of Techniques
2.2.1 嵌入模块 Embedding Module
关系嵌入:基于三元组(TransE)、基于路径(IPTransE,RSN4EA)、基于邻居(GCN)
属性嵌入:属性相关性 JAPE(不考虑属性文本特征),考虑文本特征学习属性嵌入(AttrE)
2.2.2 对齐模块 Alignment Module
距离指标:余弦、欧几里得(Euclidean)和曼哈顿距离(Manhattan)
对齐推理策略:贪心搜索arg mine2∈E2 π(e1, e2),全局搜索minΣ(e1,e2)∈SKG ,KG π(e1, e2)
2.2.3 交互模块 Interaction Mode
结合模式:
1)空间转换:将两个KG嵌入不同的嵌入空间,利用种子对齐学习两个空间之间的变换矩阵 M,使得种子对齐Me1≈e2;
2)空间校验:将两个KG编码到一个嵌入空间,最小化种子对齐的||e1-e2||来校准嵌入学习。有两种特殊方式:
- 参数共享,直接配置e1=e2;
- 参数交换,在三元组中交换种子实体,即如果KG1中存在三元(e1,r,t),则替换创建一个新三元组(e2,r,t)来共同训练。
学习策略:
1)监督学习:种子对齐作为训练集(种子对齐的获取非常困难)
2)半监督学习:在训练中使用未标记的数据,例如自训练和联合训练

3. 创建数据集 DATASET GENERATION
现有数据集与真实KG差异很大,此外,由于候选空间大且未分区,基于嵌入的方法很难在完整的 KG 上运行。 因此,我们对现实世界的 KG 进行采样并提供两种数据规模(15K 和 100K)。
3.1 基于度的迭代采样 Iterative Degree-based Sampling
从源 KG 生成特定大小的数据集,使其实体的度的分布的差异不超过预期。
基于度的迭代采样算法(IDS),只保留参考对齐中的实体,为了使实体度的分布接近真实分布,迭代的删除实体PageRank分数低的实体。
3.2 数据集概述 Dataset Overview
源KG:DBpedia,Wikidata,YAGO
参考对齐:DBpedia 的跨语言链接(英语-法语,英语-德语)和三个 KG 之间的 owl:sameAs
V1:直接用IDS算法
V2: 首先随机删除源KG中度数低(d≤5)的实体,使平均度增加一倍,然后执行IDS算法。 V2的密度是V1的两倍,与现有数据集更相似。

3.3 数据集评估 Dataset Evaluation
对比现有图抽样算法Baseline:随机抽样,PageRank抽样
结果:IDS抽样的数据集,与真实数据集更相似(平均度,度分布,密度)且没有离群实体。
4. OPEN-SOURCE LIBRARY
Python +TensorFlow
5. EXPERIMENTS AND RESULTS
5.1 实验设置
5.1.1 实验环境
| Intel Xeon E3 3.3GHz CPU | 128GB memory | NVIDIA GeForce GTX 1080Ti GPU | Ubuntu 16.04 |
|---|
5.1.2 交叉验证
5-fold交叉验证,保证无偏验证。将参考实体对齐均分成不相交的5份。
5.1.3 比较方法与参数设置
比较OpenEA中的所有方法。
常规参数如下表。

每个方法的特定参数按照原文设定。原文章未标明的参数通过调参设定。
5.1.4评估指标
Hits@m(m = 1, 5),MR ,MRR 。
5.2 主要结果与分析
表5描述了12种方法的Hits@1, Hits@5和MRR结果。RDGCN、BootEA和MultiKE的结果排前三名。
从五个角度分析结果:
5.2.1 稀疏数据集(V1)与密集数据集(V2)
大多数方法在密集数据集上的性能优于稀疏数据集。密集数据集中的实体通常涉及更多关系三元组,各方法能从中捕获更多语义信息。不同的是,MultiKE在V1和V2上表现差异不明显,因为它依赖于特征的多个“视图”,使得它对关系变化相对不敏感。另外MTransE和JAPE在密集的数据集上的性能有所下降。因为它们基于TransE,而TransE不适合处理密集数据集中1-N N-N的关系。
大多数实体的关系三元组相对较少,称之为长尾实体。实验结果显示,所有基于关系的方法在长尾实体上的结果会下降,因为长尾实体几乎没有可用于学习的信息,限制了它们嵌入的表达能力。使用额外的属性文本特征的方法,这种不平衡性能得到缓解。然而,使用属性相关性的JAPE和GCNAlign仍然在不同程度上显示了不平衡的表现。目前,我们还没有看到处理长尾实体的方法
5.2.2 15k数据集与100k数据集
各种方法在小规模数据集上的表现更好,因为大规模数据集的结构复杂,候选空间更大。
5.2.3 关系与属性
单纯基于关系的方法:
1)使用的嵌入技术对实体对齐的效果没有实际的影响;
2)负采样可以很大程度提升嵌入学习效果。
结合属性的方法:
1)属性异构性对获取属性相关性有很大影响;
2)属性文字嵌入有助于实体对齐。
5.2.4 半监督学习策略
比较半监督方法IPTransE、BootEA和KDCoE的精确度、召回率和F1分数。
- IPTransE效果最差,因为在持续进行自培训时,它会涉及许多错误,但没有设计消除这些错误的机制。
- KDCoE通过联合训练关系三元组和文本描述,来传播新的实体对齐。然而,许多实体缺乏文本描述,使得KDCoE无法找到对齐种子来增加训练数据。
- BootEA采用启发式编辑方法来消除错误对齐+bootstraping,取得了很好的效果。
半监督学习方法增加的实体对齐的数量和质量对半监督方法有很大影响。
5.2.5 运行时间比较
BootEA的运行时间明显长于其他方法,因为bootstraping
RSN4EA 由于基于长路径学习嵌入,运行时间要长于仅用三元组学习嵌入的方法
用附加本文特征的方法运行时间也长于仅考虑图特征的方法
6 拓展实验
6.1 几何分析
6.1.1 相似性分布
- top1对齐相似分数越大的方法,往往表现越好;
- 相似性分数方差越大的方法,往往表现越好。
6.1.2 枢纽与孤立 Hubbess and Isolation
枢纽问题是高维向量空间中的一种常见现象,其中一些点(称为中心点)经常作为向量空间中许多其他点的第一近邻出现。另外,任何点簇都会存在一些孤立点。这两个问题对依赖最近邻搜索的任务有负面影响。
较少出现Hubbness和isolation问题的方法,往往表现更好,可以通过分析Hubbness和isolation来估计最终的实体对齐性能。
为了解决Hubbness和isolation问题,我们探索了跨域相似局部缩放(CSLS)作为距离度量指标。它根据嵌入邻域的密度来归一化源实体和目标实体嵌入的相似性。以余弦为例,我们有:
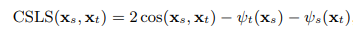
其中ψt(xs)表示源实体xs与其目标KG中的top-k近邻之间的平均相似性。
- LCSLS减少了中心实体和其他实体之间的相似性。
- 让一些孤立的实体在测试中得到公平考虑,因为它们通常会受到较少的相似性惩罚。
可使用CSLS来增强传统的距离度量。
此外,用全局角度检索实体对齐代替基于最近邻搜索的贪婪策略可以提升对齐的稳定性。
现有的方法集中于开发更强大的嵌入和交互方法,但是一些用于对齐模块的方法也可以提高性能。
6.2 探索未被用于实体对齐的KG嵌入模型
大多数现有方法使用TransE或GCNs进行KG嵌入,因为它们具有很强的鲁棒性和良好的通用性。然而,许多其他KG嵌入模型尚未被用于实体对齐。
评估一下KG嵌入模型实现实体对齐:
平移模型:TransH、TransR、TransD;
深度模型:ProjE、Conv
语义匹配模型:HolE、SimplE和RotatE。
选择MTransE作为基线,并用上述模型替换其关系嵌入模型TransE。
TransR和HolE的结果的Hits@1在大多数数据集的得分都小于0.01。
结果显示:
- 改进的翻译模型TransH和TransD比MTransE鲁棒性更好,并在大规模数据集(100K)上获得更好的结果。因为TransH可以更好地处理多重映射关系,还可以使用负采样来增强嵌入。
- TransR的结果更差了,因为TransR涉及关系对齐。在实体对齐问题上,KG模式之间的巨大异质性,关注的是实体对齐,而不提供关系对齐。
- 神经网络模型ConvI和ProjE在关系三元组较少,而关系数之间的差距较大。Conv的二维卷积或ProjE的非线性变换很难捕捉到这种异构KG中实体和关系嵌入之间的相似交互。
- 语义匹配模型,非欧几里德嵌入模型RotatE表现优于其他车型。
总之,并不是所有的KG嵌入模型都适用于实体对齐,非欧几里德嵌入值得进一步探索。
7. SUMMARY AND FUTURE DIRECTIONS
7.1 实验总结Summary of Experiments
- RDGCN,BootEA和MultiKE效果最好。表明结合文字信息和精心设计的对齐流程可以帮助实体对齐。
- 并非所有嵌入模型都适用于实体对齐。
- 对齐推理策略很少受到关注。实验的初步结果表明,CSLS距离度量和稳定匹配策略可以提高所有方法的性能。
7.2 未来方向 Future Directions
7.2.1 无监督实体对齐
在现实世界中,很难获得种子对齐。因此,研究无监督实体对齐是一个有意义的方向。一个可能的解决方案是结合附加特征或资源,并从中提取出远程监督信号,例如有判别力的特征(人的主页和产品的介绍性图像)和预先训练的词向量。此外,在无监督跨语言单词对齐方面的最新进展,如正交Procrustes和对抗性训练也值得研究。另一种可能的解决方案是使用主动学习或反绎学习来减轻数据标注的负担。
7.2.2 长尾实体对齐
长尾实体通常在KGs中占很大比例。为了嵌入长尾实体,除了使用更先进的图神经网络,还可以注入更多的特征,如多模态数据和分类系统。**由于KG还远未补全,通过统一框架联合训练链路预测和实体对齐可能会利用对这两项任务的附带监督。**从开放网络中提取额外信息以丰富长尾实体也是一个潜在的方向。
7.2.3 大规模实体对齐
受限于运行时间与对齐效果,基于嵌入(以及传统)的方法很难在非常大的KG上运行,因为候选空间非常大且没有分区。分块技术可能有助于缩小候选空间。
7.2.4 非欧几里德空间中的实体对齐
实验结果表明非欧几里德嵌入模型RotatE优于其他欧几里德模型。最近的非欧几里德嵌入已经证明了它们在表示图结构数据方面的有效性[53]。因此,面向对齐的非欧几里德KG嵌入模型值得开发。














 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









