






一、模型转换pytorch->torchscript
python tools/export_libtorch.py -n yolox-s -c weights/best_ckpt.pth.tar
二、libtorch环境配置
其实也没有啥配置的,因为libtorch官方已经帮我们编译好了,直接下载下来用即可,到torch的官网中下载,然后解压即可,注意:一定要与模型转换的PyTorch版本一致,我使用PyTorch1.8.2版本OK
可以简单写一个程序简单测试一下是否能正常使用libtorch,创建libtorch_test.cpp文件,写入以下内容:
#include <iostream>
#include "torch/torch.h"
#include "torch/jit.h"
int main() {
std::cout << "Hello, World!" << std::endl;
auto a = torch::tensor({{1, 2}, {3, 4}});
std::cout << a << std::endl;
return 0;
}
CMakeLists.txt如下:
find_package(PythonInterp REQUIRED)
cmake_minimum_required(VERSION 3.16)
project(Libtorch_test)
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_PREFIX_PATH /home/cai/github/libtorch) # 这里写刚才的libtorch保存的路径
find_package(Torch REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_executable(Libtorch_test libtorch_test.cpp)
target_link_libraries(Libtorch_test ${TORCH_LIBRARIES})
如果使用VS,需要VS 2019,选择支持C++14,否则会有各种报错
VS2019设置C++项目目录,include lib并设置link
编译后如果得到如下结果,则为可以正常使用
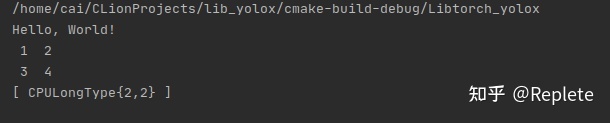
三、 使用libtorch调用torchscripts模型
因为yolox是anchor-free的,所以它的后处理部分非常的友好,没有yolov5这么复杂,以coco 80类来说,输出依旧是85个通道,和yolov5是一样的,同样是(中心点(2)+宽高(2)+置信度(1)+分类(80)= 85),不同的是少了anchor,得到的偏移量反算到原图上的时候要简单一些。
新建一个main.cpp文件,直接上代码吧,与ncnn和tensorrt代码的区别主要在与图像的前处理和推理部分,网络输出后的后处理部分代码基本上都是一致的,但是因为不同框架输出的数据类型不同,所以也要做对应的修改:
int main() {
const char* imagepath = "../dog.jpg";
torch::jit::script::Module model;
try {
model = torch::jit::load("../yolox.torchscript.pt");
model.to(at::kCUDA);
}
catch (const c10::Error& e) {
cerr << "error loading the model\n";
return -1;
}
Mat image = imread(imagepath);
Mat image_copy = image.clone();
if (image.empty()) {
cout << "Eroor: Could not load image" << endl;
return -1;
}
double time0 = static_cast<double>(getTickCount());
float scale = std::min(INPUT_W / (image.cols * 1.0), INPUT_H / (image.rows * 1.0));
image = narrow_640_pad(image, scale);
torch::Tensor tensor_image = torch::from_blob(image.data, { 1,image.rows,image.cols,3 }, torch::kByte);
tensor_image = tensor_image.permute({ 0,3,1,2 });
tensor_image = tensor_image.toType(torch::kFloat);
tensor_image = tensor_image.to(at::kCUDA);
//模型未处理
//tensor_image = tensor_image.div(255) - 0.5;
//tensor_image = tensor_image.div(0.5);
torch::Tensor result = model.forward({ tensor_image }).toTensor();
result = result.squeeze(0);
std::vector<Object> objects;
decode_outputs(result, objects, scale, image_copy.cols, image_copy.rows);
draw_objects(image_copy, objects);
//【5】计算运行时间并输出
time0 = ((double)getTickCount() - time0) / getTickFrequency(); //结束时间-开始时间,并化为秒单位
cout << "\t此方法运行时间为: " << time0 << "秒" << endl; //输出运行时间
return 0;
}
注意,模型训练时没有预先处理图像归一化,直接用RGB进行训练,所以推理时也无需预处理















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









