







熵权法中的熵值计算公式如图所示:

比如说某个评价的指标完全一样,1,1,1,1,1,1
那么m=6,p1到p6的概率均等于1/6;这个时候的熵值是最大的;所以在计算指标权重时,用这种方法反而是数据越小越混乱;权重越大;所以计算权重时都需要将1-ent值;这里的本质是已经将类别分好的,这里的数值代表属于该类别的样本个数;
而我在决策树算法中看到的熵值,
m=2,p1=1(值为1的是一类);p2=0,得到的熵值最小为0;数据完全有序;
熵值越大,数据越混乱越无序的结论没有错;当初的疑问是一个指标数据完全一样时,权值肯定为0,那其熵值肯定也为0,数据越乱必然熵值越高,权重也越高;但根据该公式的结论是熵值越大越有序,熵值越小越无序,权重越高;完全混乱了;
本质在于计算的p值方法不同;一种按类别计算的概率(决策树),我根据指标的值不同进行分类,然后计算概率;另一种是用每行都是一个类别,而每列对应的值是属于该类别的数量;
熵权法有一个弊端:如果某个评价指标全为一样的,会将所有数据置0,那么根据如下公式: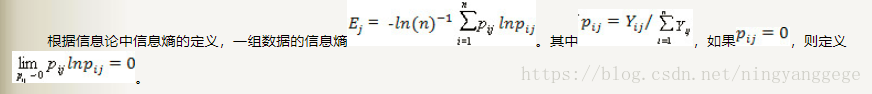
那么这个评价指标的所有信息熵都为0,那么数据就无序到了极致;其实这种情况就与本意相反;
个人的处理意见是如果这一列的原始数据全是相同的,如果不为0的话,就不用进行标准化,直接进行信息熵的计算,就会得出信息熵为1,最终权重为0 ,符合实际情况;如果全为0,就加1,重复前面的;
或者从根本上来说直接删除数据完全一样的列,因为该列不会有任何价值

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









