






大家好,我是小士,很荣幸成为口袋AI算法小队的新成员。
我关注的方向主要是图网络和图采样算法。
最近在准备文章投稿,也趁这个机会和大家分享一些学习心得。
GNN理论研究中,最主流之一的方向就是GNN的表达能力研究。理论的东西总是显得高大上,让人望而却步。本文不会涉及理论证明,但是会用例子形象地带领大家理解这些GNN的理论到底在研究什么,最后又是如何指导我们实践的。本次带来的是GNN表达能力研究的开山之作《How Powerful are Graph Neural Networks? 》。
论文链接:
https://arxiv.org/pdf/1810.00826.pdf
什么是表达能力?
在深度学习中,深度神经网络最为我们熟知的理论就是它的万能逼近定理——多层感知机能拟合任意有限维Borel可测函数。这一定理指出了神经网络强大的表达能力。比如我们要做一个二分类任务,无论数据分布如何,总能找到一组合适的模型参数使得神经网络能将它们分开。
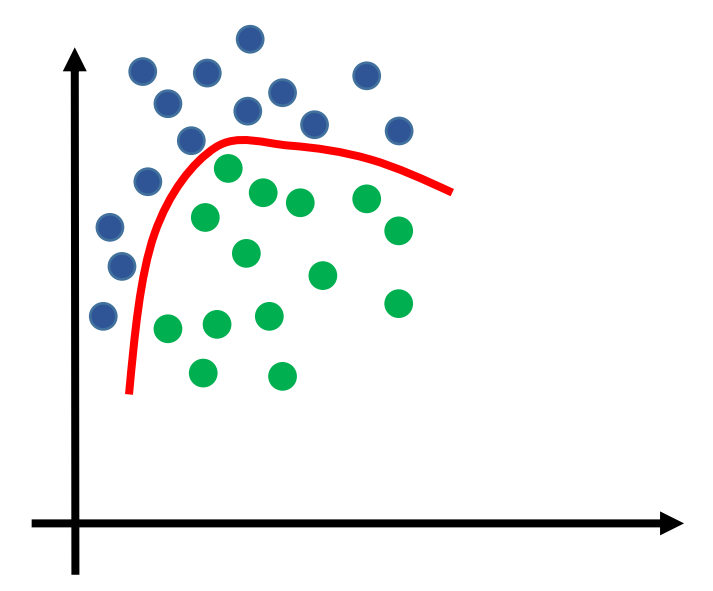
一个模型的表达能力就是它近似多么复杂的函数的能力。一个模型的表达能力过强的时候,我们还能通过一些正则项、Dropout等缓解过拟合的方法让它保持一定的泛化能力。但是一个模型表达能力不足的时候,我们很可能怎么训练模型都无法达到我们想要的效果,就像线性模型无论如何都无法将线性不可分数据区分开一样。这也是深度神经网络深受我们喜爱的原因之一。
深度神经网络的表达能力看似天下无敌了,却在图神经网络(GNN)这一领域被啪啪打脸。研究者们发现,在一些数据集上,无论怎么增大GNN的深度和宽度,GNN的表达能力始终存在一个瓶颈。总有一些图结构,当时的GNN模型怎么都区分不了。
为了讲清楚这个问题的来龙去脉,我们先介绍最常见的GNN框架,然后介绍这一框架下的GNN表达能力到底几斤几两,最后再说明这一理论给我们实践带来了哪些指导。
基于MPNN框架的GNN
GNN模型多得令人眼花缭乱,但是绝大部分模型可以纳入消息传递框架(Message Passing Neural Networks, MPNN)下,如GCN,GAT,和GraphSage等方法。MPNN目标是迭代地聚合(Aggregate)邻居节点的特征和结构消息(Message),更新(Update)节点表示。之后对于节点分类任务,我们直接基于这一节点表示来进行下游分类或回归任务;对于图分类任务,我们将节点表示池化为定长的图表示,再基于图表示进行下游分类或回归任务。
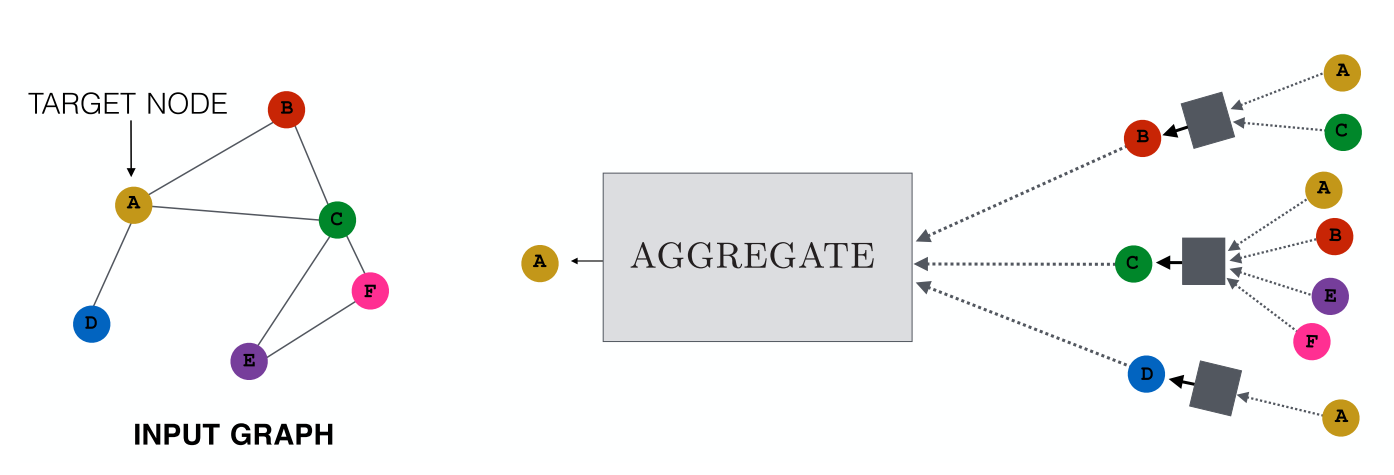
我们先介绍一些必要的定义:
- h u ( k ) \mathbf{h}_u^{(k)} hu(k):每一层的节点表示,第1层的节点表示就是节点的特征;
- N ( u ) \mathcal{N}(u) N(u):节点 u u u 的邻居组成的集合;
- m N ( u ) ( k ) \mathbf{m}_{\mathcal{N}(u)}^{(k)} mN(u)(k):对邻居节点的特征和结构进行聚合后得到的消息。
MPNN的计算方式如下:
h
u
(
k
+
1
)
=
UPDATE
(
k
)
(
h
u
(
k
)
,
AGGREGATE
(
k
)
(
{
h
v
(
k
)
,
∀
v
∈
N
(
u
)
}
)
)
=
UPDATE
(
k
)
(
h
u
(
k
)
,
m
N
(
u
)
(
k
)
)
\begin{aligned} \mathbf{h}_{u}^{(k+1)} &=\text { UPDATE }^{(k)}\left(\mathbf{h}_{u}^{(k)}, \text { AGGREGATE }^{(k)}\left(\left\{\mathbf{h}_{v}^{(k)}, \forall v \in \mathcal{N}(u)\right\}\right)\right) \\ &=\operatorname{UPDATE}^{(k)}\left(\mathbf{h}_{u}^{(k)}, \mathbf{m}_{\mathcal{N}(u)}^{(k)}\right) \end{aligned}
hu(k+1)= UPDATE (k)(hu(k), AGGREGATE (k)({hv(k),∀v∈N(u)}))=UPDATE(k)(hu(k),mN(u)(k))
其中的
UPDATE
(
k
)
\text { UPDATE }^{(k)}
UPDATE (k) 和
AGGREGATE
(
k
)
\text { AGGREGATE }^{(k)}
AGGREGATE (k) 两个函数没有明确的实现方式,我们允许它是任意函数。在MPNN框架中,模型可训练的参数就藏在
UPDATE
(
k
)
\text { UPDATE }^{(k)}
UPDATE (k) 和
AGGREGATE
(
k
)
\text { AGGREGATE }^{(k)}
AGGREGATE (k) 两个函数中,我们假设它们可以是任意函数已经给了GNN表达能力足够的支持,奈何MPNN框架不争气,在这样的假设下还是找到了MPNN区分不了的图。
MPNN和WL-test的关系
MPNN框架每一次迭代都会和邻居进行交互,看起来只要迭代得足够多,整张图的特征和结构信息都能被聚合起来。然而与直觉相反,一些很常见的图都区分不了,比如
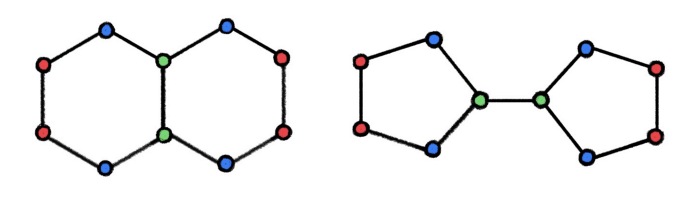
这张图是化学中常见的十氢化萘(左)和双环戊基(右)的分子结构。图中每个节点都是碳原子,节点的初始表示都是相同的,但是随着迭代,出现了三种节点表示,在图中分别用绿色、蓝色和红色表示。左右两边图的节点表示组成的多集(Multiset)都是 { 绿 2 , 蓝 4 , 红 4 } \{\text{绿}^2,\text{蓝}^4,\text{红}^4\} {绿2,蓝4,红4},这样无论如何池化得到的图表示也一定是完全相同的。无论多么强的分类器,总不可能对完全相同的输入输出两个结果,所以这两种图的预测结果总是完全一致的。但是在化学中,这两种分子的性质有很大不同。
尽管实际问题中存在这些MPNN框架区分不了的图,MPNN的表达能力也不能说很差,只能说是不够好。研究者们发现MPNN框架最多能达到传统图理论中的WL-test的图区分能力。WL-test算法被用来鉴别两种图是否同构,即输入两张图,输出它们是否是同一张图。图同构问题一直不是个简单的问题,它的精确计算复杂度未知,目前暂时被归入NP难问题中。WL-test本来被认为是图同构问题的多项式时间解,但是却在一年后被发现了反例。WL-test尽管不能严格区分所有图,但是区分绝大部分图是可行的。
如下是WL-test算法的迭代示意图:
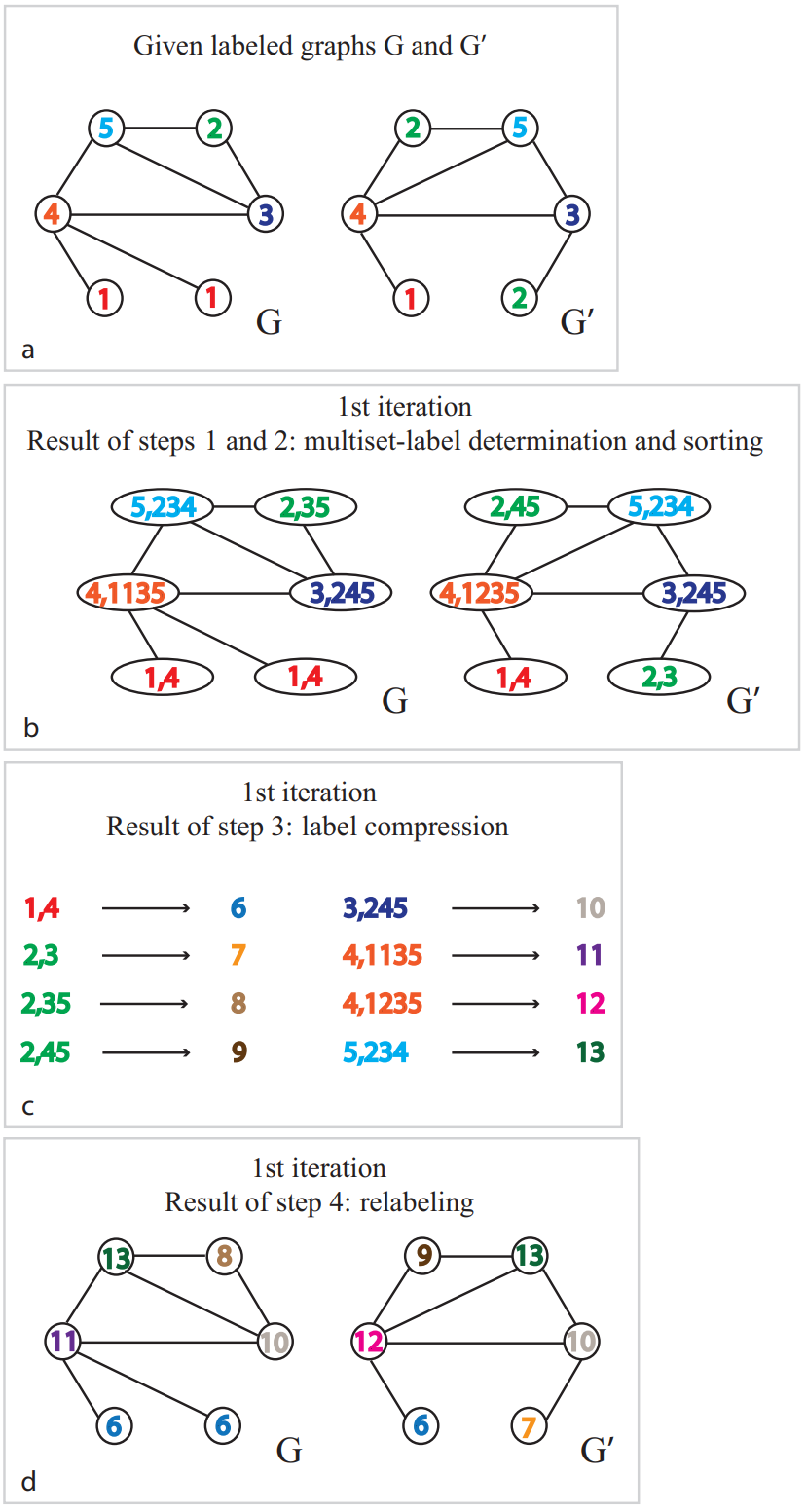
- ( a a a):开始迭代时两张图共有5种节点,标记为1到5;
- ( b b b):每个节点都和邻居节点交换各自的特征信息,通过聚合得到每个节点的多集(Multiset)表示,这一步相当于MPNN框架的 AGGREGATE ( k ) \text { AGGREGATE }^{(k)} AGGREGATE (k) 函数;
- ( c c c)和( d d d):最后通过Hash重新编码得到新的节点特征,这一步相当于MPNN框架中的 UPDATE ( k ) \text { UPDATE }^{(k)} UPDATE (k) 函数。
总结与思考
要应用GNN的表达能力理论来解决实际问题还有以下需要注意的点:
- MPNN框架下的GNN表达能力不弱。要进一步提升表达能力,就必须付出计算效率的代价,实践中需要权衡两者。目前计算高效、表达能力更强的GNN仍在研究中;
- GNN表达能力主要影响图分类/回归任务的性能。文献[1]的作者在Rebuttal中明确指出了这一点,我们的反例与分析也主要基于图分类任务。节点分类/回归任务还是要看GNN从邻居节点抽取特征的能力,一些Attention机制在这些任务上效果更好;
- 根据笔者的经验,化学方面的分子性质预测(图回归任务)的性能很大程度取决于GNN的表达能力,因为它们更加依赖图结构方面的信息。而一些图像方面的数据集却不怎么依赖,它们一般更加依赖模型的特征抽取能力。
引用
- [1] How powerful are graph neural networks? (ICLR 2019)
- [2] Multilayer feedforward networks are universal approximators. (Neural networks, 2(5):359–366, 1989)
- [3] Weisfeiler-lehman graph kernels. (JMLR 2011)
- [4] Expressive power of graph neural networks and the Weisfeiler-Lehman test.
(https://towardsdatascience.com/expressive-power-of-graph-neural-networks-and-the-weisefeiler-lehman-test-b883db3c7c49)















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









