







1多gpu训练预期
两张卡模型3090和4张差距较小
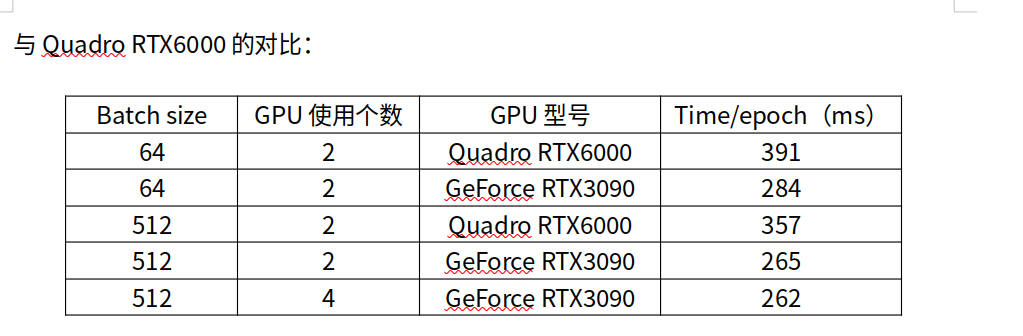
1benchmark模型过于简单,主要时间是cpu和gpu之间的通信时间
2内存速度不快,增加通信时间,主要时间花在通信上
3batchsize不高时,就算修改多显卡有时候也只会用一块
4多显卡要有代码修改优化器
from keras.utils import multi_gpu_model

5 x16 主板槽位不对用的x8
nvidia-smi -a |grep -i current
转载
http://blog.s-schoener.com/2017-12-15-parallel-tensorflow-intro/
1训练速度与使用的 GPU 数量不成线性关系。这里有多种因素在起作用:您能否以足够快的速度加载数据以提供给连接到您系统的所有 GPU?您模型的运行时间是否足以隐藏将权重从控制器传输到设备的延迟?当您的控制器应用梯度更新时,您的设备在做什么?
2其次,假设我们采用第二种方法,变量的同步如何跨模型工作?这取决于您的设置:在网络设置中,您可能会使用 TensorFlow 的多个实例(在图形复制之间),其中一个(或多个)被指定为参数服务器。如果您的本地机器上有多个设备,最好在单个 TensorFlow 实例(图内复制)中显式执行复制,并指定一个控制器设备(例如 CPU)来跟踪图中的变量。在训练期间,每个副本将执行前向传递,然后是反向传递,并将其梯度更新发送到控制器/参数服务器,控制器/参数服务器应用更新并将更新发送回设备。这可以同步发生(设备等待对方完成并始终使用相同的权重)或异步发生(设备运行时没有相互锁定,因此每个设备的参数可能略有不同)。异步训练可以减少训练时间,但已知会导致预测性能稍差。
import tensorflow as tf
Local Training with Multiple GPUs
在本节中,我们将使用带同步训练的图内复制来并行化安装在本地机器上的多个 GPU 上的模型训练。控制器设备将是 CPU,这意味着所有变量都将存在于该设备上,并将在每个步骤中复制到 GPU。我们将在这里使用的模型是 MNIST 分类器。请注意,该模型太小,无法从多 GPU 计算中获益——大部分时间将用于在 CPU 和 GPU 之间传输权重和训练数据。
def core_model(input_img, num_classes=10):
"""
A simple model to perform classification on 28x28 grayscale images in MNIST style.
Args:
input_img: A floating point tensor with a shape that is reshapable to batchsizex28x28. It
represents the inputs to the model
num_classes: The number of classes
"""
net = tf.reshape(input_img, [-1, 28, 28, 1])
net = tf.layers.conv2d(inputs=net, filters=32, kernel_size=[5, 5],
padding="same", activation=tf.nn.relu,
name="conv2d_1")
net = tf.layers.max_pooling2d(inputs=net, pool_size=[2, 2], strides=2)
net = tf.layers.conv2d(inputs=net, filters=64, kernel_size=[5, 5],
padding="same", activation=tf.nn.relu,
name="conv2d_2")
net = tf.layers.max_pooling2d(inputs=net, pool_size=[2, 2], strides=2)
net = tf.reshape(net, [-1, 7 * 7 * 64])
net = tf.layers.dense(inputs=net, units=1024, name="dense_1", activation=tf.nn.relu)
logits = tf.layers.dense(inputs=net, units=num_classes, name="dense_2")
return logits
和以前一样,我们将定义一个训练模型,将我们的核心模型转换为可以传递给优化器的损失。为了让事情更短,我们将简单地返回损失而不是其他任何东西。请注意这里的一个重要区别:该函数不是一个表示模型输入的张量,而是一个产生这种张量的函数。这对于稍后并行化模型至关重要,因为模型的每个副本都应该有自己的这样的张量。
def training_model(input_fn):
inputs = input_fn()
image = inputs[0]
label = tf.cast(inputs[1], tf.int32)
logits = core_model(image)
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=label, logits=logits)
return tf.reduce_mean(loss)
我们将采用稍微不正统(且效率低下)的捷径,以数据集 API 格式使用 Tensorflow 传输 MNIST 数据:
def training_dataset(epochs=5, batch_size=128):
from tensorflow.examples.tutorials.mnist import input_data
mnist_data = input_data.read_data_sets("data")
all_data_points = mnist_data.train.next_batch(60000)
dataset = tf.data.Dataset.from_tensor_slices(all_data_points)
dataset = dataset.repeat(epochs).shuffle(10000).batch(batch_size)
return dataset
我们现在可以像往常一样训练这个模型,然后再进入并行设置(跳过所有非必要步骤,如保存、摘要等):
def do_training(update_op, loss):
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
try:
step = 0
while True:
_, loss_value = sess.run((update_op, loss))
if step % 100 == 0:
print('Step {} with loss {}'.format(step, loss_value))
step += 1
except tf.errors.OutOfRangeError:
# we're through the dataset
pass
print('Final loss: {}'.format(loss_value))
def serial_training(model_fn, dataset):
iterator = dataset.make_one_shot_iterator()
loss = model_fn(lambda: iterator.get_next())
optimizer = tf.train.AdamOptimizer(learning_rate=1E-3)
global_step = tf.train.get_or_create_global_step()
update_op = optimizer.minimize(loss, global_step=global_step)
do_training(update_op, loss)
tf.reset_default_graph()
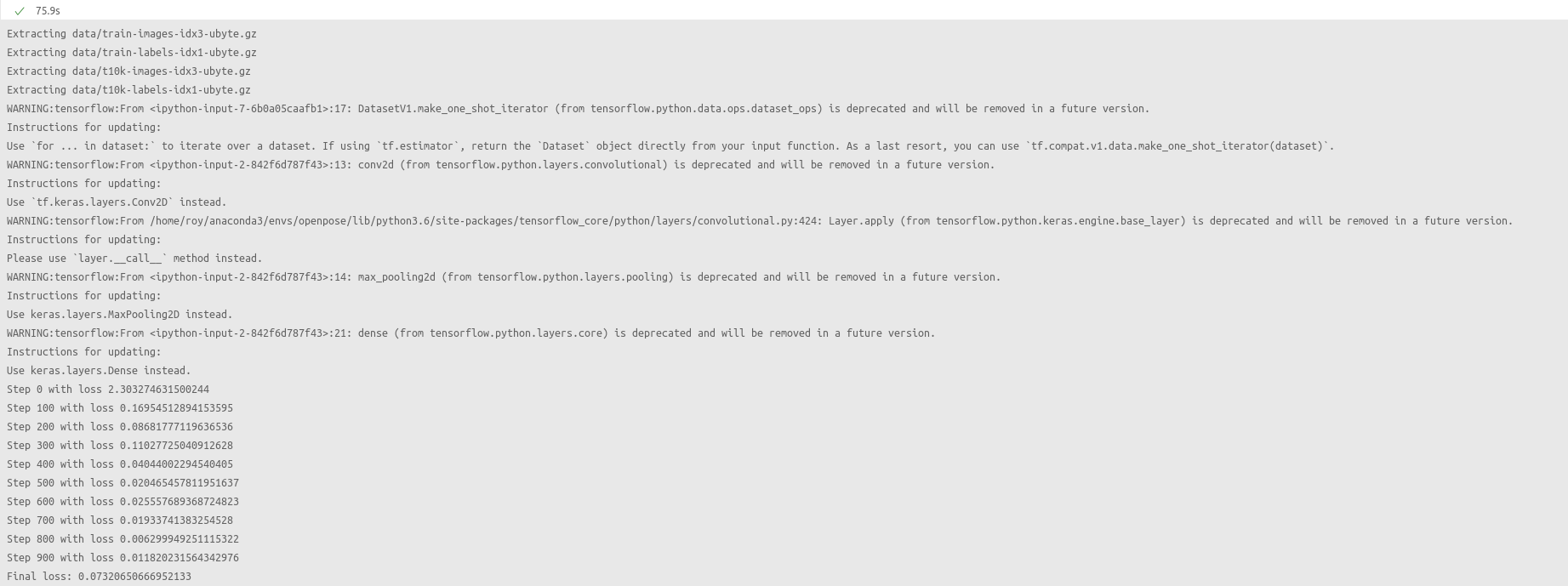
serial_training(training_model, training_dataset(epochs=2))
用时75.9秒
The Multi-GPU version
这是我们将要做的事情的简短路线图:
1我们将创建一个专门的训练函数,在多个设备上训练由其模型函数给出的模型,
2此函数将为每个设备创建一个模型副本(称为塔),并指示它计算向前和向后传递,
3然后梯度将被平均并应用到所有模型变量所在的控制器设备上。
这已经暗示了为什么并行性应该被视为训练过程的属性,而不是模型:我们需要将优化器的最小化步骤拆分为计算梯度(在设备上执行)和应用梯度(在控制器上运行)。因此,无论什么使并行训练工作都需要了解优化器!
这是最后的训练函数:所有的魔法都发生在 create_parallel_optimization 中,我们将慢慢朝着这个函数努力
def parallel_training(model_fn, dataset):
iterator = dataset.make_one_shot_iterator()
def input_fn():
with tf.device(None):
# remove any device specifications for the input data
return iterator.get_next()
optimizer = tf.train.AdamOptimizer(learning_rate=1E-3)
update_op, loss = create_parallel_optimization(model_fn,
input_fn,
optimizer)
do_training(update_op, loss)
为操作指定设备
TensorFlow 允许为您创建的每个操作指定一个设备。这通过使用 tf.device 起作用,如以下单元格中所示:
def device_example():
# allocate variables on the CPU
with tf.device('/cpu:0'):
M = tf.get_variable('M', shape=[10,8], dtype=tf.float32)
x = tf.get_variable('x', shape=[8, 1], dtype=tf.float32)
# perform the operation on the fi=rst GPU device
with tf.device('/gpu:0'):
y = tf.matmul(M, x)
由于我们设置中的所有变量都应该存在于控制器设备上,但所有操作都应该在操作设备上运行,我们可以事先显式分配所有变量(乏味!)或者利用 tf.device 也可以接受函数的事实作为它的参数:这个函数然后动态地决定将哪个操作放在哪里。
下面的函数允许我们为 tf.device 构造一个合适的参数,将所有变量放在控制设备上,并将其他所有变量放在我们选择的设备上
PS_OPS = [
'Variable', 'VariableV2', 'AutoReloadVariable', 'MutableHashTable',
'MutableHashTableOfTensors', 'MutableDenseHashTable'
]
# see https://github.com/tensorflow/tensorflow/issues/9517
def assign_to_device(device, ps_device):
"""Returns a function to place variables on the ps_device.
Args:
device: Device for everything but variables
ps_device: Device to put the variables on. Example values are /GPU:0 and /CPU:0.
If ps_device is not set then the variables will be placed on the default device.
The best device for shared varibles depends on the platform as well as the
model. Start with CPU:0 and then test GPU:0 to see if there is an
improvement.
"""
def _assign(op):
node_def = op if isinstance(op, tf.NodeDef) else op.node_def
if node_def.op in PS_OPS:
return ps_device
else:
return device
return _assign
我们可以使用与上面相同的示例来演示其用法:
def device_example_2():
# allocate variables on the CPU, perform the operation on the first GPU device
with tf.device(assign_to_device('/gpu:0', '/cpu:0')):
M = tf.get_variable('M', shape=[10,8], dtype=tf.float32)
x = tf.get_variable('x', shape=[8, 1], dtype=tf.float32)
y = tf.matmul(M, x)
def device_options():
config = tf.ConfigProto(log_device_placement=False, allow_soft_placement=True)
with tf.Session(config=config) as sess:
# your code here
pass
使用 TensorBoard 的图形视图,您还可以检查哪些操作放置在哪个设备上,但该视图仅显示静态信息(而不是 TensorFlow 的放置决策)。
def variable_scope_example():
with tf.variable_scope('test_scope'):
M = tf.get_variable('matrix1', shape=[10, 8], dtype=tf.float32)
x = tf.get_variable('matrix2', shape=[8, 1], dtype=tf.float32)
y = tf.matmul(M, x)
# Here, we are instructing TensorFlow to reuse to variables declared above.
# The `M` from above and the `N` from below reference the same Tensor!
with tf.variable_scope('test_scope', reuse=True):
N = tf.get_variable('matrix1', shape=[10, 8], dtype=tf.float32)
z = tf.get_variable('matrix2', shape=[8, 1], dtype=tf.float32)
w = tf.matmul(N, z)
有几点值得注意:
通过设置上面的重用=真,我们声明我们请求的所有变量都已经定义。我们不能在该范围内声明新的。
显然,我们必须确保变量的参数一致。例如,在上面的代码中,我们不能将 N 更改为在第二个作用域中具有形状 [10, 10],因为它已经以 [10, 8] 的形状存在。
在许多高级 API 的地方,变量作用域是自动创建的。当没有给出默认名称时,它们通常使用连续命名。变量重用仅在变量作用域具有完全相同的名称和路径时才有效,因此在使用 TFLayer 或 Slim 时始终命名您的图层。例如,以下不会重用变量:
def variable_scope_layers_failure():
input_tensor = tf.placeholder(dtype=tf.float32, shape=[1, 10, 10, 1])
with tf.variable_scope('test_scope'):
tf.layers.conv2d(input_tensor, filters=10, kernel_size=[5, 5])
# This will NOT reuse variables, since both `conv2d` implicitly create a variable scope with a
# fresh name. Add `name='layer_name'` to make it work.
with tf.variable_scope('test_scope', reuse=True):
tf.layers.conv2d(input_tensor, filters=10, kernel_size=[5, 5])
def variable_scope_layers_correct():
input_tensor = tf.placeholder(dtype=tf.float32, shape=[1, 10, 10, 1])
with tf.variable_scope('test_scope'):
tf.layers.conv2d(input_tensor, filters=10, kernel_size=[5, 5],
name='my_conv')
# This does what it is supposed to do since both convolutional layers have been given
# the same name
with tf.variable_scope('test_scope', reuse=True):
tf.layers.conv2d(input_tensor, filters=10, kernel_size=[5, 5],
name='my_conv')
除了设置reuse=True,我们也可以在作用域上调用reuse_variables来达到同样的效果。
def variable_scope_example_2():
with tf.variable_scope('test_scope') as vscope:
M = tf.get_variable('matrix1', shape=[10, 8], dtype=tf.float32)
x = tf.get_variable('matrix2', shape=[8, 1], dtype=tf.float32)
y = tf.matmul(M, x)
vscope.reuse_variables()
# variables are reused here
N = tf.get_variable('matrix1', shape=[10, 8], dtype=tf.float32)
z = tf.get_variable('matrix2', shape=[8, 1], dtype=tf.float32)
w = tf.matmul(N, z)
创建并行优化例程
现在我们准备组装零件。下面的代码还有一些未知数;我们将很快讨论它们:
def get_available_gpus():
"""
code from http://stackoverflow.com/questions/38559755/how-to-get-current-available-gpus-in-tensorflow
"""
from tensorflow.python.client import device_lib as _device_lib
local_device_protos = _device_lib.list_local_devices()
return [x.name for x in local_device_protos if x.device_type == 'GPU']
def create_parallel_optimization(model_fn, input_fn, optimizer, controller="/cpu:0"):
# This function is defined below; it returns a list of device ids like
# `['/gpu:0', '/gpu:1']`
devices = get_available_gpus()
# This list keeps track of the gradients per tower and the losses
tower_grads = []
losses = []
# Get the current variable scope so we can reuse all variables we need once we get
# to the second iteration of the loop below
with tf.variable_scope(tf.get_variable_scope()) as outer_scope:
for i, id in enumerate(devices):
name = 'tower_{}'.format(i)
# Use the assign_to_device function to ensure that variables are created on the
# controller.
with tf.device(assign_to_device(id, controller)), tf.name_scope(name):
# Compute loss and gradients, but don't apply them yet
loss = model_fn(input_fn)
with tf.name_scope("compute_gradients"):
# `compute_gradients` returns a list of (gradient, variable) pairs
grads = optimizer.compute_gradients(loss)
tower_grads.append(grads)
losses.append(loss)
# After the first iteration, we want to reuse the variables.
outer_scope.reuse_variables()
# Apply the gradients on the controlling device
with tf.name_scope("apply_gradients"), tf.device(controller):
# Note that what we are doing here mathematically is equivalent to returning the
# average loss over the towers and compute the gradients relative to that.
# Unfortunately, this would place all gradient-computations on one device, which is
# why we had to compute the gradients above per tower and need to average them here.
# This function is defined below; it takes the list of (gradient, variable) lists
# and turns it into a single (gradient, variables) list.
gradients = average_gradients(tower_grads)
global_step = tf.train.get_or_create_global_step()
apply_gradient_op = optimizer.apply_gradients(gradients, global_step)
avg_loss = tf.reduce_mean(losses)
return apply_gradient_op, avg_loss
那没那么难,是吗?
在这一点上,我应该指出 input_fn 已经为每个模型调用了一次。这很关键:如果我们调用 iterator.get_next() 一次并将结果张量传递给每个模型,那么所有模型将在每一步中使用相同的数据。
get_available_gpus 函数不值得进一步讨论
# Source:
# https://stackoverflow.com/questions/38559755/how-to-get-current-available-gpus-in-tensorflow
def get_available_gpus():
"""
Returns a list of the identifiers of all visible GPUs.
"""
from tensorflow.python.client import device_lib
local_device_protos = device_lib.list_local_devices()
return [x.name for x in local_device_protos if x.device_type == 'GPU']
唯一缺少的部分是 average_gradients 函数。它做你认为它会做的事情
# Source:
# https://github.com/tensorflow/models/blob/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py#L101
def average_gradients(tower_grads):
"""Calculate the average gradient for each shared variable across all towers.
Note that this function provides a synchronization point across all towers.
Args:
tower_grads: List of lists of (gradient, variable) tuples. The outer list ranges
over the devices. The inner list ranges over the different variables.
Returns:
List of pairs of (gradient, variable) where the gradient has been averaged
across all towers.
"""
average_grads = []
for grad_and_vars in zip(*tower_grads):
# Note that each grad_and_vars looks like the following:
# ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))
grads = [g for g, _ in grad_and_vars]
grad = tf.reduce_mean(grads, 0)
# Keep in mind that the Variables are redundant because they are shared
# across towers. So .. we will just return the first tower's pointer to
# the Variable.
v = grad_and_vars[0][1]
grad_and_var = (grad, v)
average_grads.append(grad_and_var)
return average_grads
tf.reset_default_graph()
parallel_training(training_model, training_dataset(epochs=2))
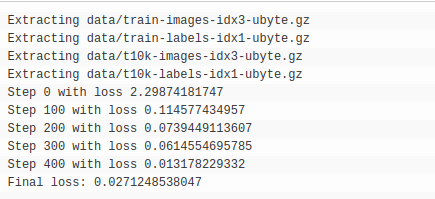
请注意,步数大约是使用一个 GPU 观察到的步数的一半。这是完全合理的,因为我们有效地将小批量大小加倍。

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









