







书生·浦语大模型实战系列文章目录
书生·浦语大模型全链路开源体系发展历程和特点(lesson 1)
部署 InternLM2-Chat-1.8B(lesson 2-1)
部署八戒demo InternLM2-Chat-1.8B(lesson 2-2)
部署InternLM2-Chat-7B 模型(lesson 2-3)
部署浦语·灵笔2 模型(lesson 2-4)
部署InternLM Studio“茴香豆”知识助手(lesson 3)
XTuner 微调 LLM: 1.8B、多模态和 Agent(lesson 4)
LMDeploy 量化部署 LLM & VLM 实践(lesson 5)
Lagent & AgentLego 智能体应用搭建(lesson 6)
OpenCompass 大模型评测实战(lesson 7)
前言
73年前,“机器思维”的概念第一次被计算机科学之父艾伦·图灵(Alan Turing)提出。
73年后,AI历经了数十年的不断进化迭代,随着ChatGPT的问世,开启了人类图灵测试的史诗级大幕。
这一里程碑事件,几乎在一夜之间引爆了全球AI热,国内外生成式AI大规模爆发。
硅谷的AI大战呈“一超多强”局势,竞争视野主要聚焦于OpenAI和谷歌。
而国内AI势力主要集中在传统IT大厂,紧随境外AI产品不断迭代进化。
在这些实力大厂中,有一支黑马与众不同一枝独秀,他就是汤晓鸥老师于2014年创建的商汤科技。
汤老师说:人工智能的中国式文艺复兴,也叫人工智能的中国式十月革命。
2020年,上海人工智能实验室成立。
2023年7月6日,书生·浦语(InternLM)在世界人工智能大会上正式开源
上海AI实验室(Shanghai AI Laboratory)林达华教授:“在大模型时代,基座模型和相关的工具体系是大模型创新的技术基石。通过书生·浦语的高质量全方位开源开放,我们希望可以助力大模型的创新和应用,让更多的领域和行业受惠于大模型变革的浪潮。”
一、书生·浦语(InternLM)是什么?
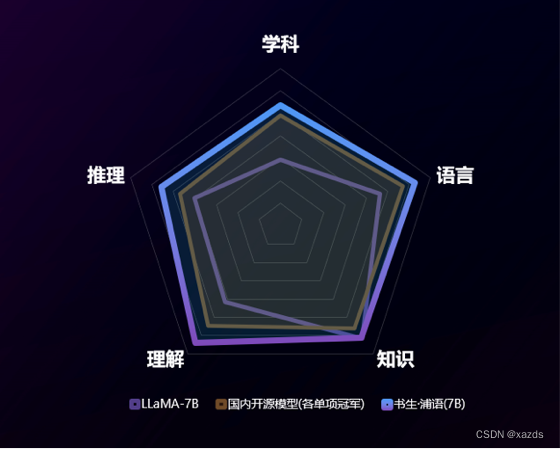
书生·浦语(InternLM),是一个70亿参数的轻量级版本InternLM-7B,贯穿数据、预训练、微调、部署和评测五大环节的全链条工具体系。开源链接
InternLM-7B 在包含40个评测集的全维度评测中展现出卓越且平衡的性能,全面领先现有开源模型。值得一提的是,它在两个被广泛采用的基准 MMLU 和 CEval 上分别取得了50.8和52.8的高分,刷新了7B量级模型的世界纪录。
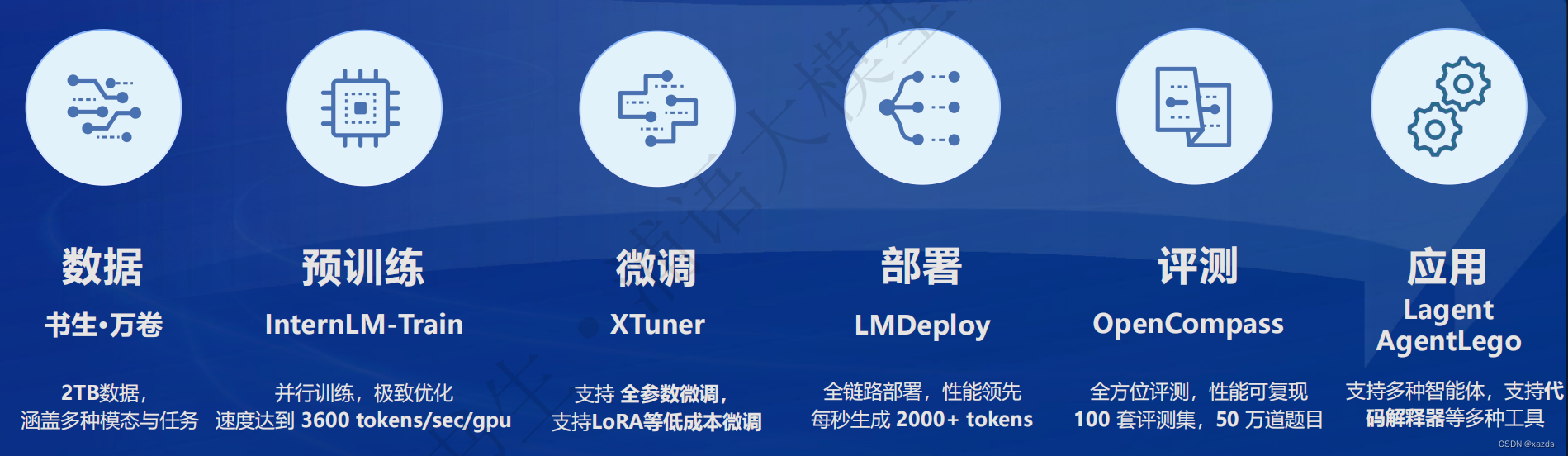
书生·浦语开源了全链条工具体系,涵盖数据、预训练、微调、部署和评测五大环节。
在数据环节,通过OpenDataLab开放了包含30多种模态的5500公开数据集,其中在自然语言方面开放了超过10000亿token的高质量语料。
在预训练环节,开源了面向轻量级语言大模型的训练框架 InternLM-Train,支持从8卡到1024卡并行训练,提出了Hybrid-Zero独特技术,性能领先行业水平。
在微调环节,开源了全流程微调工具,支持SFT、RLHF,还支持训练模型进行复杂的符号计算和工具调用,通过代码解决复杂的数学计算问题。
在部署环节,开源了部署推理工具链LMDeploy。支持十亿到千亿参数语言模型的高效推理,性能超越 HuggingFace、Deepspeed、vLLM等主流推理框架。
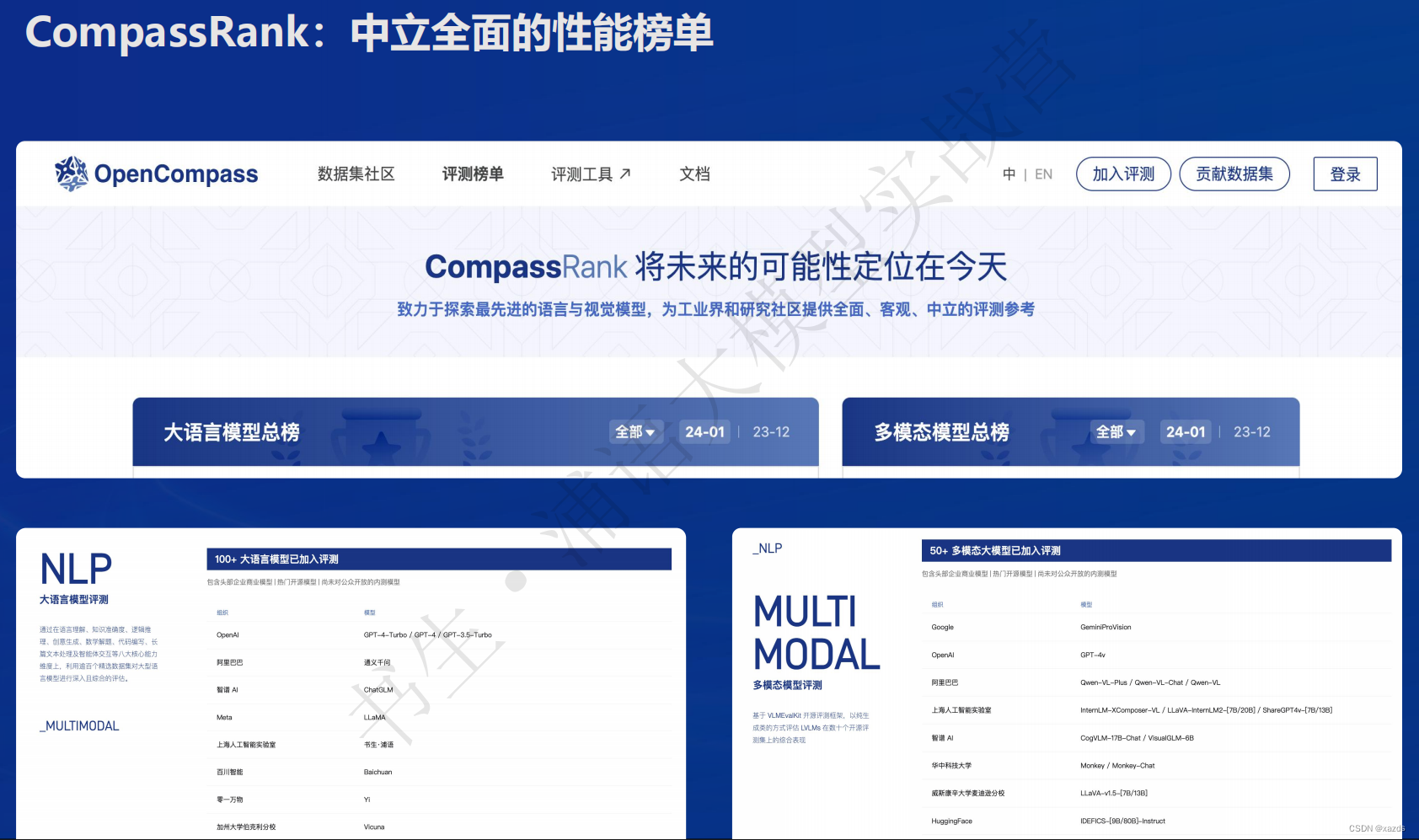
在评测环节,上线了开放评测平台 OpenCompass,支持大模型的一站式、全方位评测,包含超过40个评测集、30万评测题目。通过全自动分布式评测,保障开源模型性能可高效复现。
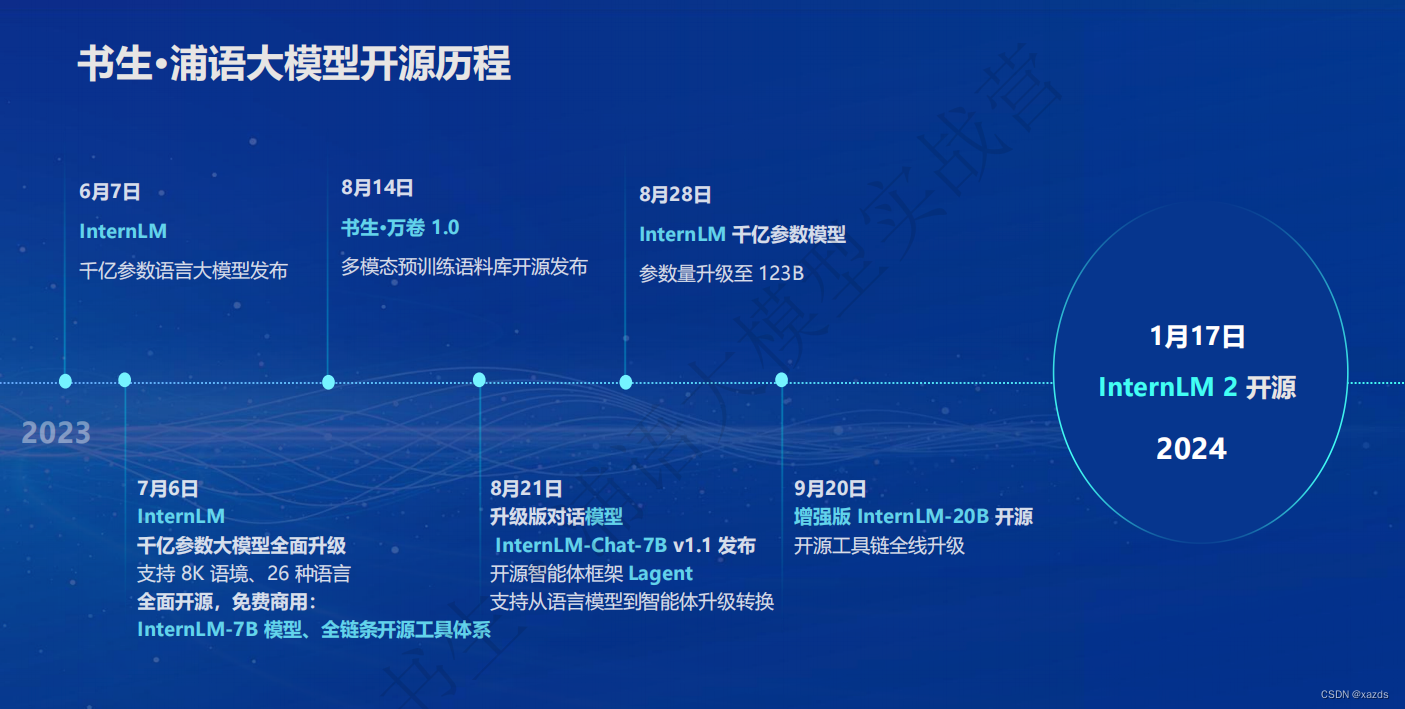
开源历程
核心理念

二、书生·浦语(InternLM)的主要特点和优势
体系

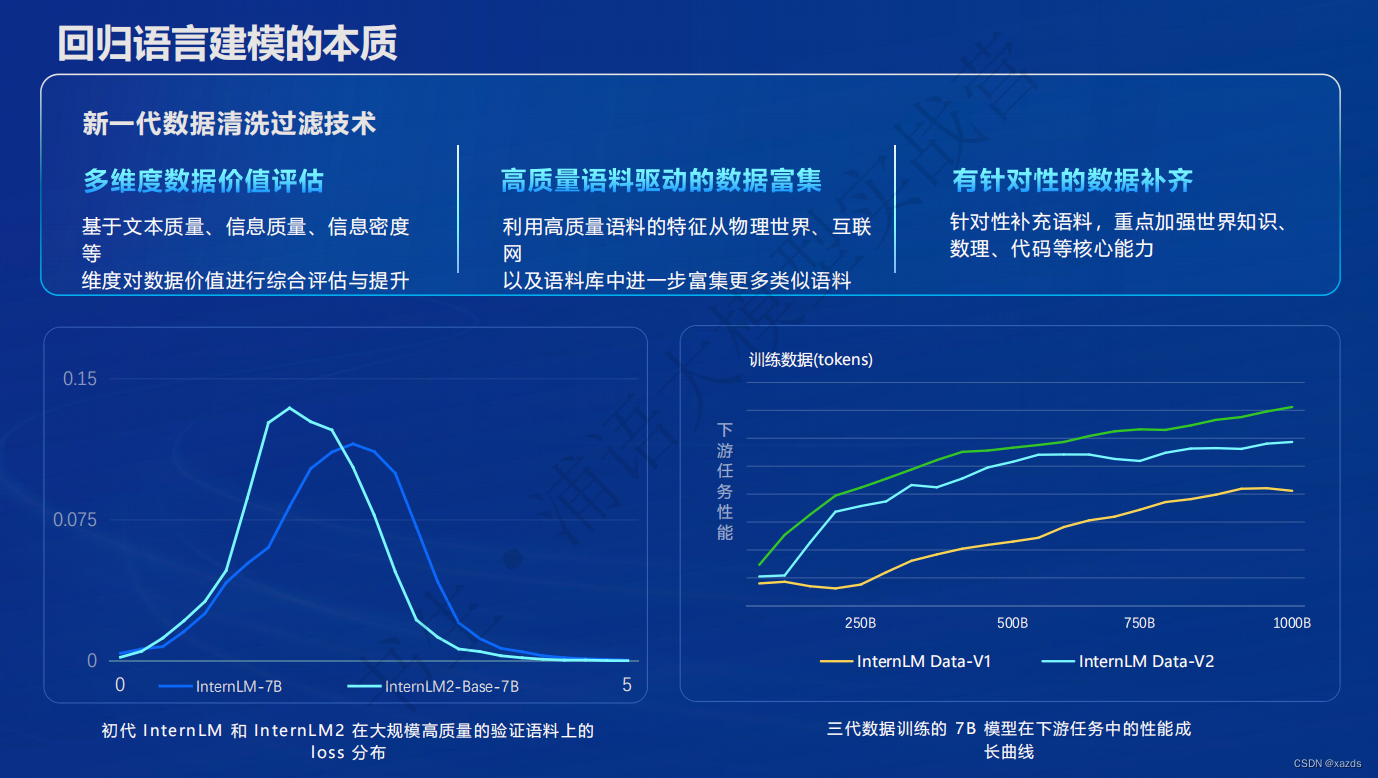
回归本质
亮点
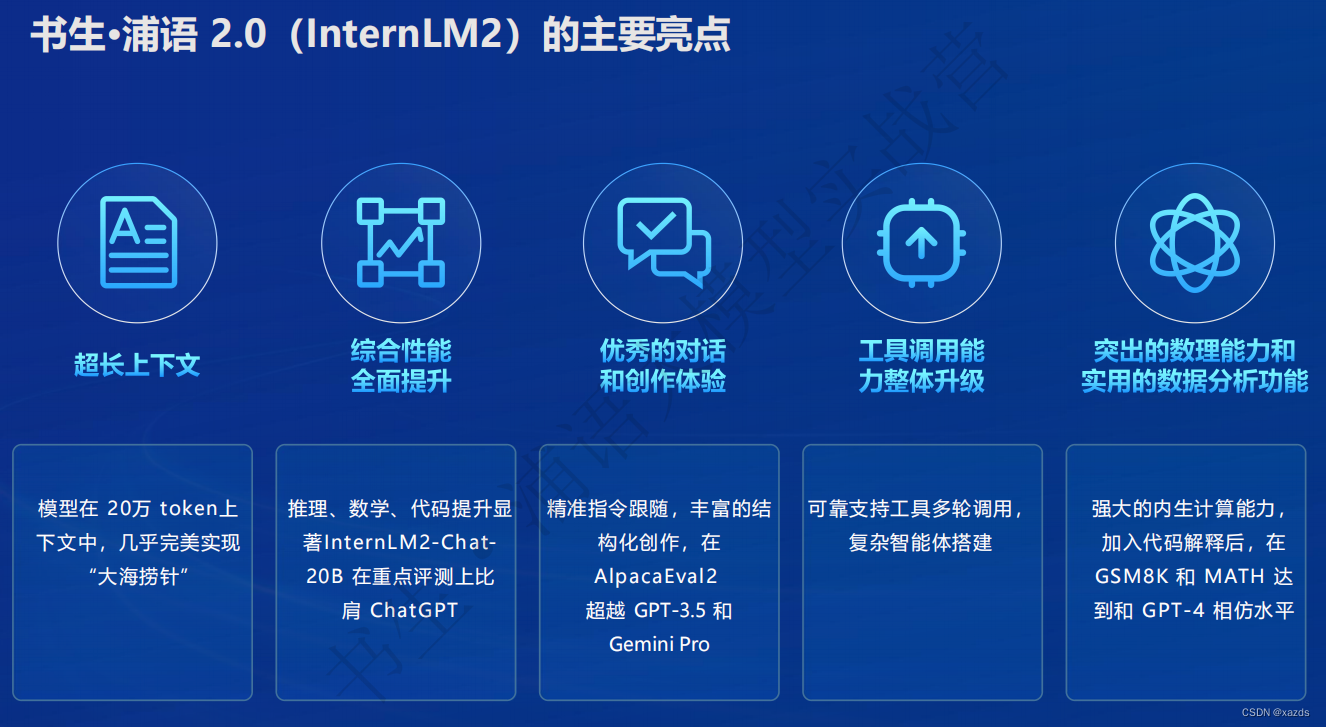
超长上下文支持:模型在 20 万字长输入中几乎完美地实现长文“大海捞针”,在 LongBench 和 L-Eval 等长文任务中的表现也达到开源模型中的领先水平。
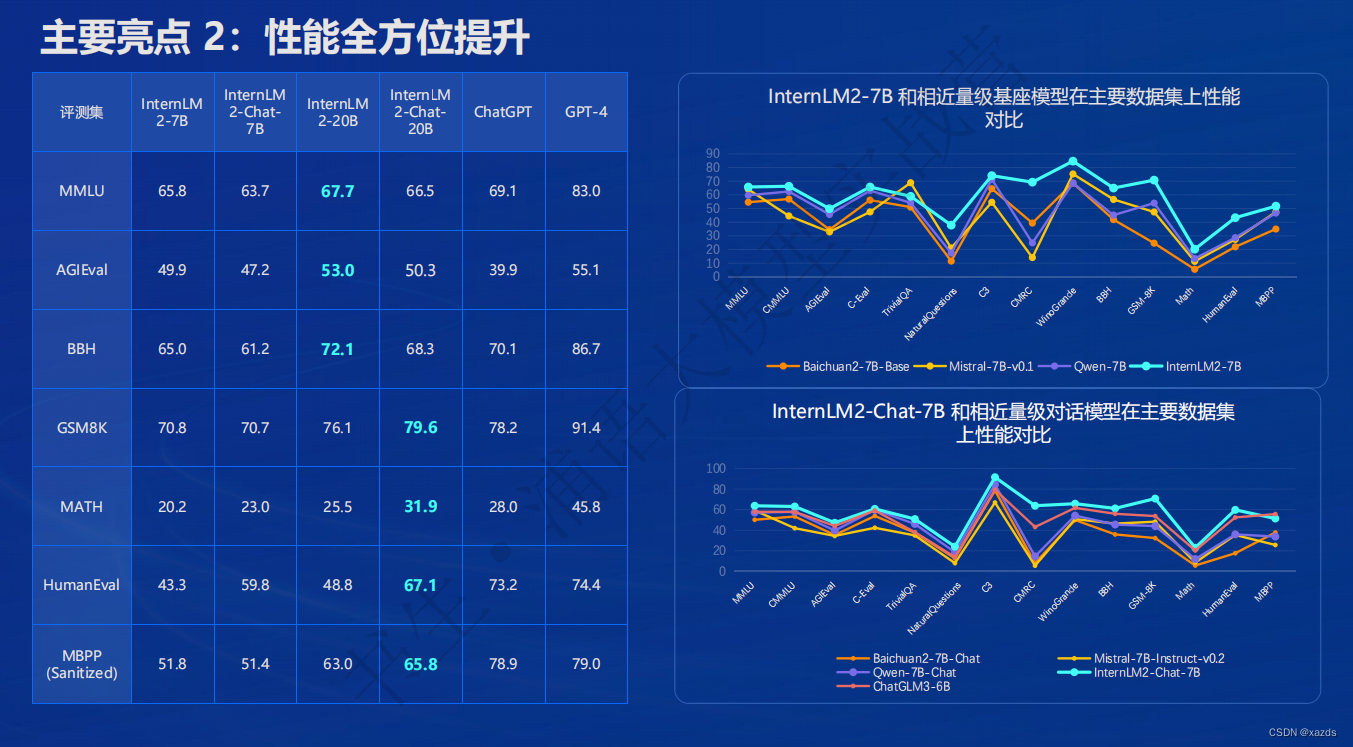
性能全方位提升
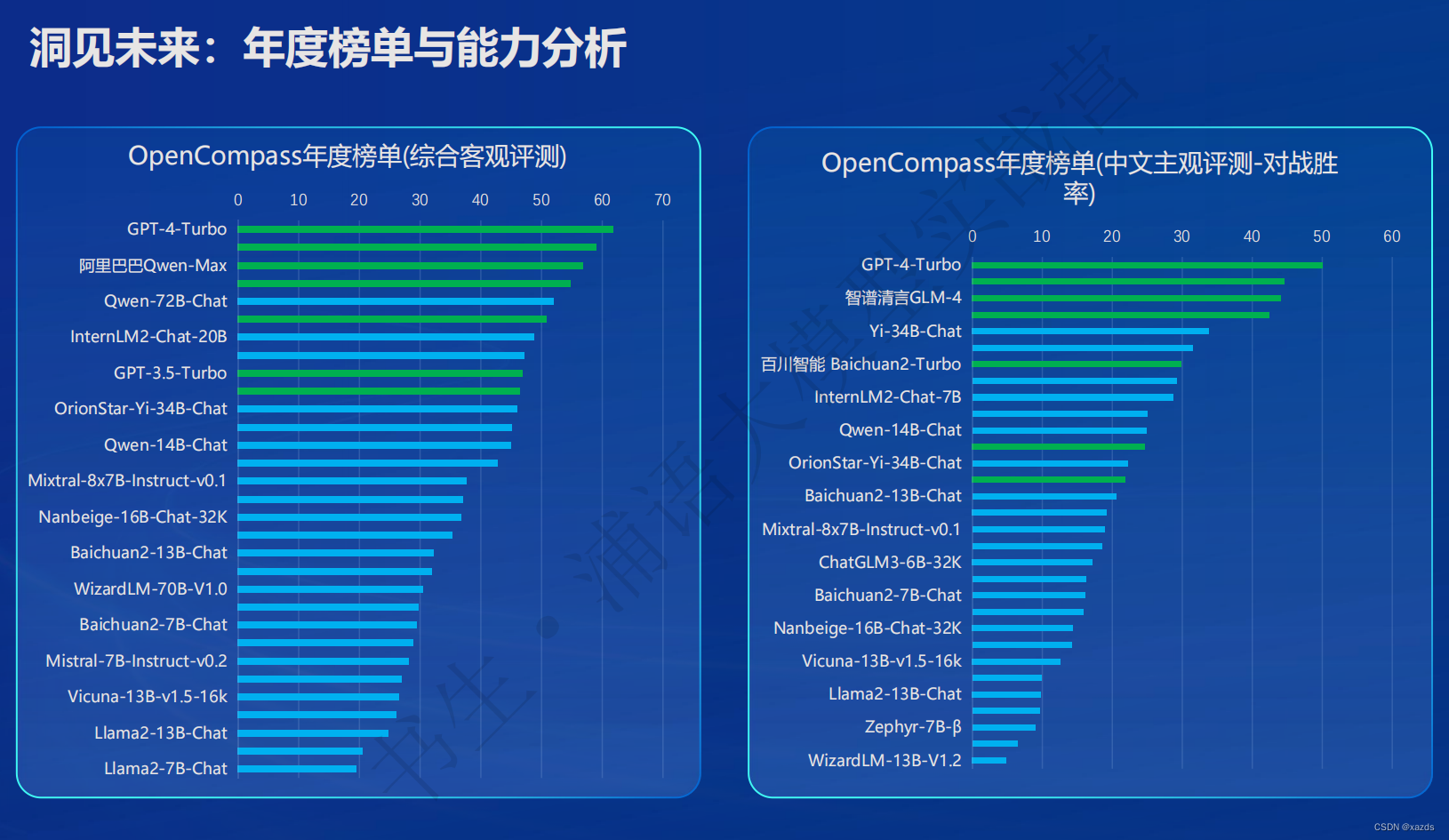
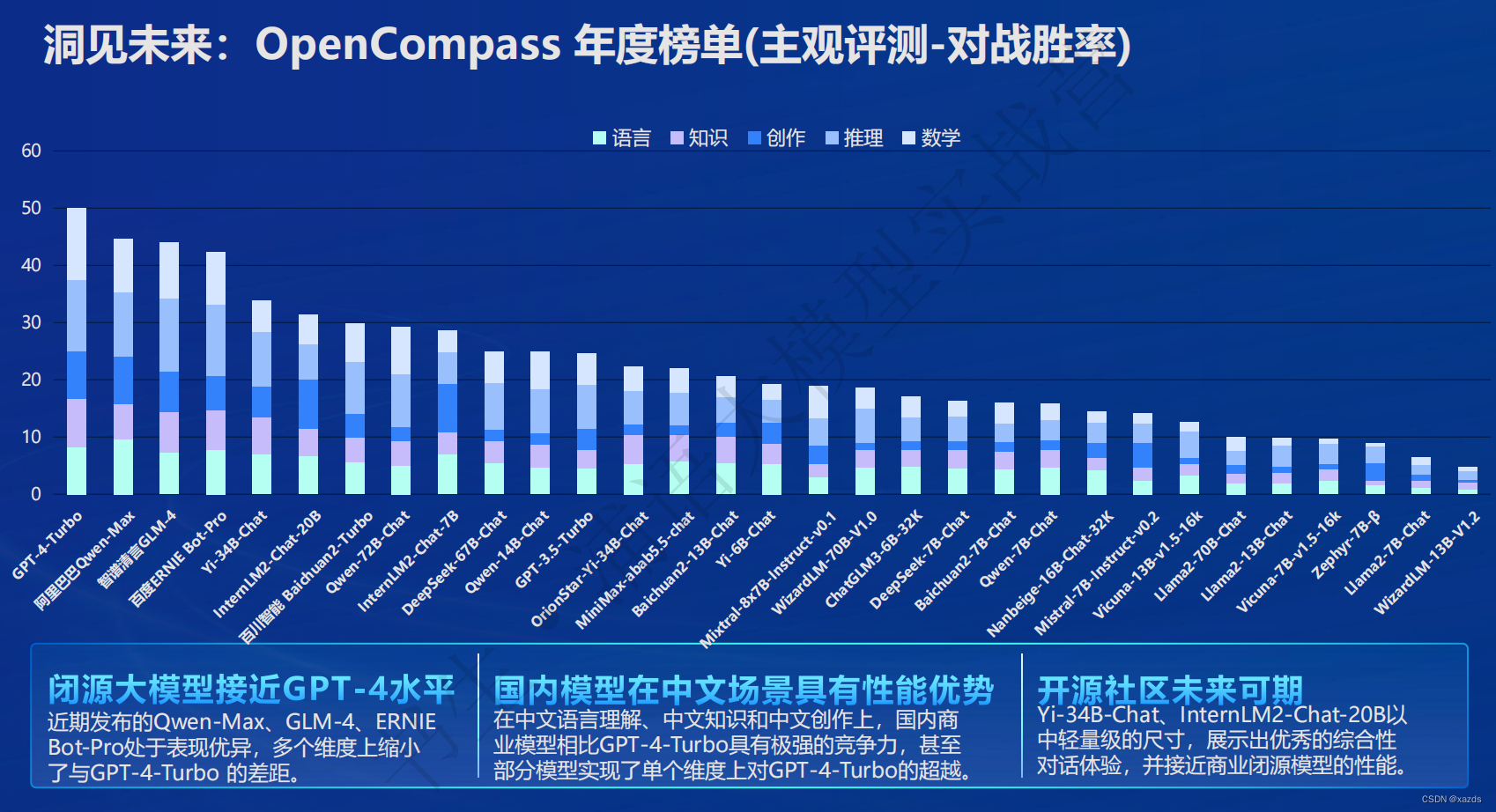
在各能力维度全面进步,在推理、数学、代码等方面的能力提升尤为显著,综合性能达到同量级开源模型的领先水平,在重点能力评测上 InternLM2-Chat-20B 甚至可以达到比肩 ChatGPT (GPT-3.5)的水平。
性能
创作体验
AlpacaEval2 英文主观对话榜单(斯坦福大学发布): InternLM2-Chat-20B 胜率(21.75%) 超越了 GPT-3.5(14.13%)、Gemini Pro(16.85%) 和 Claude-2 (17.19%)。

指令遵循能力评测集 IFEval(谷歌发布): InternLM2-Chat-20B 的指令遵循率超越了 GPT-4(79.5% vs 79.3%)。
工具调用能力升级
工具调用能够极大地拓展大语言模型的能力边界 ,使得大语言模型能够通过搜索、计算、代码解释器等获
取最新的知识并处理更加复杂的问题。InternLM2进一步升级了模型的工具调用能力,能够更稳定地进
行工具筛选和多步骤规划,完成复杂任务。
数理能力突出

强大的内生计算能力
InternLM2 针对性提高了模型的计算能力,在不依靠计算器等外部工具的情况下,
在 100 以内的简单数学运算上能够做到接近 100% 的准确率,在 1000 以内达到 80% 左右的运算准确率
依赖模型优秀的内生能力,InternLM2 不借助外部工具就能够进行部分复杂数学题的运算和求解。
代码解释器:在典型的数学评测集 GSM8K 和 MATH 上,配合代码解释器,InternLM2 都能够在本身已经较高的分数上,进一步获得提升。其中对于难度更高的 MATH 数据集,借助代码解释器,精度从 32.5 大幅提升到 51.2,甚至超过了 GPT-4 的表现。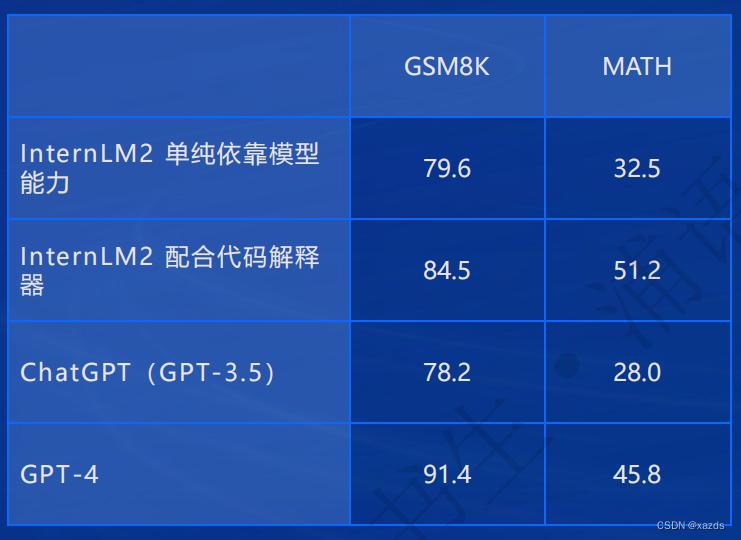
在实用分析、上下文聊天、编程代码方面也有不俗的表现。
总之,书生·浦语体系是一个富有想像力,充满人文关怀,贴心又可靠 的AI 助手。
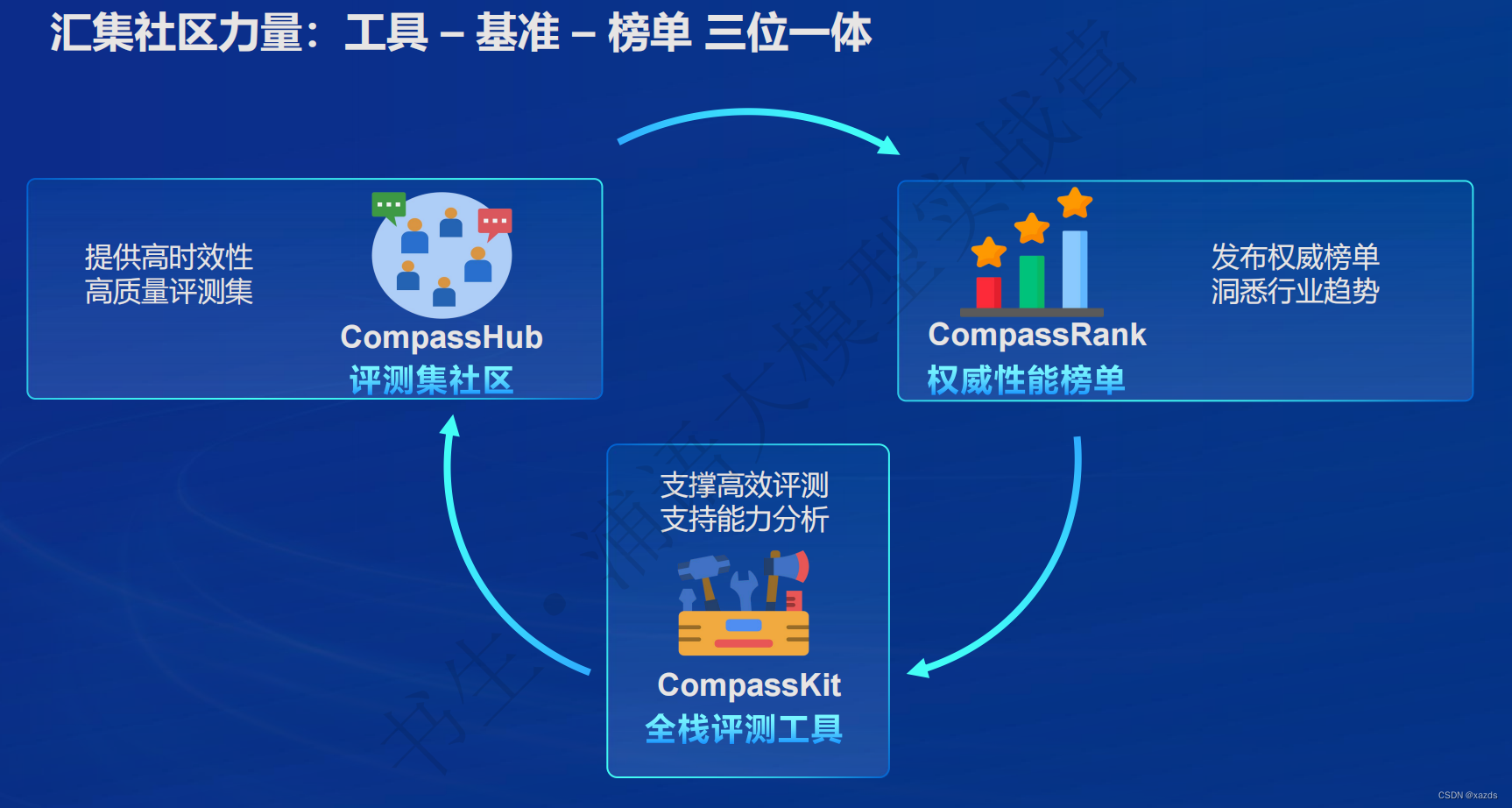
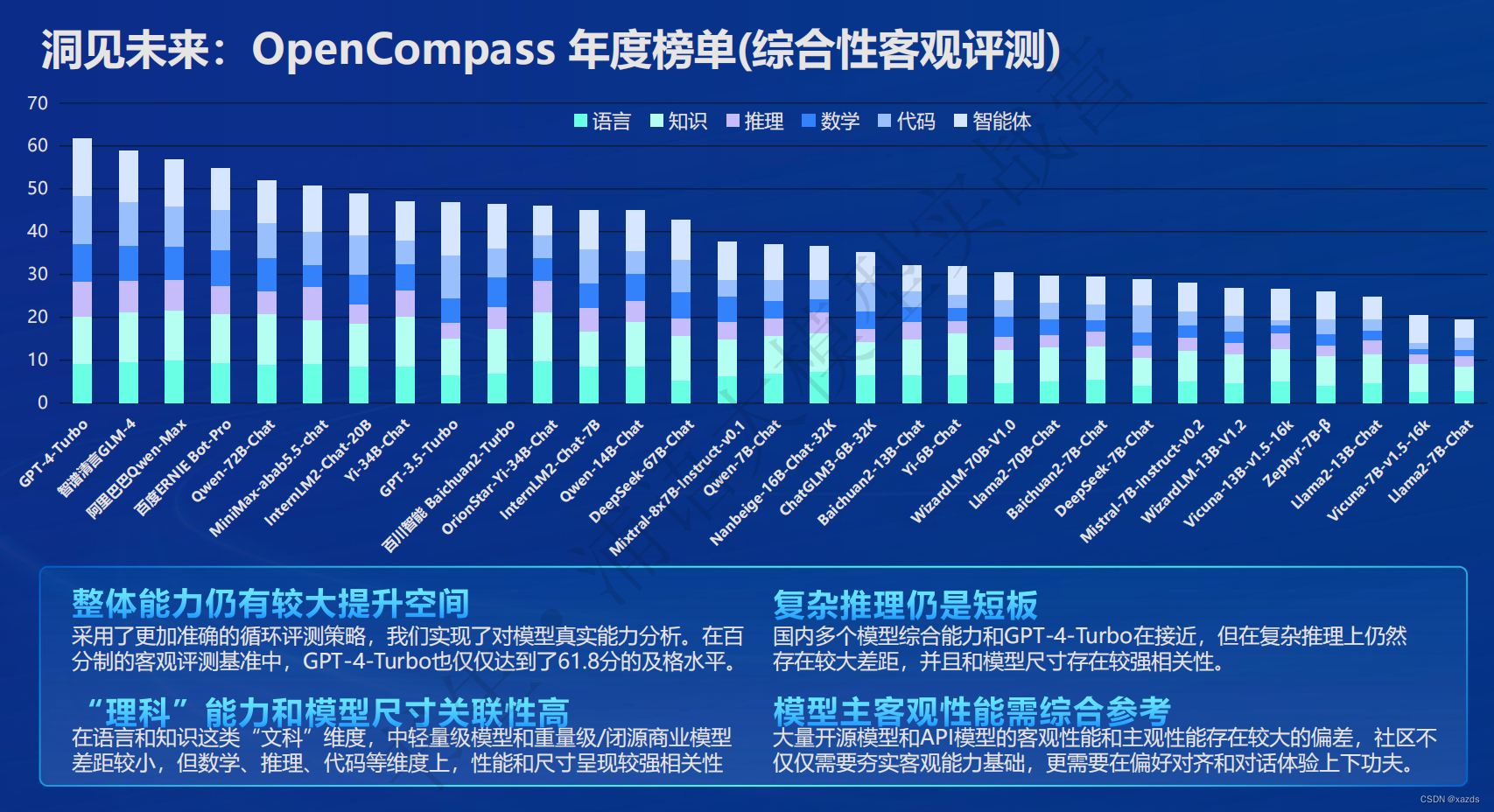
三、评测







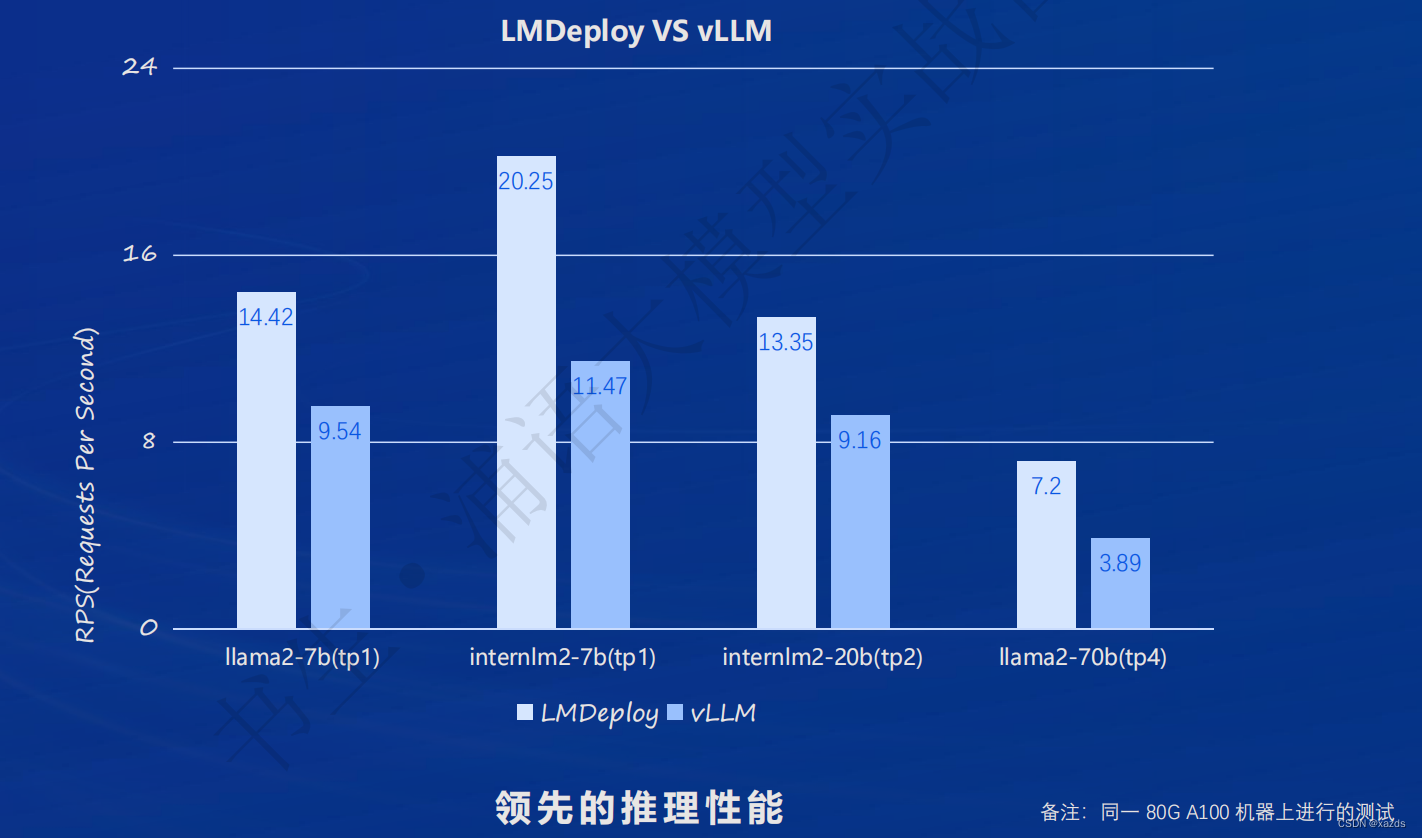
四、部署


五、应用
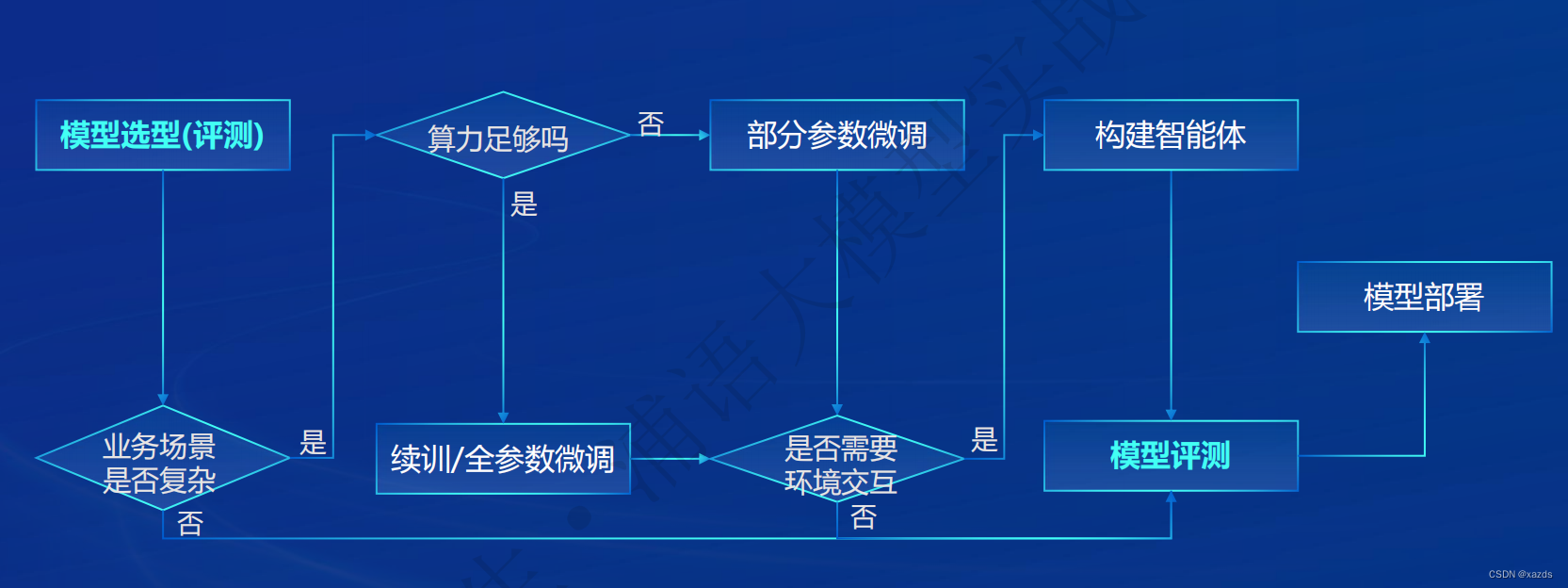
应用流程
六、数据集

开放高质量语料数据

预训练

微调
大语言模型的下游应用中,增量续训和有监督微调是经常会用到两种方式:
增量续训
**使用场景:**让基座模型学习到一些新知识,如某个垂类领域知识
**训练数据:**文章、书籍、代码等
有监督微调
**使用场景:**让模型学会理解各种指令进行对话,或者注入少量领域知识
**训练数据:**高质量的对话、问答数据

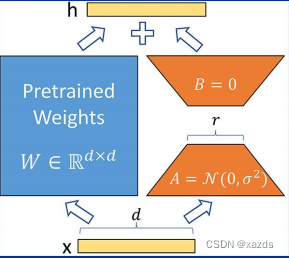
全量参数微调 部分参数微调
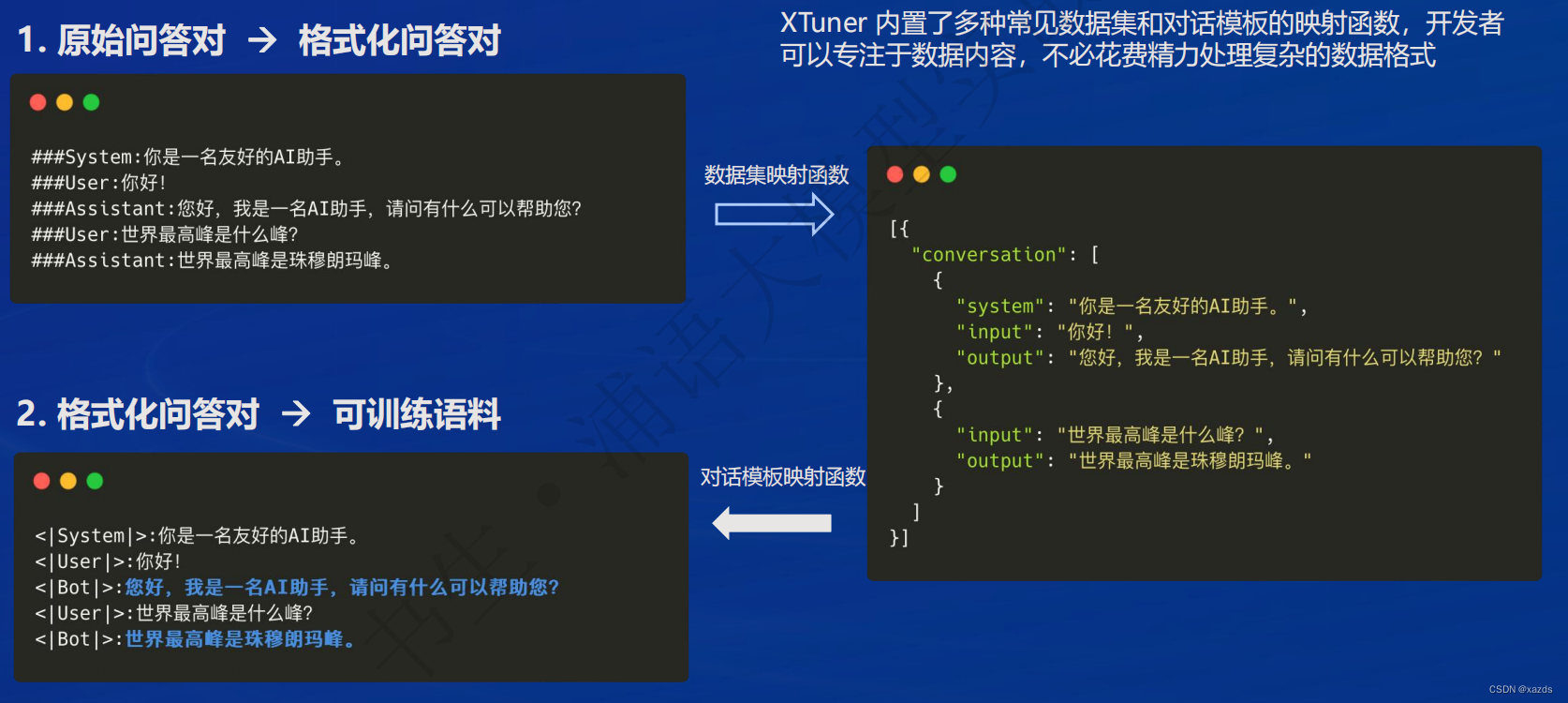
XTuner 数据引擎
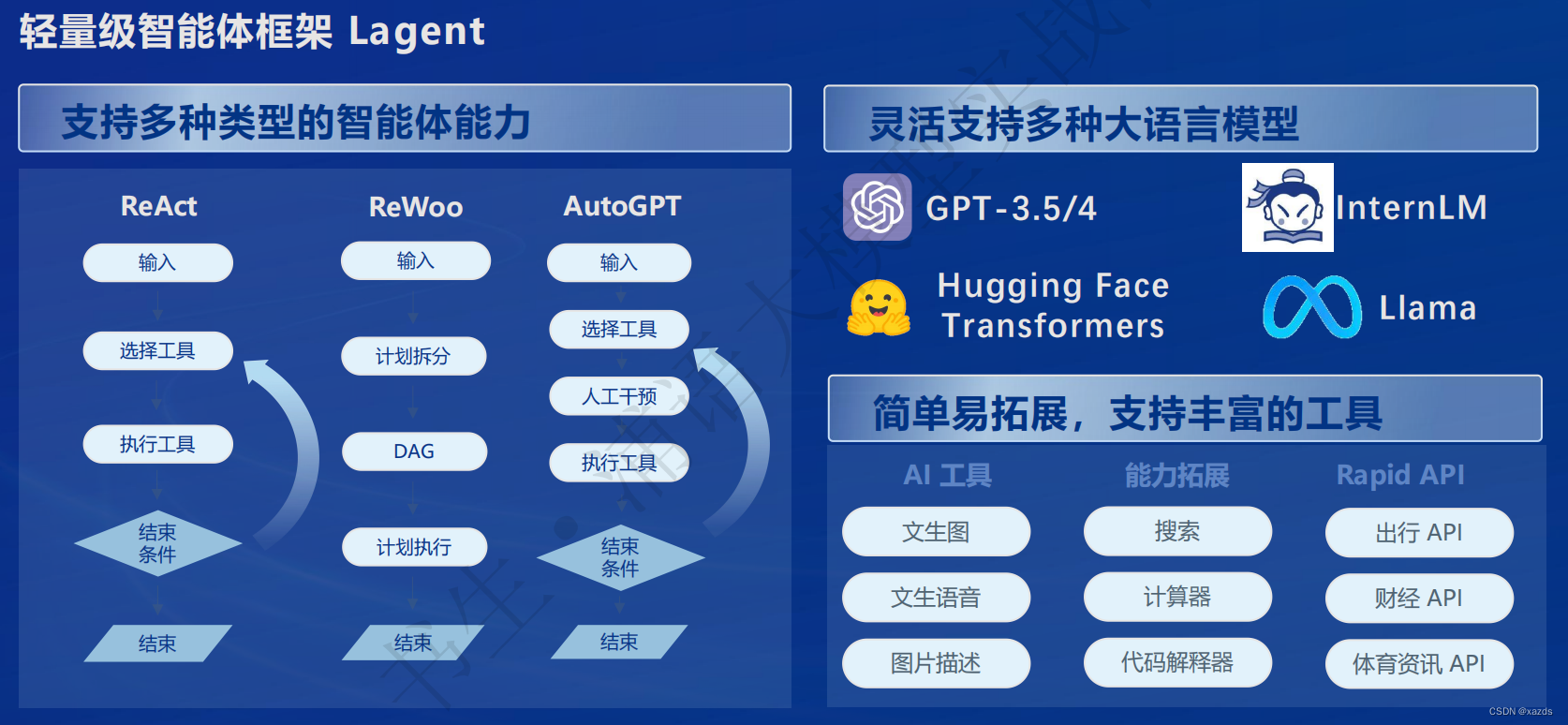
七、智能体
多模态智能体工具箱 AgentLego
• 代码解数学题
• 零样本泛化:多模态 AI 工具使用
• 丰富的工具集合,尤其是提供了大量视觉、多模态相关领域的前沿算法功能
• 支持多个主流智能体系统,如 LangChain,Transformers Agent,lagent 等
• 灵活的多模态工具调用接口,可以轻松支持各类输入输出格式的工具函数
• 一键式远程工具部署,轻松使用和调试大模型智能体


八、总结

经过第一课的学习,初步了解了书生·浦语大模型的发展历程、特点、能力和数据规模等知识点,通过对这些内容的进一步消化,未来该模型可用于以下应用方向:

相信在未来的课程中,通过实战化训练,进一步掌握环境构建、模型部署、数据集的处理、训练、微调和具体应用等基础能力,以便将来把AI代入生活工作的方方面面,用技术创新为行业赋能。















 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









