







GNN理论学习(五)GNN的表达能力
前言
许多研究证明了前馈神经网络可以逼近任意感兴趣的函数,然而这个结论还没有推广到GNN中。这主要是由GNN参数空间中的附加限制引起的归纳偏置导致的。
本章中,先介绍了一种常用的GNN架构——Massage passing,然后介绍了MPGNN的优势和不足。随后,介绍了一种当前能够克服MPGNN在表达能力上的缺陷的技术,例如,附加随机属性(inject random attributes),附加绝对距离属性(inject deterministic distance attributes),构建高阶GNN(high-order GNN)等.
一、图表达学习(GRL)和问题公式化表达
1.什么是表达能力
将一个机器学习模型记为 f θ f_{\theta} fθ,该模型通过优化参数 θ \theta θ来逼近 f ∗ f^* f∗由于 f ∗ f^* f∗在实际中是未知的,所以期望 f θ f_{\theta} fθ能够逼近一个很宽范围的 f ∗ f^* f∗。一个模型能够逼近函数的范围的估计,被称为模型的表达能力(expressive power)。
Cybenko在1989年首次证明了定义在紧致空间上的连续函数可以一个只有一个隐藏层和一个Sigmoid激活函数的NN逼近。然而,这并不能够证明在训练过程中, f θ f_{\theta} fθ确实是在逼近 f ∗ f^* f∗的。图5.1展示了不同类型ML模型间,数据数量 与 ML模型性能的性能的关系。
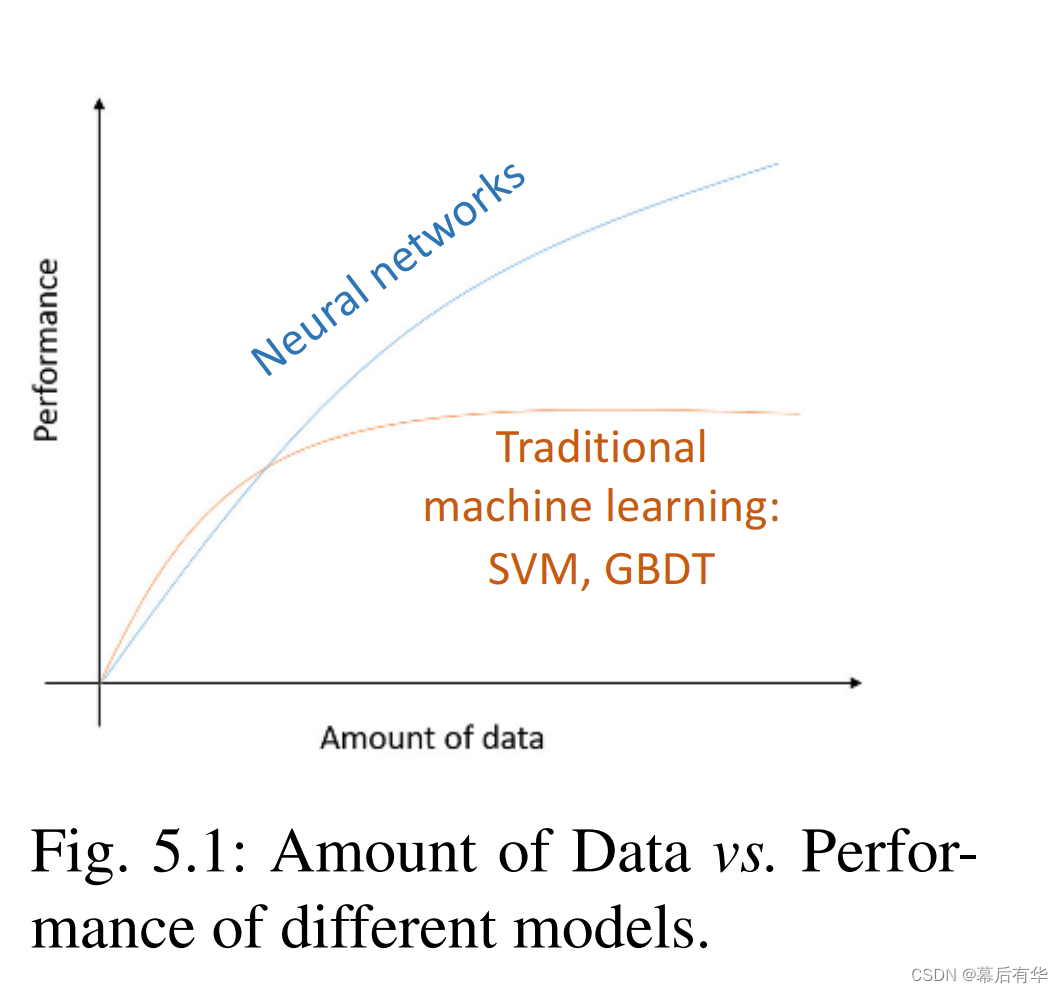
可以看出,只有在数据量足够大的时候NN的表现才能够超过传统的ML模型。一个重要的原因是,NN要进行数据量和模型复杂度之间的基本权衡。虽然NN可以具有更高的表达能力,但是当与更多的参数进行匹配时,NN很有可能会与训练样本过拟合。(数据量不足->参数过多->模型复杂->与训练样本过拟合)。所以有必要在对模型参数进行一些限制时,保持NN的表达能力。
在实际任务中,模型参数的限制通常时通过关于数据的先验知识得到的,这些模型的限制被称为**归纳偏置(inductive biases)**图5.2展示了有归纳偏置和没有归纳偏置可以显著影响模型的表达能力。

下面是对图5.2的一些解释(个人理解):
1.随着模型复杂度的增大,训练集错误率降低,测试集错误率升高,即出现过拟合现象。
2.实线是没有加入归纳偏置的测试集错误率和训练集错误率;虚线是加入了归纳偏置后的测试集错误率和训练集错误率。(这里应该是用测试集错误率越低来认定模型的表达能力越强)
3.最优的模型复杂度是取测试集错误率最低的时候的复杂度。从红线到×是单纯的通过增加模型复杂度来提高NN的表达能力,根据上面的介绍,这可能会导致模型过拟合,这也与图中测试集错误率升高对应。
4.从红线到⚪是通过在模型中加入归纳偏置来提高模型表达能力。可以看出,该方法没有
增大模型的复杂度,即不会出现过拟合现象,但是有效降低了测试集的错误率,即有效提高了模型的表达能力。
2.GNN的置换不变性
序列数据和图像数据是具有规整的结构的,但图数据是非常规数据,所以会GNN面临更多的挑战。在图机器学习中有一个基本假设:模型预测的目标应该与图中节点的顺序无关。为了匹配这一假设,GNN具有通用的归纳偏差(general inductive biases),即置换不变性(permutation invariance)。特别是,GNN的输出应该与如何分配图的节点索引无关,从而独立于节点的处理顺序。GNN的参数需要独立利于节点的顺序,并且参数应该在是整个图共享的。图5.4是置换不变性的一个示例。
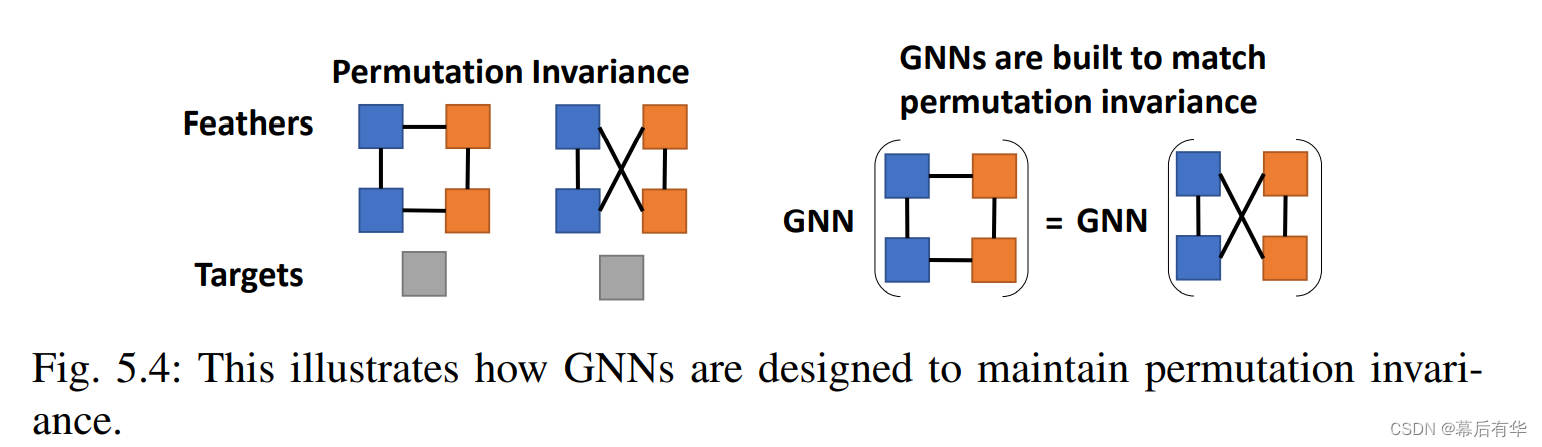
下面是对图5.4的一些解释(个人理解):每种颜色的节点表示一类节点,那么两张图的结构是一样的(每个节点均与1蓝1橙两个节点相邻),但是GNN对节点的索引不同。如果GNN满足置换不变性,那么两张图应该具有相同的输出,即右侧的结果。
3.图表达学习的公式表达
特征空间定义为 X : = Γ × f X: = \Gamma × f X:=Γ×f,其中 Γ \Gamma Γ是图结构数据空间, f f f包含所有感兴趣的节点. X X X中的一个点可以被记为 ( g , S ) (g,S) (g,S),其中 S S S是 g g g中感兴趣的节点的子集。我们将 ( g , S ) (g,S) (g,S)称为GRL样本。每一个 ( g , S ) ∈ Γ (g,S)\in \Gamma (g,S)∈Γ都对应一个目标空间 Y Y Y中的一个目标 y y y。
假设一个实际的联系两个空间的映射函数为 f ∗ : X → Y f^*: X \to Y f∗:X→Y,即 f ∗ ( g , S ) = y f^*(g,S)=y f∗(g,S)=y.给定一个训练集 Θ = ( g ( i ) , S ( i ) , y ( i ) ) i = 1 k \Theta = {(g^{(i)},S^{(i)},y^{(i)})} ^k _{i=1} Θ=(g(i),S(i),y(i))i=1k,测试集样本记为 Φ = ( g ~ ( i ) , S ~ ( i ) , y ~ ( i ) ) i = 1 k \Phi = {(\tilde{g} ^{(i)},\tilde{S}^{(i)},\tilde{y}^{(i)})} ^k _{i=1} Φ=(g~(i),S~(i),y~(i))i=1k。
GRL的目标是基于 Θ \Theta Θ学习一个函数以逼近基于 Φ \Phi Φ的函数 f ∗ f^* f∗
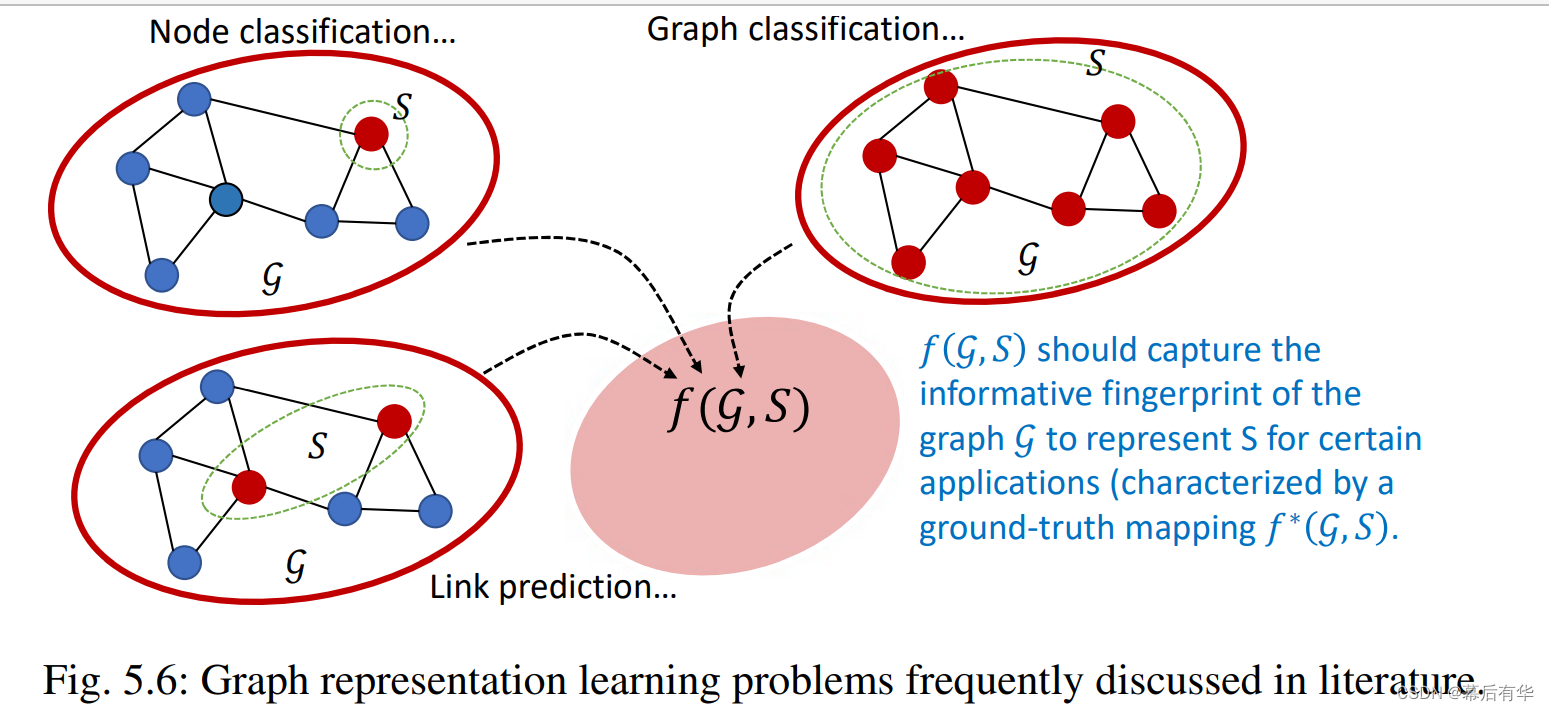
下面是几种可以表述为GRL问题的学习问题:
(1)图分类问题 / 图层次的预测问题:此时感兴趣的节点子集默认为整个节点集 V [ g ] V[g] V[g]图结构数据空间 Γ \Gamma Γ一般包含多个图。目标空间 Y Y Y包含不同图的标签。
(2)节点分类问题 / 节点层次的预测问题:此时, S S S默认为单个感兴趣的节点, g g g可以定义为 S S S周围的子图,或整个图。
**(3)连接预测问题 /节点配对层次的预测问题:**此时, S S S默认为感兴趣的一对节点,与节点分类问题类似, g g g可以定义为 S S S周围的子图,或整个图。目标空间 Y Y Y包含0-1标签来代指两个节点间是否有连接。 Y Y Y也可以推广到包含反应连接种类的标签。
图5.6给出了上述3类GRL问题的示例。
4.图表达学习的基本定义与基本假设
定义1:GRL样本同构
给定两个GRL样本 ( g ( 1 ) , S ( 1 ) ) (g^{(1)},S^{(1)}) (g(1),S(1)), ( g ( 2 ) , S ( 2 ) ) ∈ X (g^{(2)},S^{(2)}) \in X (g(2),S(2))∈X.假设 g ( 1 ) = ( A ( 1 ) , X ( 1 ) ) g^{(1)}=(A^{(1)},X^{(1)}) g(1)=(A(1),X(1)), g ( 2 ) = ( A ( 2 ) , X ( 2 ) ) g^{(2)}=(A^{(2)},X^{(2)}) g(2)=(A(2),X(2)).如果存在一个双射映射 π : V [ g ( 1 ) ] → V [ g ( 2 ) ] \pi : V[g^{(1)}] \to V[g^{(2)}] π:V[g(1)]→V[g(2)],也就是 A u v ( 1 ) = A π ( u ) π ( v ) ( 2 ) A^{(1)}_{uv}=A^{(2)}_{\pi{(u)}\pi{(v)}} Auv(1)=Aπ(u)π(v)(2), X u ( 1 ) = X π ( u ) ( 2 ) X^{(1)}_{u}=X^{(2)}_{\pi{(u)}} Xu(1)=Xπ(u)(2),同时 π \pi π也给予了 S ( 1 ) S^{(1)} S(1), S ( 2 ) S^{(2)} S(2)之间的双射映射。那么,我们认为 ( g ( 1 ) , S ( 1 ) ) (g^{(1)},S^{(1)}) (g(1),S(1))和 ( g ( 2 ) , S ( 2 ) ) (g^{(2)},S^{(2)}) (g(2),S(2))是同构的(Isomorphism),记作 ( g ( 1 ) , S ( 1 ) ) ≅ ( g ( 2 ) , S ( 2 ) ) (g^{(1)},S^{(1)})\cong (g^{(2)},S^{(2)}) (g(1),S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









