







时间序列预测(三)基于Prophet+XGBoost的销售额预测
前面我们介绍了如何使用Prophet和LSTM,不知道你们发现了没有,前者似乎太简单了,后者呢好像又很复杂。那有没有什么很好的方法能很好的中和下呢?
已知的有,Prophet能很好的分解时间趋势,LSTM可以将其他信息加入训练,同样的如果没有时间序列,XGBoost也是可以训练其他信息进行预测的,那如果将Prophet分解的时间趋势也作为特征加入训练呢?是不是就兼顾了时间趋势和额外信息了。本文参考自将梯度提升模型与 Prophet 相结合可以提升时间序列预测的效果。
数据探索
以下数据如果有需要的同学可关注公众号HsuHeinrich,回复【数据挖掘-时间序列01】自动获取~
# 读取数据
raw_data = pd.read_csv('train.csv')
raw_data['datetime'] = raw_data['datetime'].apply(pd.to_datetime)
df_px = raw_data[['datetime', 'count']].copy()
df_px.rename(columns={'datetime': 'ds', 'count': 'y'}, inplace=True)
特征工程
# 切分数据集
num = 24*14 # 将最后2周划分为测试集
train, test = df_px.iloc[:-num,:], df_px.iloc[-num:,:]
# 模型拟合
m = Prophet(
growth='linear',
seasonality_mode='additive',
interval_width=0.95,
daily_seasonality=True,
weekly_seasonality=True,
yearly_seasonality=False
)
m.fit(train)
<fbprophet.forecaster.Prophet at 0x7ff4e4fec730>
# 训练集提取preheat特征
predictions_train = m.predict(train.drop('y', axis=1))
# 测试集提取preheat特征
predictions_test = m.predict(test.drop('y', axis=1))
# 合并
predictions = pd.concat([predictions_train, predictions_test], axis=0)
# 将prophet的结果作为特征
df = pd.merge(raw_data, predictions, left_on=['datetime'], right_on=['ds'], how='inner')
df.drop('ds', axis=1, inplace=True)
df.set_index('datetime', inplace=True)
# 构造yhat滞后值
for lag in range(1,6):
df[f'yhat_lag_{lag}'] = df['yhat'].shift(lag)
# 构造XGBR数据集
X = df.drop('count', axis=1)
y = df['count']
# 切分数据集
X_train, X_test = X.iloc[:-num,:], X.iloc[-num:,:]
y_train, y_test = y.iloc[:-num], y.iloc[-num:]
模型拟合
# 模型拟合
model_xgbr = XGBRegressor(random_state=0) # 建立XGBR对象
model_xgbr.fit(X_train, y_train)
# 预测结果
pre_y = model_xgbr.predict(X_test)
# 评估指标
model_metrics_functions = [explained_variance_score, mean_absolute_error, mean_squared_error,r2_score] # 回归评估指标对象集
model_metrics_list = [[m(y_test, pre_y) for m in model_metrics_functions]] # 回归评估指标列表
regresstion_score = pd.DataFrame(model_metrics_list, index=['model_xgbr'],
columns=['explained_variance', 'mae', 'mse', 'r2']) # 建立回归指标的数据框
regresstion_score # 模型回归指标
| explained_variance | mae | mse | r2 | |
|---|---|---|---|---|
| model_xgbr | 0.999706 | 1.984595 | 8.782559 | 0.999703 |
结果展示
# 模型效果可视化
fig = plt.figure(figsize=(16,6))
plt.title('True and XGBR result comparison', fontsize=20)
plt.plot(y_test, color='red')
plt.plot(pd.Series(pre_y, index=y_test.index), color='green')
plt.xlabel('Hour', fontsize=16)
plt.ylabel('Number of Shared Bikes', fontsize=16)
plt.legend(labels=['True', 'Pre_y'], fontsize=16)
plt.grid()
plt.show()
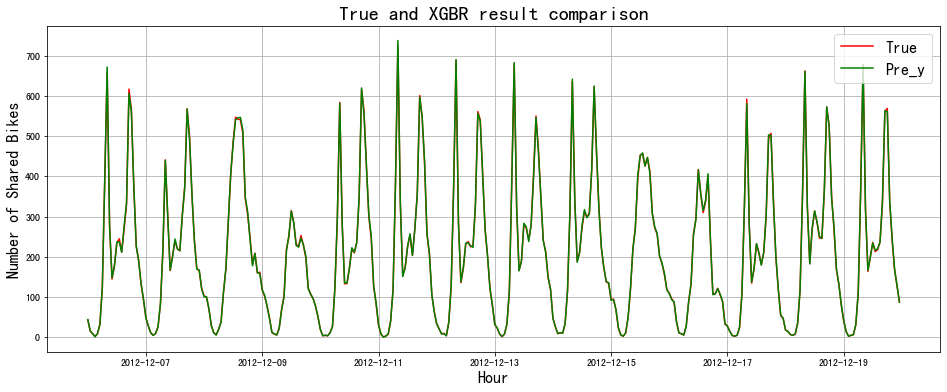
哇塞,这预测结果有点夸张了。。。
# 输出特征重要性
features = X.columns # 获取特征名称
importances = model_xgbr.feature_importances_ # 获取特征重要性
# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['features'] = features
importances_df['importance'] = importances
importances_df = importances_df.sort_values('importance', ascending=False)
importances_df.head(10)
| features | importance | |
|---|---|---|
| 9 | registered | 0.939968 |
| 8 | casual | 0.058634 |
| 27 | yhat | 0.000115 |
| 32 | yhat_lag_5 | 0.000109 |
| 29 | yhat_lag_2 | 0.000101 |
| 15 | additive_terms | 0.000098 |
| 28 | yhat_lag_1 | 0.000098 |
| 31 | yhat_lag_4 | 0.000091 |
| 18 | daily | 0.000081 |
| 12 | yhat_upper | 0.000076 |
可以看到,除了时间趋势外,其他的一些因素也起到很重要影响
总结
基于Prophet、LSTM和Prophet+XGBoost这三种方法,相信大家在做时间序列预测相关的任务时,应该可以得心应手了~
共勉~

















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









