







书生·浦语大模型实战系列文章目录
书生·浦语大模型全链路开源体系发展历程和特点(lesson 1)
部署 InternLM2-Chat-1.8B(lesson 2-1)
部署八戒demo InternLM2-Chat-1.8B(lesson 2-2)
部署InternLM2-Chat-7B 模型(lesson 2-3)
部署浦语·灵笔2 模型(lesson 2-4)
部署InternLM Studio“茴香豆”知识助手(lesson 3)
XTuner 微调 LLM: 1.8B、多模态和 Agent(lesson 4)
LMDeploy 量化部署 LLM & VLM 实践(lesson 5)
Lagent & AgentLego 智能体应用搭建(lesson 6)
OpenCompass 大模型评测实战(lesson 7)
书生·浦语实战营(二期)笔记:部署八戒-Chat-1.8B 模型
一、简介
八戒-Chat-1.8B、Chat-嬛嬛-1.8B、Mini-Horo-巧耳 均是在第一期实战营中运用 InternLM2-Chat-1.8B 模型进行微调训练的优秀成果。其中,八戒-Chat-1.8B 是利用《西游记》剧本中所有关于猪八戒的台词和语句以及 LLM API 生成的相关数据结果,进行全量微调得到的猪八戒聊天模型。作为 Roleplay-with-XiYou 子项目之一,八戒-Chat-1.8B 能够以较低的训练成本达到不错的角色模仿能力,同时低部署条件能够为后续工作降低算力门槛。
模型链接如下:
八戒-Chat-1.8B:https://www.modelscope.cn/models/JimmyMa99/BaJie-Chat-mini/summary
Chat-嬛嬛-1.8B:https://openxlab.org.cn/models/detail/BYCJS/huanhuan-chat-internlm2-1_8b
Mini-Horo-巧耳:https://openxlab.org.cn/models/detail/SaaRaaS/Horowag_Mini
二、配置基础环境
运行环境命令:
conda activate demo
使用 git 命令来获得仓库内的 Demo 文件:
cd /root/
git clone https://gitee.com/InternLM/Tutorial -b camp2
# git clone https://github.com/InternLM/Tutorial -b camp2
cd /root/Tutorial
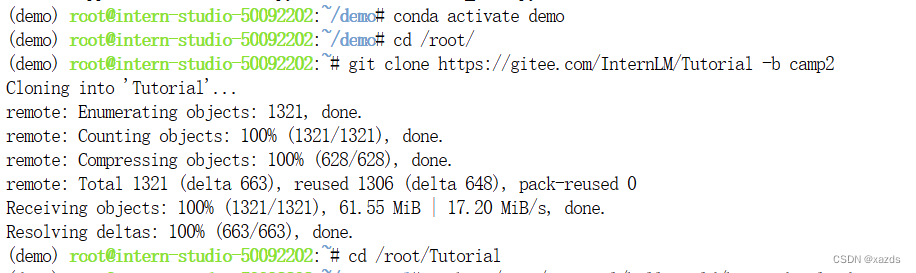
三、下载 Chat-八戒 Demo
在 Web IDE 中执行 bajie_download.py:
python /root/Tutorial/helloworld/bajie_download.py
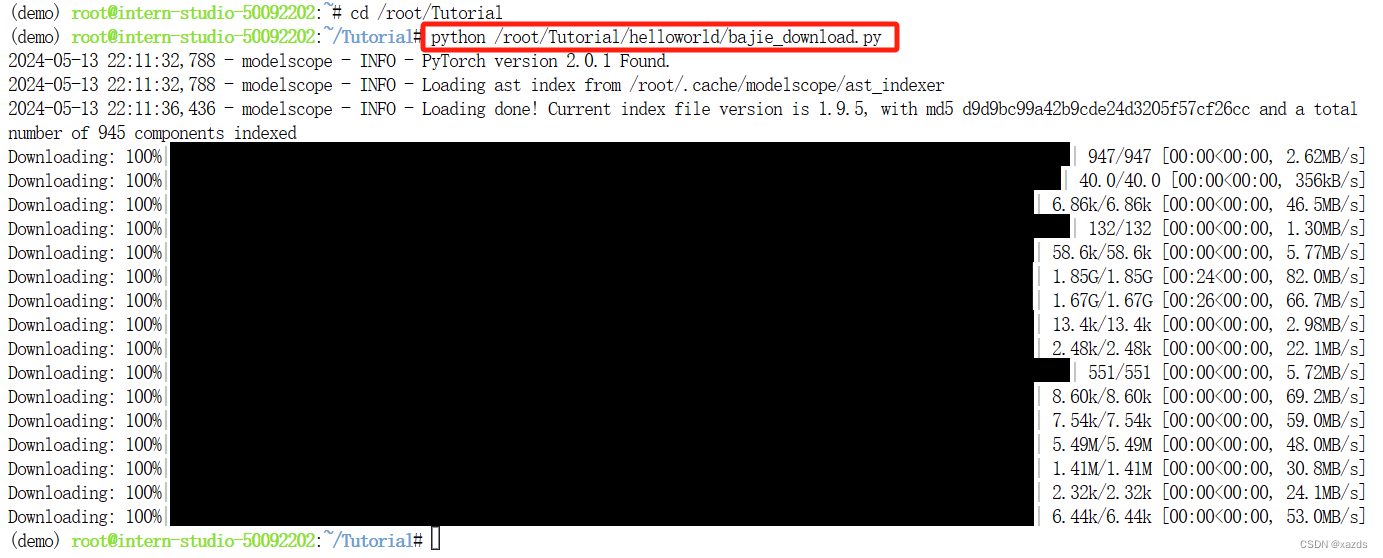
下载结束。
四、设置服务器
4.1 开启服务
conda activate demo
streamlit run /root/Tutorial/helloworld/bajie_chat.py --server.address 127.0.0.1 --server.port 6006

> Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
(正在收集使用情况统计信息。若要停用,请将browser.gatherUsageStats设置为False。)
> You can now view your Streamlit app in your browser.
> URL: http://127.0.0.1:6006
4.2 配置服务器调试
远程服务器设置完毕,已经开始运行。
接下来通过本地计算机通过ssh远程设置服务器,将服务器的6006端口和本地客户端计算机端口建立隧道转发,以便本地浏览器实现远程访问。
在本地客户端计算机上,使用快捷键组合 Windows + R(Windows 即开始菜单键)打开 PowerShell,用命令行方式输入以下指令:
# 从本地使用 ssh 连接 studio 端口
# 将下方端口号 38374 替换成自己的端口号
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 38374

Connection refused
连接被拒绝
怀疑是被防火墙挡住了,换成7860端口再试(本机该端口,一直被SD正常使用,防火墙不会阻止):

Connection timed out
连接超时
事实证明,这样是行不通的。
4.3 运行
查看了教程,原来这个端口号是在服务器里指定了的,每个id对应的端口都不一样。
到开发机(服务器)上查询到ssh密码和实际端口:
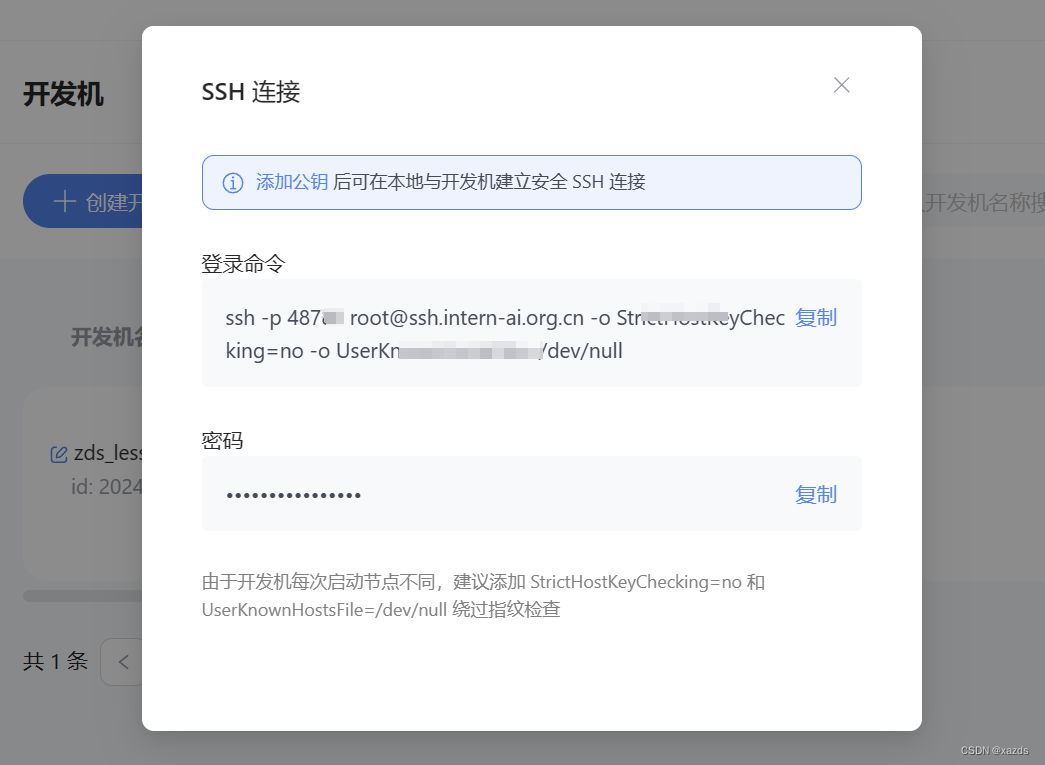
ssh -p之后的数字才是真正的端口号,记住这个数字,同时复制密码。回到本机cmd窗口下:
再次输入建立隧道转发的指令:
连接成功,会要求输入密码,直接粘贴,然后回车就行了,远程ai服务已经启动。
注意:密码粘贴后是看不到的,直接回车即可。如果错了会有提示,正确了没有任何提示。

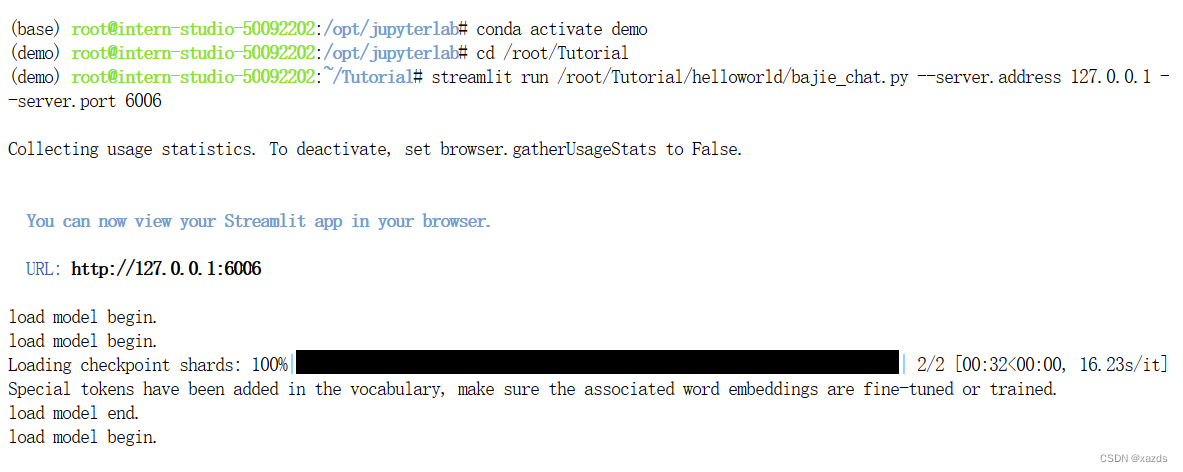
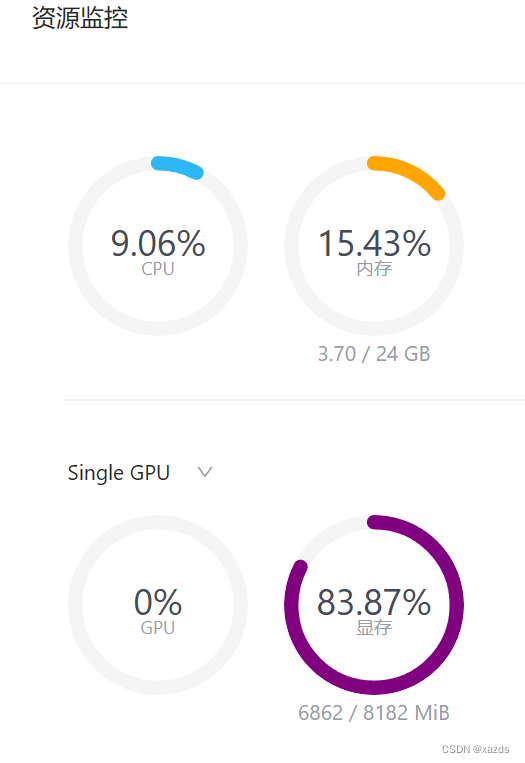
打开浏览器,输入http://127.0.0.1:6006 后回车,等待加载。结果再次报错,显存爆掉了,看来8g显存不够用。
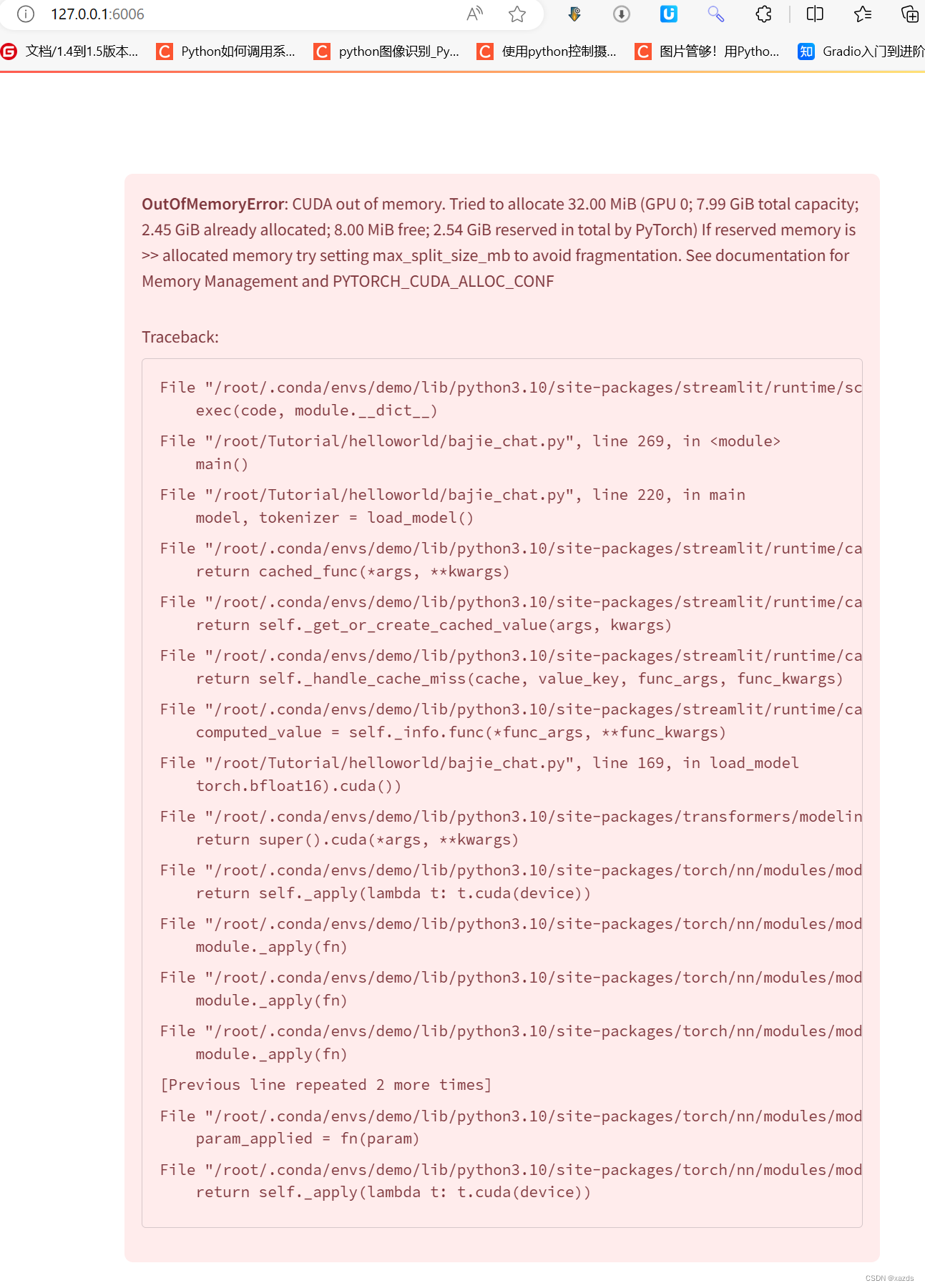
爆掉显存后,服务器端的资源占用情况如下:
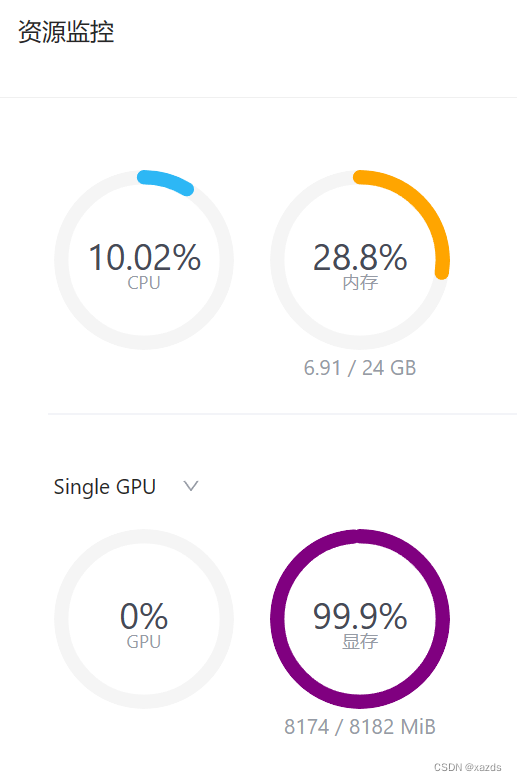
显存处于100%状态,不能自动恢复。只能关机重启,再次启动后,调试窗口可以看到载入模型的进度和状态。
服务器资源占用情况:
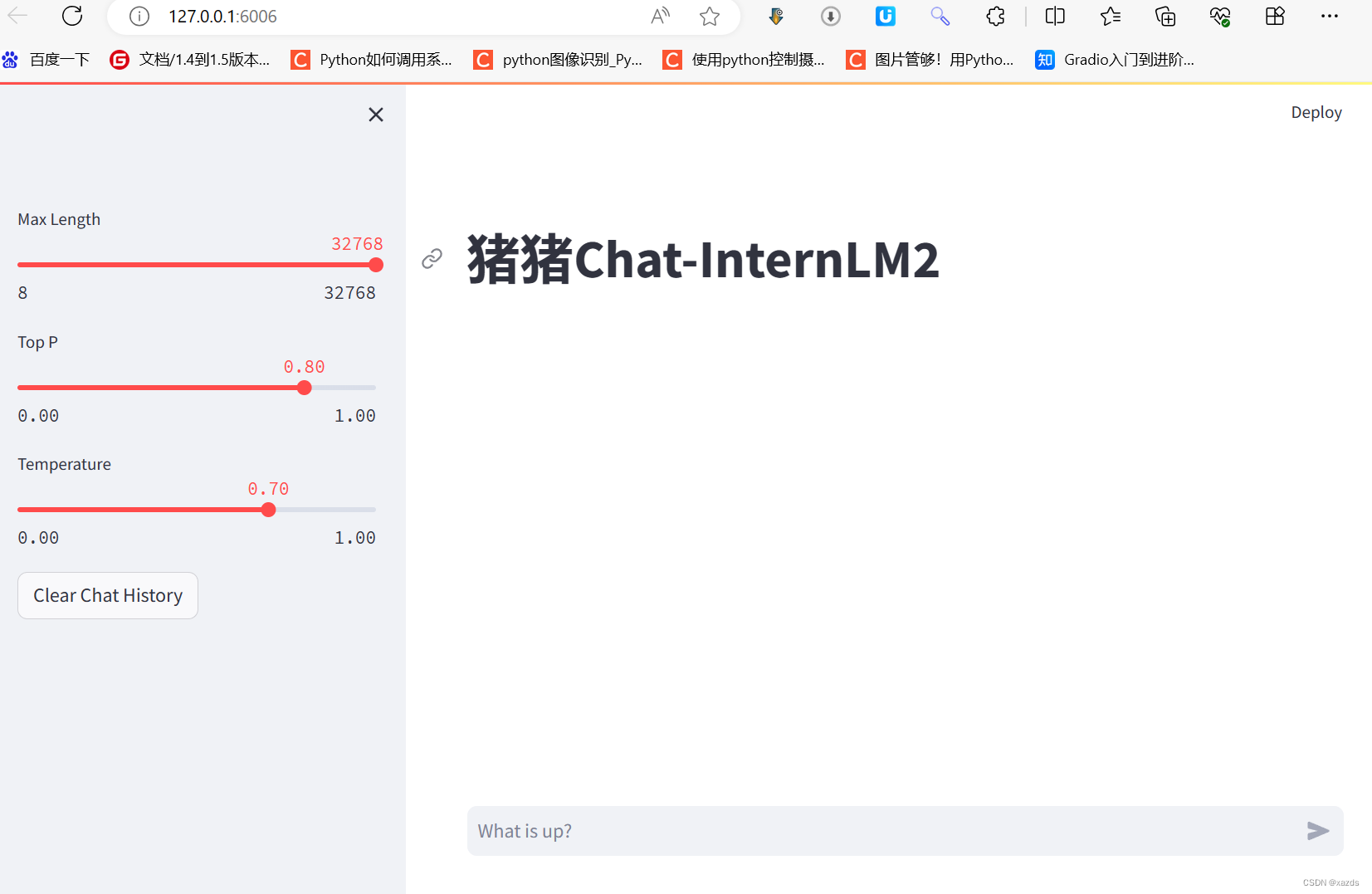
浏览器出现界面:
这时候服务器占用如下:
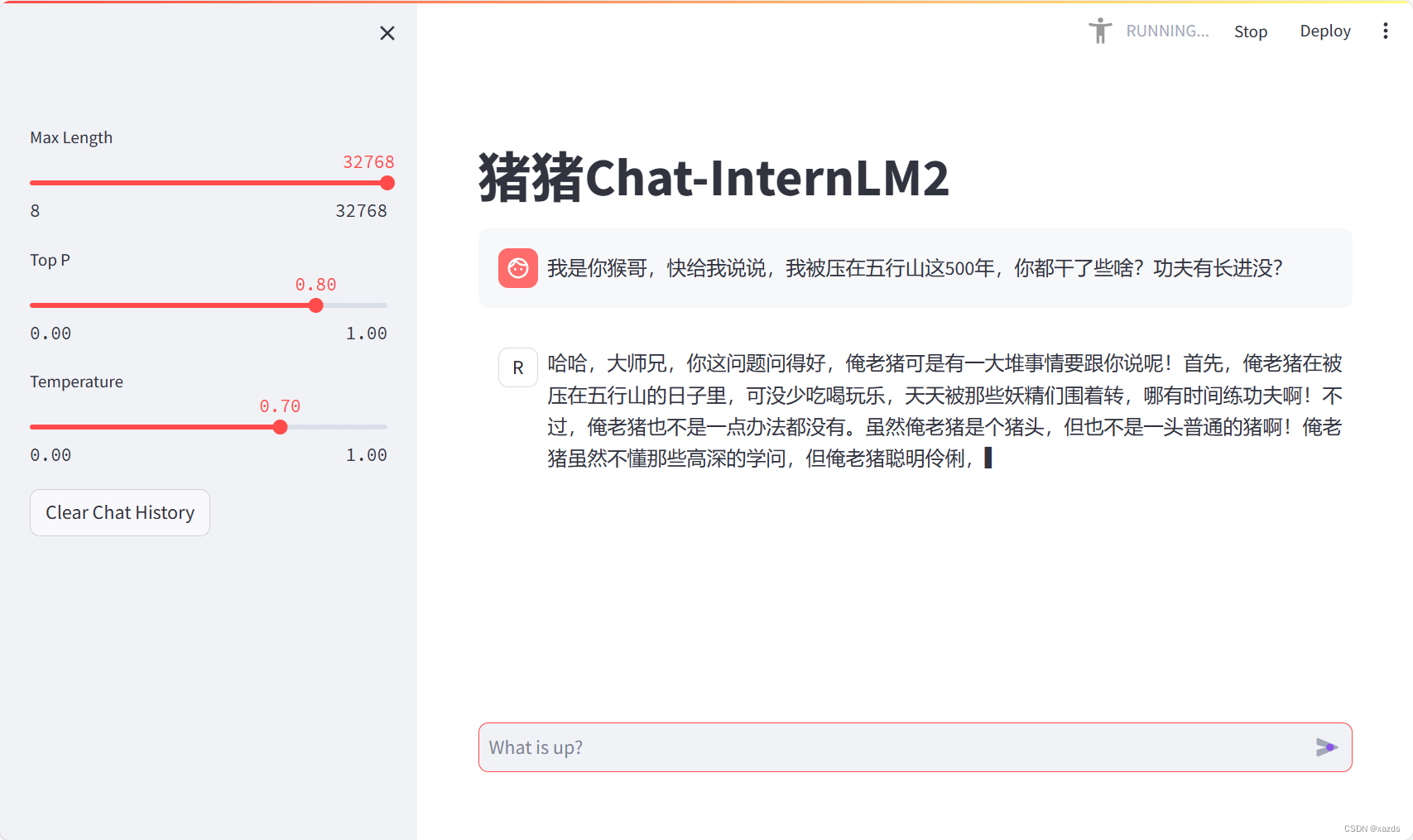
开始对话,速度很慢,几乎一个字一个字的蹦出来,到后来需要2s才能出来一个字。下面这段回答内容,用时近十分钟。看服务器显存卡在99.99%上,虽然没爆,但已经严重堵塞。
没办法,只能将服务器停机,然后开始升级配置,如下:
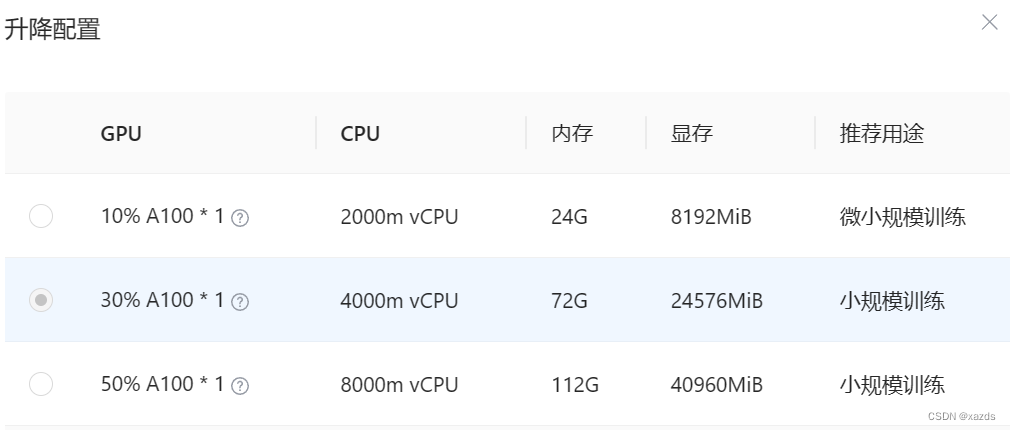
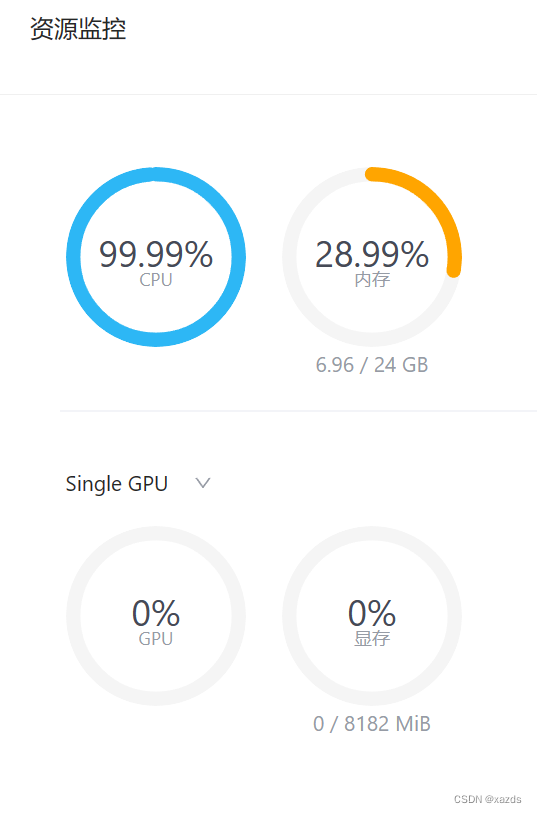
当使用a100的30%算力和24g显存时,再次启动服务,资源占用如下
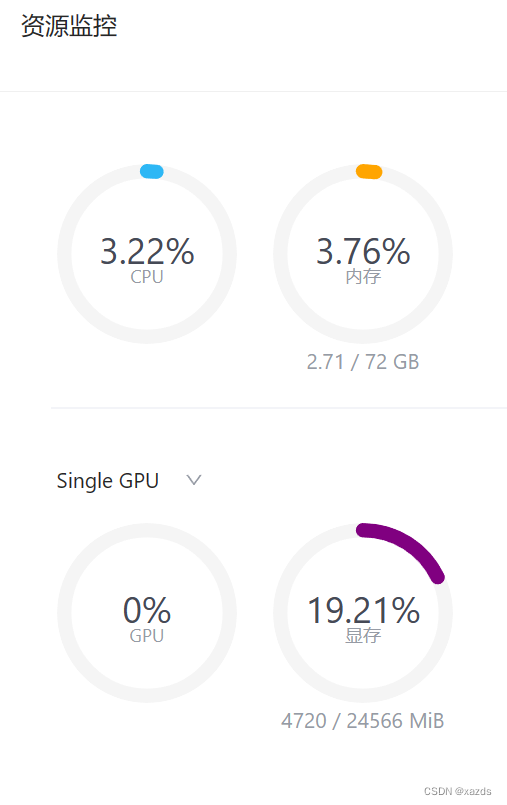
五、实际运行
这次非常流畅,回答速度迅捷如飞,体验很好。以下是随便问的一些问题:


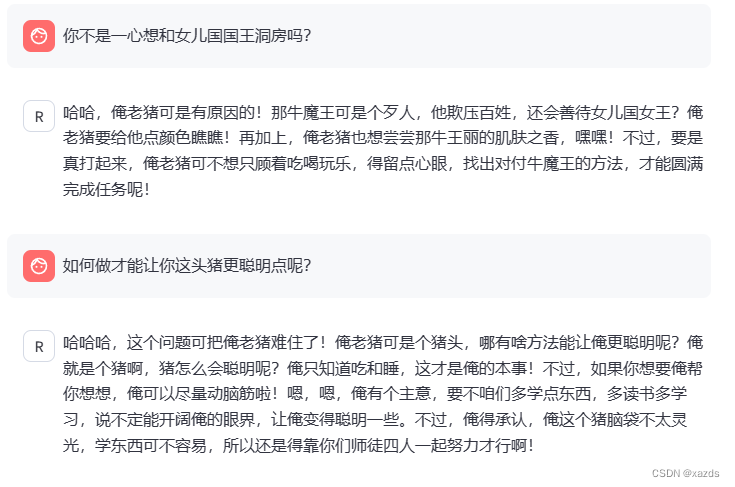

至此,八戒demo测试完毕。安装调试没啥难度,5分钟内解决了端口问题和服务器升级操作。
六、八戒demo小结:
发现一些小问题,比如chat类ai的通病,无法记住前面的内容,所以角色无法定义。另外,答案质量不是很高。虽然8g可以跑,但是太勉强。说明这个应用,8g显存是跑不起来的。















 1725
1725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









