









知识点十:熵的与决策树
1、熵的起源,熵的计算
信息论最初所处理的问题是数据压缩与传输领域中的问题,其处理方法利用了熵和互信息等基本量,它们是通信过程的概率分布的函数。

2、信息增益的计算(摘自网络)
在划分数据集之前之后信息发生的变化称为信息增益。
举一个的例子:对游戏活跃用户进行分层,分为高活跃、中活跃、低活跃,游戏A按照这个方式划分,用户比例分别为20%,30%,50%。游戏B按照这种方式划分,用户比例分别为5%,5%,90%。那么游戏A对于这种划分方式的熵为:
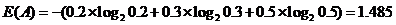
同理游戏B对于这种划分方式的熵为:
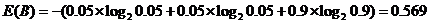
游戏A的熵比游戏B的熵大,所以游戏A的不确定性比游戏B高。用简单通俗的话来讲,游戏B要不就在上升期,要不就在衰退期,它的未来已经很确定了,所以熵低。而游戏A的未来有更多的不确定性,它的熵更高。
介绍完熵的概念,我们继续看信息增益。为了便于理解,我们还是以一个实际的例子来说明信息增益的概念。假设有下表样本

第一列为QQ,第二列为性别,第三列为活跃度,最后一列用户是否流失。我们要解决一个问题:性别和活跃度两个特征,哪个对用户流失影响更大?我们通过计算信息熵可以解决这个问题。
按照分组统计,我们可以得到如下信息:
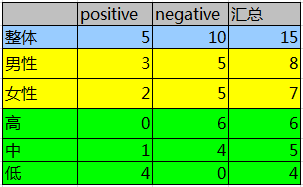
其中Positive为正样本(已流失),Negative为负样本(未流失),下面的数值为不同划分下对应的人数。那么可得到三个熵:
整体熵:
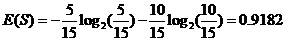
性别熵:
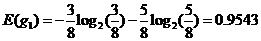
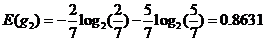
性别信息增益:
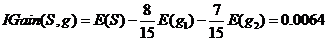
同理计算活跃度熵:
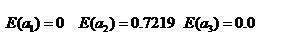
活跃度信息增益:
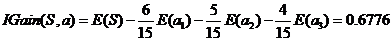
活跃度的信息增益比性别的信息增益大,也就是说,活跃度对用户流失的影响比性别大。在做特征选择或者数据分析的时候,我们应该重点考察活跃度这个指标。
3、数据的划分
数据的划分,依据信息增益,而信息增益的核心在于计算信息,而信息是概率的函数。所以,数据的划分落脚地还是概率。牢牢抓住划分之后的概率,对概率敏感,才能从容的计算出信息增益。
4、境界的提升(需要重点领会)
在境界上,概率是频率提升。同样道理,在境界上,熵是概率的提升。要做到:看到概率,里面想到熵。















 1387
1387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









