







Python小案例(八)基于自动节点树进行维度下钻
在日常业务中,需要下钻维度查询造成整体波动的细分群体,但是如果维度过多,手动查询就显得繁琐了。这里介绍一种方法,利用自动节点树的方式进行维度下钻,本文参考自《Python数据分析与数据化运营 第2版》。
在开始之前,需要配置下绘图环境,这里通过graphviz绘制流向图
$ brew install graphviz # mac安装graphviz
$ dot -V # 测试安装成功
pip install graphviz # python环境安装graphviz
import datetime
import numpy as np
import pandas as pd
from graphviz import Digraph # 画图用库 graphviz是一个强大的复杂关系图表库,类似的还有pyechart
# 自动节点树函数
def autoNodeTree(df, date, file_name):
'''
自动节点树进行多维度下钻
df:数据框,要求以日期列开始,标的指标列结尾。维度列均为字符串类型
date:指定分析的日期
file_name:保存文件名称
'''
# 1.计算整体波动量
day_summary = df.iloc[:, -1].groupby(df.iloc[:, 0]).sum() # 按天求和汇总
day_change_value = day_summary.diff(1).rename('change') # 通过差分求平移1天后的变化量
day_change_rate = (day_change_value.shift(-1) / day_summary).round(3).rename('change_rate').shift(1) # 求相对昨天的环比变化率
day_summary_total = pd.concat((day_summary, day_change_value, day_change_rate), axis=1) # 整合为完整数据框
# 2. 定义变量
dimension_list = df.columns[1:-1].to_list() # 分析的维度列表
# 分析日期
the_day = datetime.datetime.strptime(date, "%Y-%m-%d") # 指定要分析的日期
previous_day = the_day - datetime.timedelta(1) # 自动获取前1天日期
# 日期列名
day_col1 = datetime.datetime.strftime(the_day,'%Y-%m-%d')
day_col2 = datetime.datetime.strftime(previous_day,'%Y-%m-%d')
# 数据对象
the_data = df[df.iloc[:,0] == the_day].rename(columns={df.columns[-1]: day_col1}) # 获得指定日期数据
previous_data = df[df.iloc[:,0] == previous_day].rename(columns={df.columns[-1]: day_col2}) # 获得前1天日期数据
# 合并两天的数据
data_merge = the_data.iloc[:,1:].merge(previous_data.iloc[:,1:],on=dimension_list,how='outer')
# 替换没有匹配的数据为0
data_merge = data_merge.fillna(0)
# 计算相对昨天的环比变化率
data_merge['change'] = data_merge[day_col1]-data_merge[day_col2] # 变化量
# 整体对象
nums, change, change_rate = day_summary_total[day_summary_total.index == the_day].values[0]
top_nodes = {'total':'整体','change':change,'change_rate':change_rate}
# 3. 自动节点分解
main_nodes = [] # 主节点
other_nodes = [] # 其他节点
hidden_nodes = [] # 潜在节点
main_edges = [] # 主边
other_edges = [] # 其他边
dim_copy = dimension_list+[day_col2,'change']
for ind,dimension in enumerate(dimension_list): # 遍历每个维度
each_data = data_merge[dim_copy[ind:]] # 筛选数据
each_merge_temp = each_data.groupby([dimension],as_index=False)[[day_col2,'change']].sum() # 计算变化量
each_merge_temp = each_merge_temp.sort_values(['change']) # 排序
each_merge_temp['each_change_rate'] = each_merge_temp['change']/each_merge_temp[day_col2] # 环比变化率
previous_all = each_merge_temp.sum().iloc[1] # 总初始量
change_all = each_merge_temp.sum().iloc[2] # 总变化量
each_merge = each_merge_temp.drop(day_col2,axis=1) # 丢弃当日visit数值列
if change_all<0: # 下降
# node
main_values_temp = each_merge_temp.iloc[0].tolist()
main_values = each_merge.iloc[0].tolist() # 主因子节点
main_nodes.append(main_values)
other_nodes.append([f'{dimension}-others',change_all-main_values_temp[2],(change_all-main_values_temp[2])/(previous_all-main_values_temp[1])])
if each_merge.iloc[-1].tolist()[1]>0:
hidden_nodes.append(each_merge.iloc[-1].tolist()) # 当其他因子含有上升的计为潜在因子
else:
hidden_nodes.append([])
# 数据过滤
data_merge = each_data[each_data[dimension]==each_merge.iloc[0].iloc[0]]
else: # 上升
# node
main_values_temp = each_merge_temp.iloc[-1].tolist()
main_values = each_merge.iloc[-1].tolist() # 其他因子节点
main_nodes.append(main_values)
other_nodes.append([f'{dimension}-others',change_all-main_values_temp[2],(change_all-main_values_temp[2])/(previous_all-main_values_temp[1])])
if each_merge.iloc[0].tolist()[1]<0:
hidden_nodes.append(each_merge.iloc[0].tolist()) # 当其他因子含有下降的计为潜在因子
else:
hidden_nodes.append([])
# 数据过滤
data_merge = each_data[each_data[dimension]==each_merge.iloc[-1].iloc[0]]
# edge
edge_values = main_values[1]/float(change_all)
main_edges.append(edge_values)
other_edges.append(1-edge_values)
# 4. 画图展示
# 定义各个节点的样式
node_style = '<<table border="0"><tr><td width="20"><table border="1" cellspacing="0" VALIGN="MIDDLE"><tr><td bgcolor="{0}"><font color="{1}"><B>{2}</B></font></td></tr><tr><td>环比变化量:{3:d}</td></tr><tr><td>环比变化率:{4:.2%}</td></tr></table></td></tr></table>>'
edge_style = '<<table border="0"><tr><td><table border="0" cellspacing="0" VALIGN="MIDDLE" bgcolor="#ffffff"><tr><td>{0}</td></tr><tr><td>贡献率:{1:.0%}</td></tr></table></td></tr></table>>'
attr_node = {'fontname': "SimHei", 'shape': 'box','penwidth' : '0'} # 定义node节点样式
attr_edge = {'fontname': "SimHei"} # 定义edge节点样式
attr_graph = {'fontname': "SimHei", 'splines': 'ortho','nodesep' : '2'} # Graph的总体样式
# 定义左侧父级图
parent_dot = Digraph(format='png', graph_attr=attr_graph, node_attr={'shape': 'plaintext', 'fontname': 'SimHei'})
features = ['all']+dimension_list
parent_edge = [(features[i],features[i+1]) for i in range(len(features)-1)]
parent_dot.edges(parent_edge)
# 定义右侧子级图
child_dot = Digraph(node_attr=attr_node, edge_attr=attr_edge) # 创建有向图
for tree_depth in range(len(main_nodes)): # 循环读取每一层
split_node_left = main_nodes[tree_depth]
split_node_right = other_nodes[tree_depth]
split_node_hidden = hidden_nodes[tree_depth]
if tree_depth == 0:
# 增加顶部节点
node_name = top_nodes['total']
node_top_label = node_style.format( 'black',"white",node_name,
int(top_nodes['change']),
top_nodes['change_rate']) # 分别获取顶部节点名称、变化量和变化率
child_dot.node(node_name, label=node_top_label) # 增加顶部节点
else:
node_name = main_nodes[tree_depth - 1][0] # 将上级左侧分裂节点作为下级节点的source
# 增加node信息
node_label_left = node_style.format("#184da5","white",split_node_left[0],
int(split_node_left[1]),
split_node_left[2]) # 左侧节点显示的信息
node_label_right = node_style.format("#d3d3d3","black",split_node_right[0],
int(split_node_right[1]),
split_node_right[2]) # 右侧节点显示的信息
if split_node_hidden!=[]:
node_label_hidden = node_style.format("#72a518","black",split_node_hidden[0],
int(split_node_hidden[1]),
split_node_hidden[2]) # 潜在节点显示的信息
# 增加边信息
edge_label_left = edge_style.format('主因子',main_edges[tree_depth]) # 左侧边的标签信息
edge_label_right = edge_style.format('其他因子',other_edges[tree_depth]) # 右侧边的标签信息
# 节点和边画图
child_dot.node(split_node_left[0], label=node_label_left) # 增加左侧节点
child_dot.node(split_node_right[0], label=node_label_right) # 增加右侧节点
if split_node_hidden!=[]:
child_dot.node(split_node_hidden[0], label=node_label_hidden) # 增加隐藏节点
child_dot.edge(node_name, split_node_left[0], label=edge_label_left) # 增加左侧边
child_dot.edge(node_name, split_node_right[0], label=edge_label_right) # 增加右侧边
if split_node_hidden!=[]:
child_dot.edge(split_node_right[0], split_node_hidden[0],label = '潜在因子') # 增加隐藏节点边
parent_dot.subgraph(child_dot)
parent_dot.view(file_name) # 展示图形结果
# 读取数据
raw_data = pd.read_csv('advertising_data.csv')
# 数据预览
raw_data.head()
以上数据如果有需要的同学可关注公众号HsuHeinrich,回复【Python08】自动获取~
| date | source | site | channel | media | visit | |
|---|---|---|---|---|---|---|
| 0 | 2018/5/15 | 品牌营销_品牌词 | 品牌词产品 | 播放器播放标签 | PC | 17600 |
| 1 | 2018/5/15 | 手机_品牌营销_品牌词 | 品牌词广告 | 15秒前贴片_app | app | 15865 |
| 2 | 2018/5/15 | SEO | 百度 | WAP | - | 10858 |
| 3 | 2018/5/15 | 手机_品牌营销_品牌词 | 品牌词运营 | 移动端_乐见 | app | 9768 |
| 4 | 2018/5/15 | SEO | 百度 | PC | - | 9228 |
# 数据处理要求:缺失值填充、日期字段转日期格式、维度字段转字符串格式
# 替换字符为0然后转换为整数型 本案例无缺失值,如果有缺失值需要额外处理
raw_data['visit'] = raw_data['visit'].replace('-', 0).astype(np.int64)
# 将日期字段转换为日期格式
raw_data['date'] = pd.to_datetime(raw_data['date'])
# 维度列转为字符串格式
col2str_list = ['source','site', 'channel', 'media']
raw_data[col2str_list] = raw_data[col2str_list].astype(str)
print('{:*^60}'.format('数据类型:'))
print(raw_data.dtypes)
***************************数据类型:****************************
date datetime64[ns]
source object
site object
channel object
media object
visit int64
dtype: object
# 绘制节点树图
autoNodeTree(raw_data, '2018-06-07', 'structure_dim_node_tree')
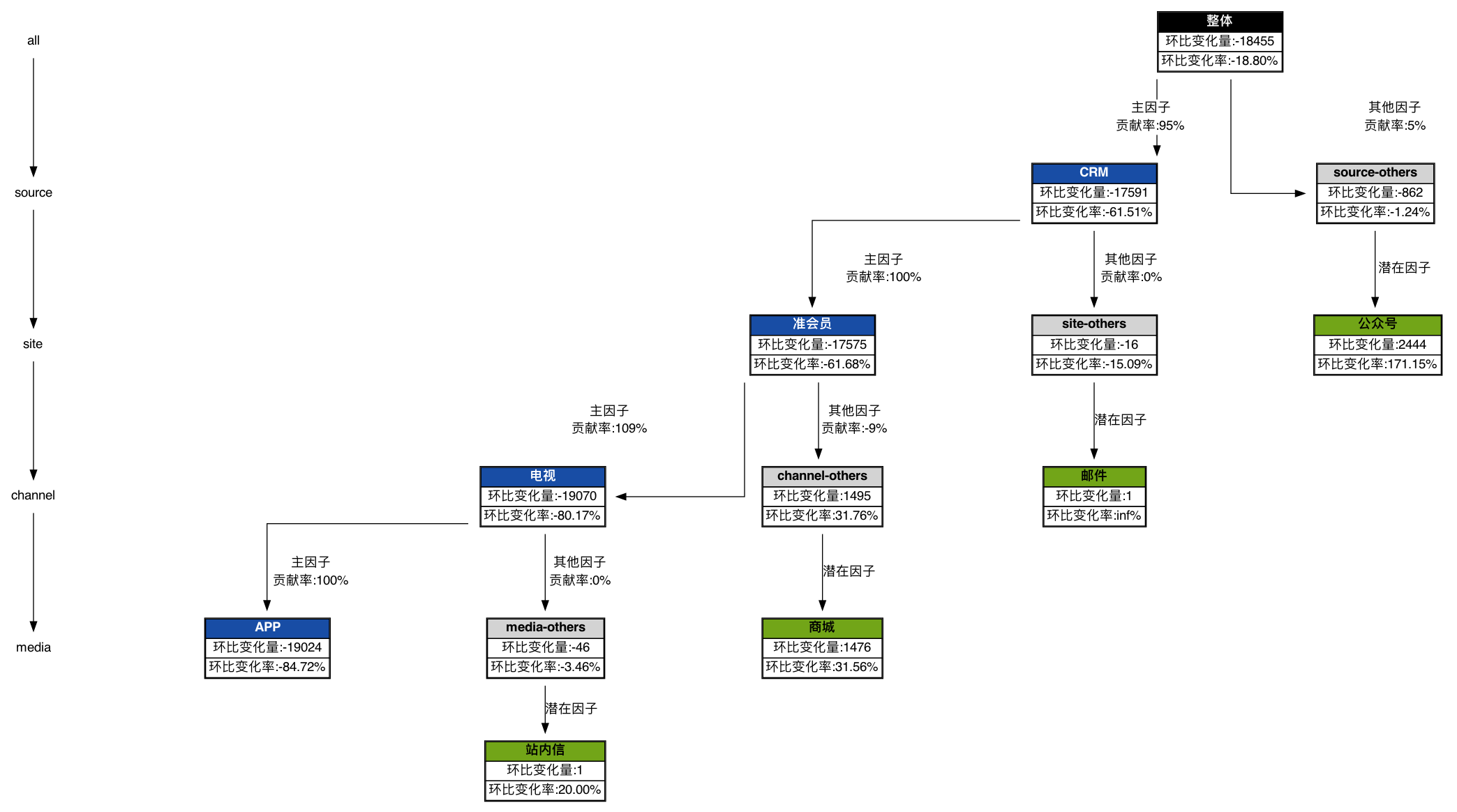
这张图能清晰的知道,在2018-06-07日整体流量下降了18.8个百分点,主要是因为CRM渠道造成的,而CRM环比下降了17591基本都是准会员下降造成的。以此类推,直至最后一层。而且针对逆势上涨最明显的细分群体标记为潜在因子,提醒相关人员注意。
共勉~















 763
763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









