









文章目录
基于Python的系统性能优化经验总结
性能优化这个话题很大,这里只分享一些自己浅薄的性能优化经验,希望能抛砖引玉,欢迎大家交流分享。
1. 代码写法上优化
python作为一个翻译型语言,经常能发现,同样的功能换个写法就有几十上百倍的提升,以下列出几种常见的
1.1 使用推导式(Comprehension)
举个例子加以说明
scale = int(1e7)
# 不用推导式
s = time.time_ns()
res = []
for i in range(scale):
res.append(i * i)
print(time.time_ns() - s) # 922763000 单位ns
# 推导式
s = time.time_ns()
res = [i * i for i in range(scale)]
print(time.time_ns() - s) # 802135800 单位ns
可见推导式显著要比普通写法快
1.2 用变量代替属性
当一个实例属性被反复引用时最好使用临时变量将属性值取出再使用临时变量,因为实例getattr会引入额外耗时。
举例说明:
scale = int(1e7)
a = A()
s = time.time_ns()
for i in range(scale):
x = a.echo + 1
print(time.time_ns() - s) # 451374400 单位ns
s = time.time_ns()
e = a.echo
for i in range(scale):
x = e + 1
print(time.time_ns() - s) # 336747000 单位ns
1.3 能inplace就不copy
例如Dataframe一般inplace操作比copy一份再操作要快
1.4 善用copy
对于一些数据结构,当我们想要一个一样的实例的时候,有些时候copy要比重新初始化一个要更快
1.5 向量化思维
处理数据时需要习惯思考如何向量化的操作,而不是一味地用forloop解决问题。
举例:对一列数据df判断是否严格递增,df[1:, x] > df[0:n-1, x]即可,核心思想是错位比较。
1.6 lazy化思维
lazy化可以让用户真正想要结果时才把所有操作一次性实现,而中间过程只需要用数据结构记录需要的操作即可。
等等等
还有很多细节,不一一列举
2. 算法上优化
核心指标:时间复杂度,而且要合理利用空间换时间
3. 从需求入手,精简逻辑
往往功能越单一的代码运行起来越快,因此做需求的时候充分理解需求,限制上下游的输入输出,能够帮我们简化代码逻辑(不必要的功能、输入兼容等)。而且限定了场景,更能方便技术人员做专门的优化。
4. 对性能极限有概念
对常见场景的性能极限有量级概念会帮助我们在优化时量化我们程序性能表现,知道还有多大的优化空间。下面以python的一些基础操作为例。
注:测试环境
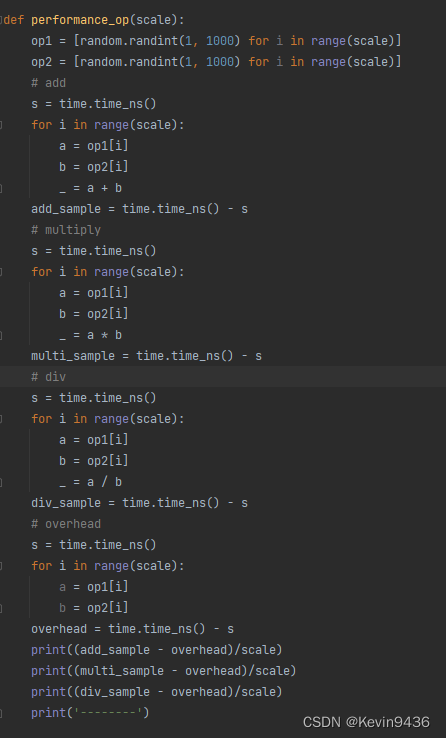
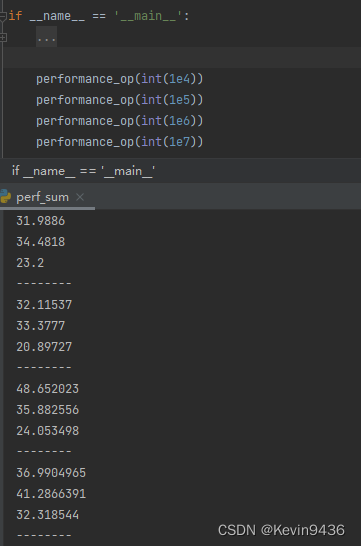
4.1 加减乘除
单次大概在30-40ns
验证:
结果:
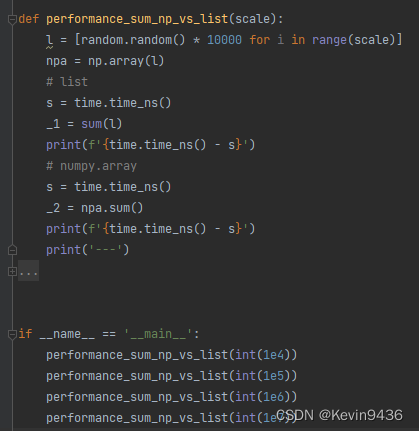
4.2 列表求和
python原生列表百万量级求和在ms级别,numpy大概在百微秒级别。可以看到numpy比原生列表操作要快很多。
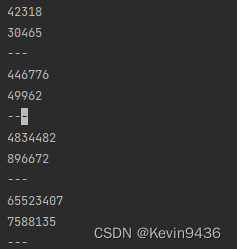
4.3 字典搜索
python字典搜索大概在百纳秒级别
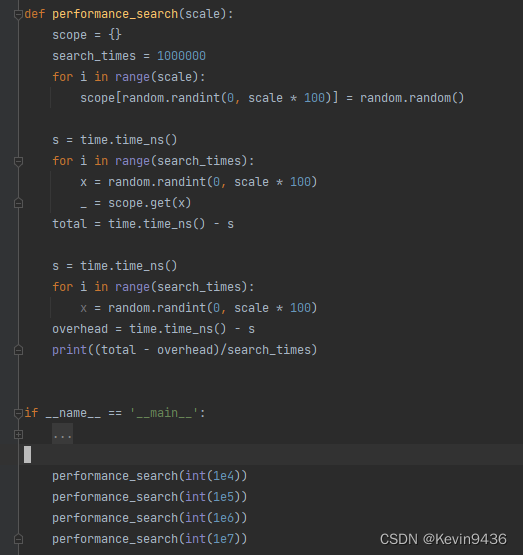
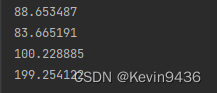
待补充
5. 优化缓存策略
5.1缓存位置
将请求数据缓存下来便于下次请求时加速响应是一个很正常的思想。在常见的系统模型中请求链路:
客户端 - (中台)- 后台服务 - 数据存储
显而易见,缓存位置越靠前,命中缓存时响应速度越快。
不过缓存是一把双刃剑,例举缓存带来的几个问题:
a. 对于有一定时效性需求的数据,如何更新缓存
b. 缓存不能无限制增长,如何设置淘汰策略
c. 对于分布式系统,如何保证数据的一致性
可见缓存会引入维护成本,且缓存位置越靠前,维护成本越高,出错的可能性也越高
因此需要根据业务场景合理设置缓存策略,比如客户端只访问历史数据且一个批次请求有一定规律,则可以考虑在客户端缓存。
5.2 缓存内容
缓存的内容并不一定是最终返回的结果,也可以是一个批次的整个数据集,也可以是一些中间结果。
举个例子:
我有对一个数据集有十万个请求,每次请求可能是不同行的不同列。
如果只缓存每个请求的最终结果可能会导致缓存命中率低,而大大增加io次数。
那我可以把整个数据集全部缓存,或者如果请求有一定范围规律可以部分数据块缓存,这样能显著降低io次数,且如果处理得当,在内存中搜索也会更快。
6. 更换技术选型
技术选型topic比较大且对已有系统的冲击也比较大,所以放在最后。虽说在项目开始开发之前就应该做好技术选型,但是毕竟技术在不断发展,会不断有新的性能更好的技术出现,因此更换技术选型也是需要考虑的可能性之一,同时这也敦促我们开发人员要保持学习。
总结
系统性能优化是一个很复杂的问题,不仅需要我们能够深入每个系统节点,还需要我们具备一定的全局视角,优化过程中也需要一定的专业知识和经验做支撑,相应地这个过程也会带给我们很多的学习思考,是很好的技术成长机会。

















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











