







赛道 B:信息流智能推荐算法中的序列评估问题
随着互联网信息的蓬勃发展,用户在使用互联网应用时面临着信息过载的问题。推荐算法的出现,满足了用户个性化的内容消费需求, 提升了用户获取有用信息的效率,在互联网 APP 里已被广泛应用。信息流作为推荐算法的主要应用场景,是用户触达互联网信息的主要入口,已经完全融入了人们的日常生活中,成为了人们了解世界的主要方式。
图 1 为信息流产品示例。该示例中,用户在执行刷新操作后,推荐系统返回了 K 条推荐结果,构成了一个推荐序列。其中前 4 条推荐内容占满了一个手机屏幕,用户继续下滑可浏览剩余内容。一个推荐 序列由多种内容类型构成,例如,内容 1 为图文内容,内容 4 为视频内容。需要说明的是,推荐系统每次返回的内容条数 K 可以是不固定的,系统可以根据用户的具体请求环境进行动态调整,以此得到最佳的用户浏览体验,如何确定 K 的大小在本题目中不做讨论。

图 1 信息流产品示例
传统推荐算法的核心思想是挖掘被推荐内容与用户兴趣的匹配 关系,以及内容本身的优质程度,选择与用户最相关或者最优质的内容推荐给用户。如图 2 中(a)所示,推荐系统会对单条候选内容进行打分评估,通过内容是否匹配用户兴趣以及内容质量的高低,来预估给用户推荐这条内容后带来的综合收益大小(综合收益通常包含用户是否会点击这条内容,以及用户在这条内容上的浏览时长)。系统 打出的分值则是对每条内容带来的综合收益大小的刻画。然后,系统选择出预估分值最大的 K 条内容,并按照分值从大到小的顺序推荐给用户。这种推荐方式我们称之为 point wise。
但是,研究发现,除了内容本身因素以外,内容之间的排列组合关系,也会影响用户的浏览体验,进而影响推荐收益的大小。例如, 相似内容的高度集中,往往会带来较差的结果反馈,即使它们都高度匹配用户兴趣或者具有较高的内容质量。于是,越来越多的研究集中在如何选择最优的内容排列组合上,而不仅仅是最优的内容上。如图
2 中(b)所示,同样的 ABC 三条内容,按照不同的顺序(A→B→C、
A→C→B、……)推荐给用户,会带来不一样的收益大小。推荐系统需要先根据候选内容生成候选推荐序列,然后对每一个候选序列进行打分评估,系统打出的分值则是对每个序列带来的整体综合收益大小的刻画。最后,系统选择出预估分值最高的一个序列,按照该序列的排列顺序将内容推荐给用户。这种推荐方式我们称之为 list wise。本题目要求参赛者设计数学模型对给定的候选序列进行序列整体收益评估。
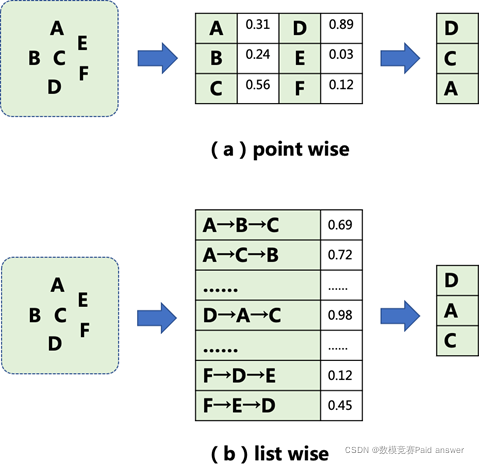
图 2 单内容评估和序列评估
题目提供近一周时间内用户在信息流产品上的曝光历史
(train_data.txt)作为训练集,以供参赛者进行建模分析。附件中 的 train_data.样例.txt 给出了数据格式示例,方便参赛者查看。涉及字段包括:
-
用户 ID:用户唯一标识,例如 1000024368;
-
请求 ID : 用户单次请求推荐服务的唯一标识,例如
500012184_1635188998881_5305;
-
日期:用户单次请求推荐服务的日期,例如 20211026;
-
时间:用户单次请求推荐服务的时间,例如 22(代表晚上 22
点);
- 推荐序列:用户单次请求推荐服务,推荐服务返回的内容列表。内容的排列顺序即为内容的真实推荐顺序,多个内容之间用
“;”分隔,单个内容包括三个字段:内容 ID、用户是否点击
(0 代表未点击,1 代表点击)、用户浏览时长(单位为秒),
多 个 字 段 之 间 用 “ : ” 分 隔 。 例 如133672454001:0:0;508896132:1:111;508969800:0:0;50887
0333:1:10;
同时,题目提供内容的基础属性(doc_info.txt)。附件中的
doc_info.样例.txt 给出了数据格式示例。涉及字段包括:
-
内容 ID:内容的唯一标识,例如 133342615958;
-
内容类型:推荐内容分为视频(v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6242
6242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









