






T-LESS: An RGB-D Dataset for 6D Pose Estimation of Texture-less Objects
该数据集网址已公开:http://cmp.felk.cvut.cz/t-less/
摘要:该数据集采集的目标为工业应用、纹理很少的目标,同时缺乏区别性的颜色,且目标具有对称性和互相关性,数据集由三个同步的传感器获得,一个结构光传感器,一个RGBD sensor,一个高分辨率RGBsensor,从每个传感器分别获得了3.9w训练集和1w测试集,此外为每个目标创建了2个3D model,一个是CAD手工制作的另一个是半自动重建的。训练集图片的背景大多是黑色的,而测试集的图片背景很多变,会包含不同光照、遮挡等等变换(之所以这么做作者说是为了使任务更具有挑战性)。
Intoduction:
无纹理的刚性物体在人类环境中很常见,检测和精确定位它们来自图像出现在各种应用中。刚性物体的姿态具有六个自由度,即三个
旋转和三个平移,以机器人技术为例,6D对象姿势有助于空间推理并允许最终执行者对一个物体采取行动。

纹理的缺乏导致物体的检测无法依赖传统的光学局部信息和描述子(即局部颜色特征信息),但是近年来缺乏纹理的目标可以依赖于3D特征,可以依赖梯度信息和深度信息。
本实验采用的设备:
1.结构光RGBD sensor:Primesense Carmine 1.09
2.RGBD sensor:Microsoft Kinect v2
3.RGB camera:Canon IXUS
这些传感器都是时间同步的,且具有相同的视角(怎样做到具有相同的视角)。
接下来作者介绍了一些其他的数据集,令人印象深刻的有:1.A new benchmark for pose estimation with
ground truth from virtual reality(使用合成的方式创建数据集)
同时作者解释了本数据集的优势在于:1.大量跟工业相关的目标;2.训练集都是在可控的环境下抓取的;3.测试集有大量变换的视角;4.图片是由同步和校准的sensor抓取的;5.准确的6D pose标签;6.每个目标有两种3D模型;

作者制作数据的过程:
1.数据由上图的装置获取,有一个转盘,待检测物体房子啊转盘上,夹具上安装着sensor,角度是可以调节的,标记块用于标记相机姿态(外参),标记块固定在转盘上,标记块垂直地延展到了转盘外面,是为了提升在较低的立体面的姿态预测。为了获取训练数据,object被放在转盘的中央,后面是一个黑色的背景,这是为了保证在所有的立体面都是黑色的背景。在测试集的获取上,我们将物体放在标记块上,或者在物体下面放上本或者其他东西来制造背景。object表面的深度在0.53m-0.92m,Carmine RGBD相机的井深在0.35-1.4m,Kinect的在0.5~4.5m。

2.传感器的标定
相机的内参和畸变系数是由标准棋盘格和opencv软件完成的。所有传感器都是同步的,且外在与转盘进行了校准。传感器必须同步,因为图片是在转盘转动的时候采集的。外参的获取是通过BCH码的Markers,图像采集检测可以获取它们的2D坐标,同时又已知它们的2D坐标,就可以得到一系列2D~3D点对,然后通过PnP算法求解相机姿态,然后通过非线性优化最小化累计误差,关于像素点在图片当中的最小均方误差,1.27 px for Carmine, 1.37 px for Kinect, and 1.50 px for Canon。因为整体误差不止有内参矫正误差,还有角点检测误差,还有传感器姿态估计偏差,所以整体的偏差比上述的要大。
3.训练集和测试集
对于纹理较少的目标,通常的检测方案是采用模板匹配,对每一个目标从不同角度采集图片,造模板的话,从85度到-85度,每个10度取一个角度,然后偏正角每隔5度取一个角度,这样每个目标就可以造1872个训练集,但由于物体是对称的,只取上半视野即可得到所有情况的样本,取85度到5度即可。测试集的话取75度到5度、偏正角仍然5度一取,所以每个目标一共有772=502张图片。为了移除图片中不相关的部分,我们需要对图片进行裁剪,为了让背景否都变成黑色,我们通过CAD模型在相机内外参下的映射获取背景Mask,把Mask涂黑,去除Marker的影响。
4.深度修正(Depth Correction)
RGBD获取的深度信息也是有偏差的,深度修正主要是通过Marker,首先取出0.53 –0.92 m 的点(这是object出现的位置),根据Marker PnP获取深度采用多项式公式对其进行修正,修正后sensor的深度信息误差大大减小,Carmine从12.4 mm to 2.8 mm,Kinect从7.0 mm to 3.6 mm。

5.3D模型
对于每一个目标,我们要创建一个手工的CAD模型和一个半自动重建的模型。模型都是以3D网格以及顶点法线的格式提供。表面颜色信息只在重建模型中存在,两个模型都有用MeshLab针对每个顶点计算法线。
重建模型由fastfusion创建(是一个Steinbrucker提供的3D映射系统)。fastfusion的输入是从Carmine获得RGBD图像以及通过Marker获得的相机姿态,对于每一个目标,两个局部的模型先进行重建,一个是“上半球”的视野,一个是“下半球"的视野,这两个局部模型用ICP算法对顶点进行对齐。之后是人工肉眼精修,看表面的颜色细节是否正确。最后的精修是依赖于相机的姿态,将其映射到基准帧,更新姿态,从所有图片中去重建模型原貌。当然,模型当中会包含一些小错误需要人工剔除,比如金属、光滑、透明的表面的深度信息往往是不正确的,需要剔除。重建模型通过ICP算法校准到CAD模型,精修过程是手工的。通过ICP算法来评估这两种模型,平均距离差为1.01mm,对于大小几十甚至几百毫米的物体来说,这个差距很小,但是还是有区别的,CAD模型包含一些内面的部分。

6.Ground Truth Poses
为了给测试图获取6D姿态标签,要建立密集的场景的3D模型,这有504张RGBD图和Marker标记出的姿态完成。用目标的CAD模型手工对准场景模型,为了提高准确性,将目标模型渲染到高分辨率的场景模型,并且手工调整误对准的地方直到满意为止。最终的转换姿势就是标签姿态。
下面来验证6D标签的准确性:
把通过Marker获取姿态的渲染深度和sensor获取的深度进行相减,如果超过5cm就认为是outlier,是外点的原因主要有以下两点:1.sensor获取的深度信息不准2.目标有部分被遮挡;
Carmine抓取的深度信息比较准确,与渲染的深度差值近乎于0,对于Kinect,我们发现RGB图和深度图有些轻微的失调。
接下来是实验部分:
我们在Hodan提出的6d定位方案上进行试验,其输入是图片以及目标在图片中的位置,目的是获取目标的6D姿态。我们拿Carmine获取的RGBD图进行实验,CAD模型可以用于之前提到的Pose精修,loss如下(通过预测姿态和标签姿态造成的平均实际距离差):
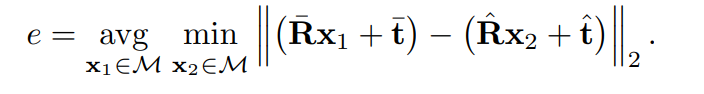
当e<=k*d的时候视为预测正确,k=0.1,d是所有模型法线对的最大距离(也就是目标直径),目标至少有10%的可见度才考虑此评估。从下图可以看出,遮挡是对结果准确度影响最大最严重的。

5.0总结
本文提供了数据集 T-LESS,针对工业相关无纹理对称目标。且提供了多样的传感器信息和精准的ground_truth,运用数据集进行初步的结果评估发现6D姿态检测还有很大的进步空间。
个人总结
抛开各种修正算法,就是用Marker获取的姿态作为ground truth,然后处理图像,将网络输入的图像中的Marker涂成黑色。















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









