






原文地址:https://chenhsuanlin.bitbucket.io/3D-point-cloud-generation/paper.pdf
摘要:
对于3D物体的重建,信息主要丰富在表面。本文的目的在于以密集点云的形式表示3D模型,
这边文章讲的就是用2D图像如何生成3D模型。2D图像也是从3D的世界投影来的,从3D到2D必然是缺少了很多信息的,所以单一视角的2D图像是不可能恢复出3D模型的。如果非要的必须要有一些先验知识。
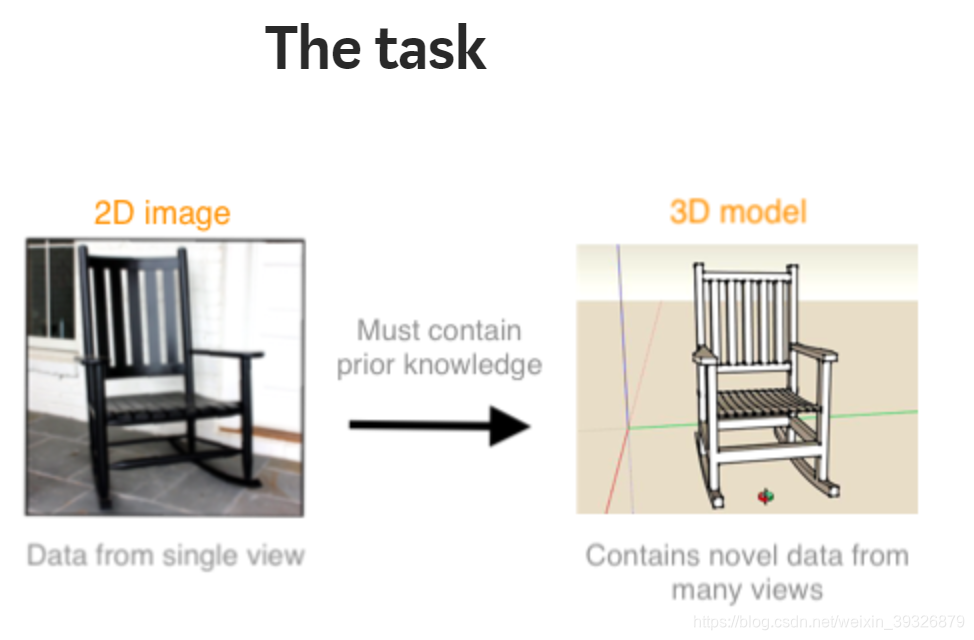
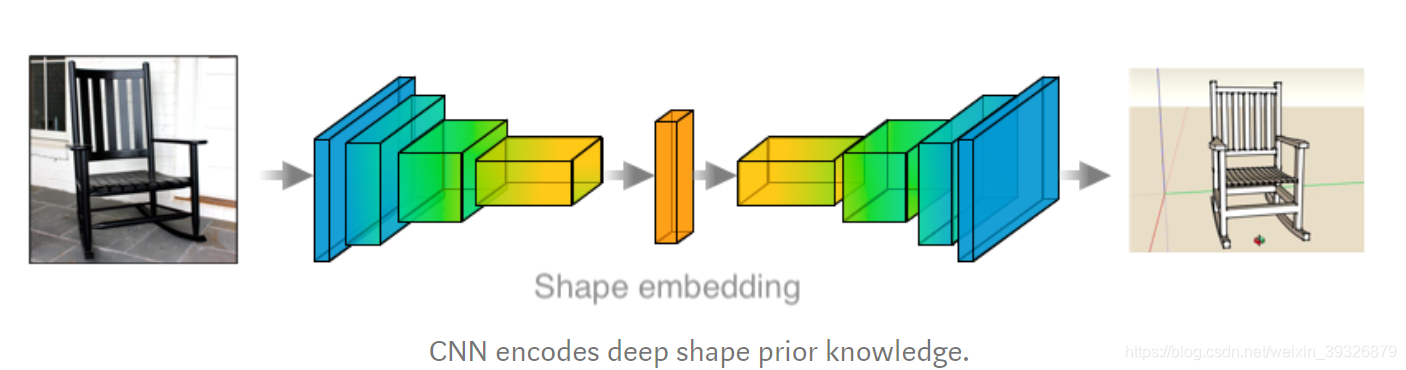
作者说采用这种编码解码学习一个压缩的表达,是最有希望的方式(黑人问号?)
关于3D模型的表达方式,有以下三种:
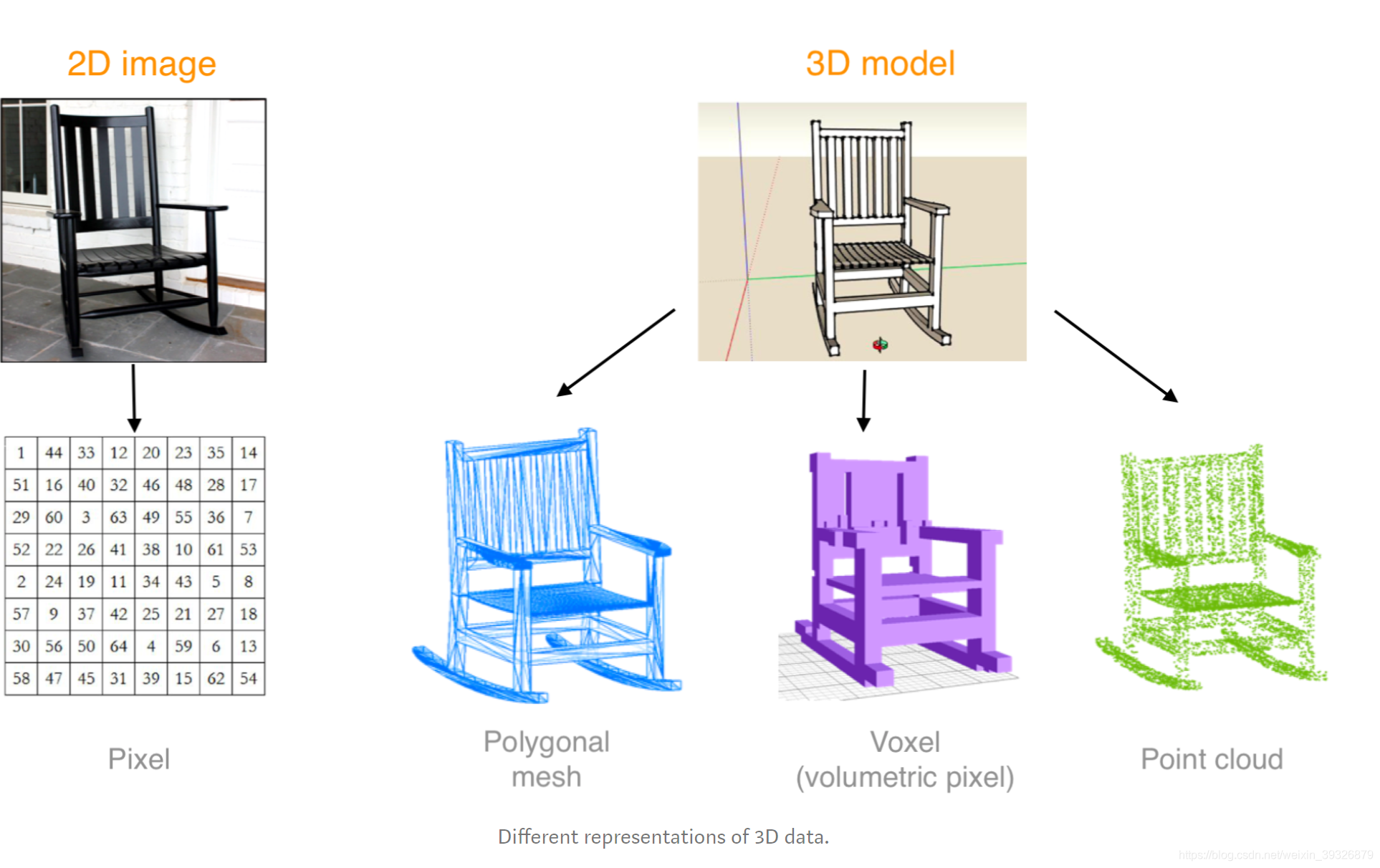
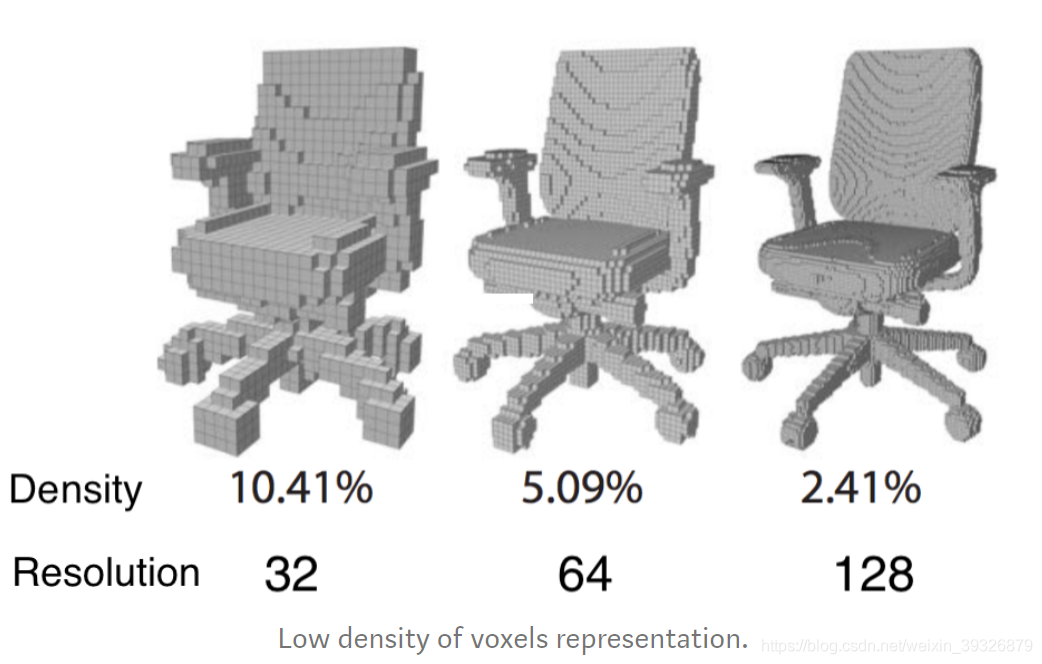
先看看体素网格:
体素网格就是用规则的有体积的小网格去表达3D模型,会损失一些细节,当分辨率越高,需要的小网格也就越多,但其实我们只需要表面的,所以就算量比较大,要衡量分辨率和计算量之间的权衡,不过这种表达方式还是比较容易地输入到CNN里面。
多边形网丝:由顶点、边缘和朝向(定义表面的3要素)组成,它可以抓住细小的细节。
点云:(x,y,z),点云数量越多表达的越细节。
以上两个优点在于表达细腻,但是不能直接用于CNN网络
方案:
我们使用点云紧实的的表达和传统的2d 卷积,学习先验的形状信息。
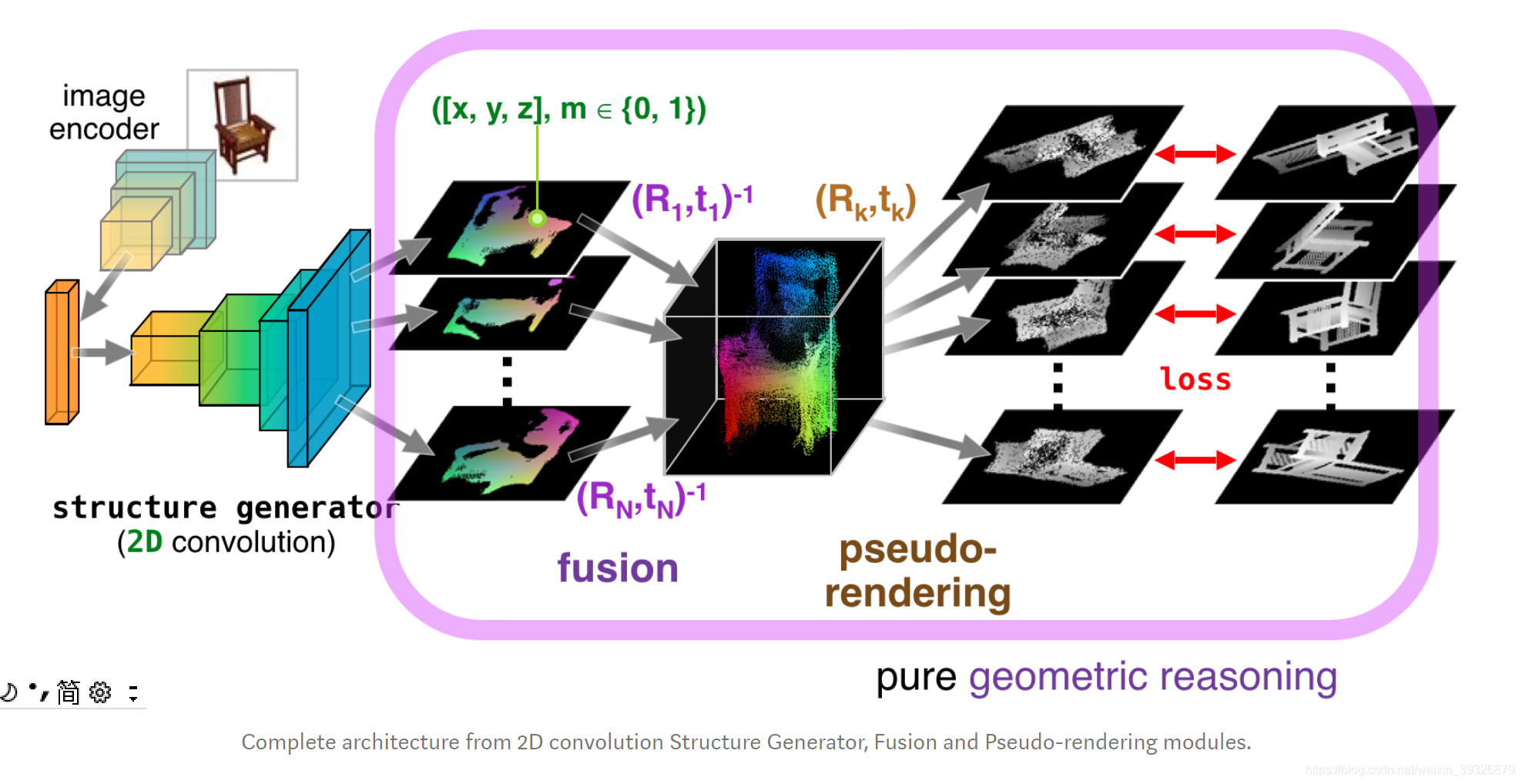
第一步:3D结构生成器
该模块根据2D的RGB图和物体对应的binary mask预测像素点的三维坐标(x,y,z),
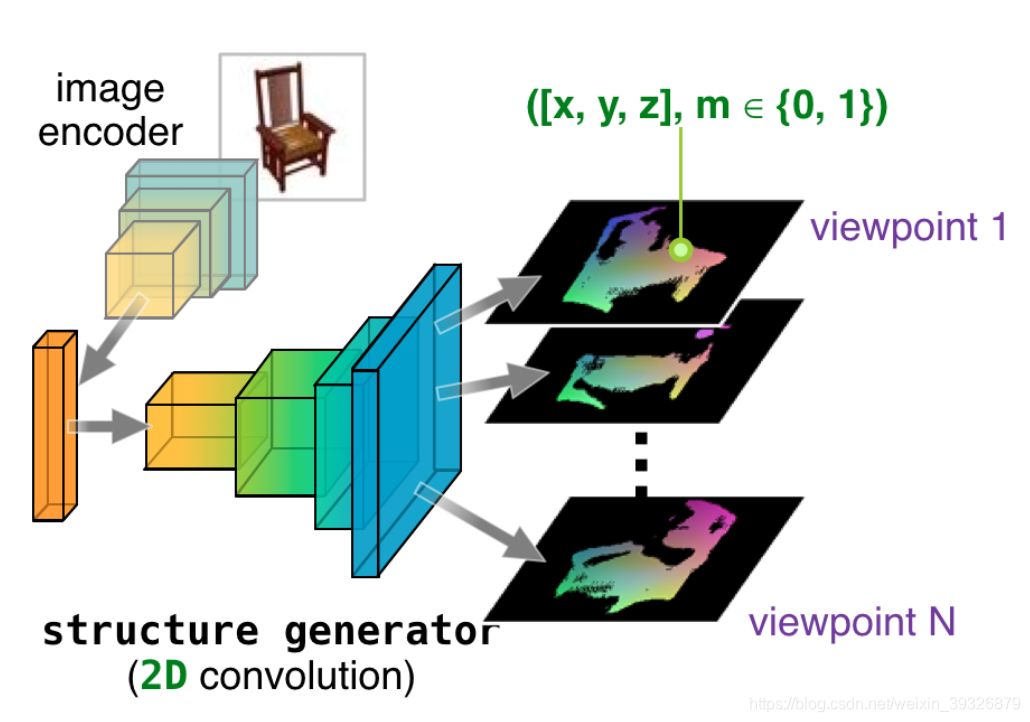
该步骤的输入输出为:

其中:2D projection == 3D coordinates (x,y,z) + binary mask (m)
第二步:Point Cloud Fusion(点云融合)
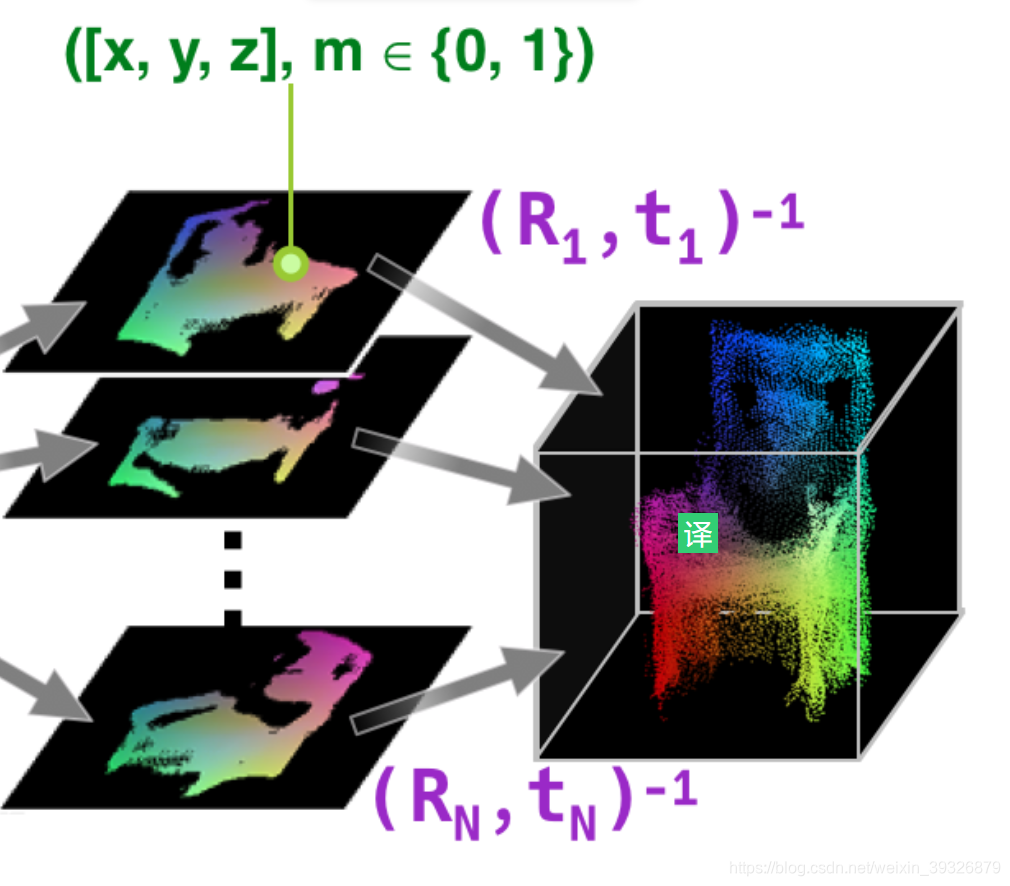
融合点云成3D模型,这是可行的(因为每幅图像对应的3D姿态是固定的且事先知道的)
其输入输出如下:

第三步:根据3D模型生成新的2D投影,跟GroundTruth比对计算loss
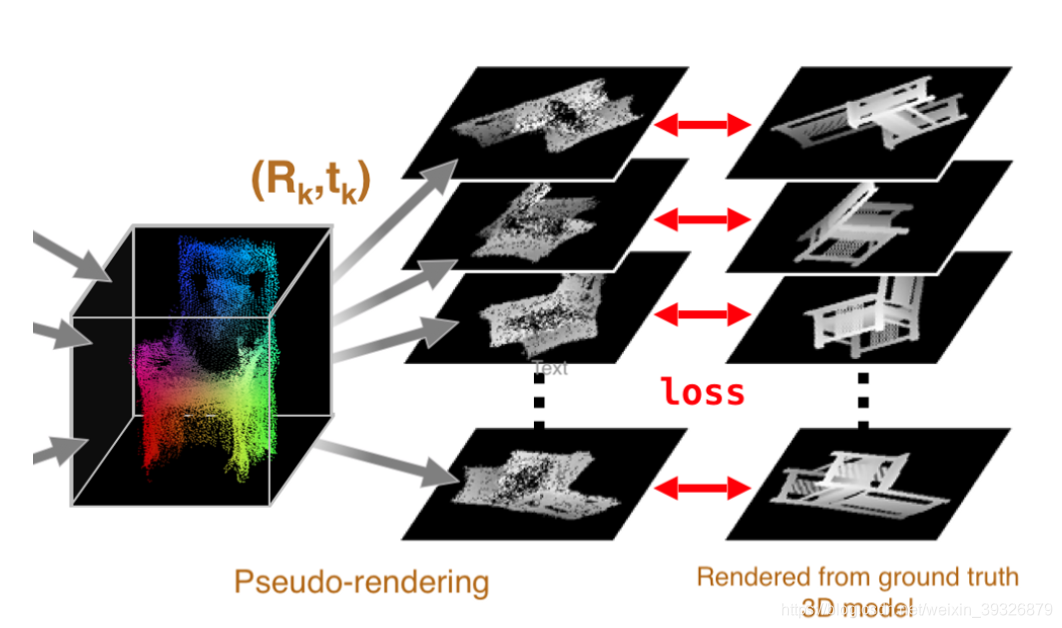
其输入输出如下:
也就是说如果生成的3D模型是接近真实的,那么新视角的投影应该也是接近真实的ground_truth
总体的流程如下图所示:
结果对比:
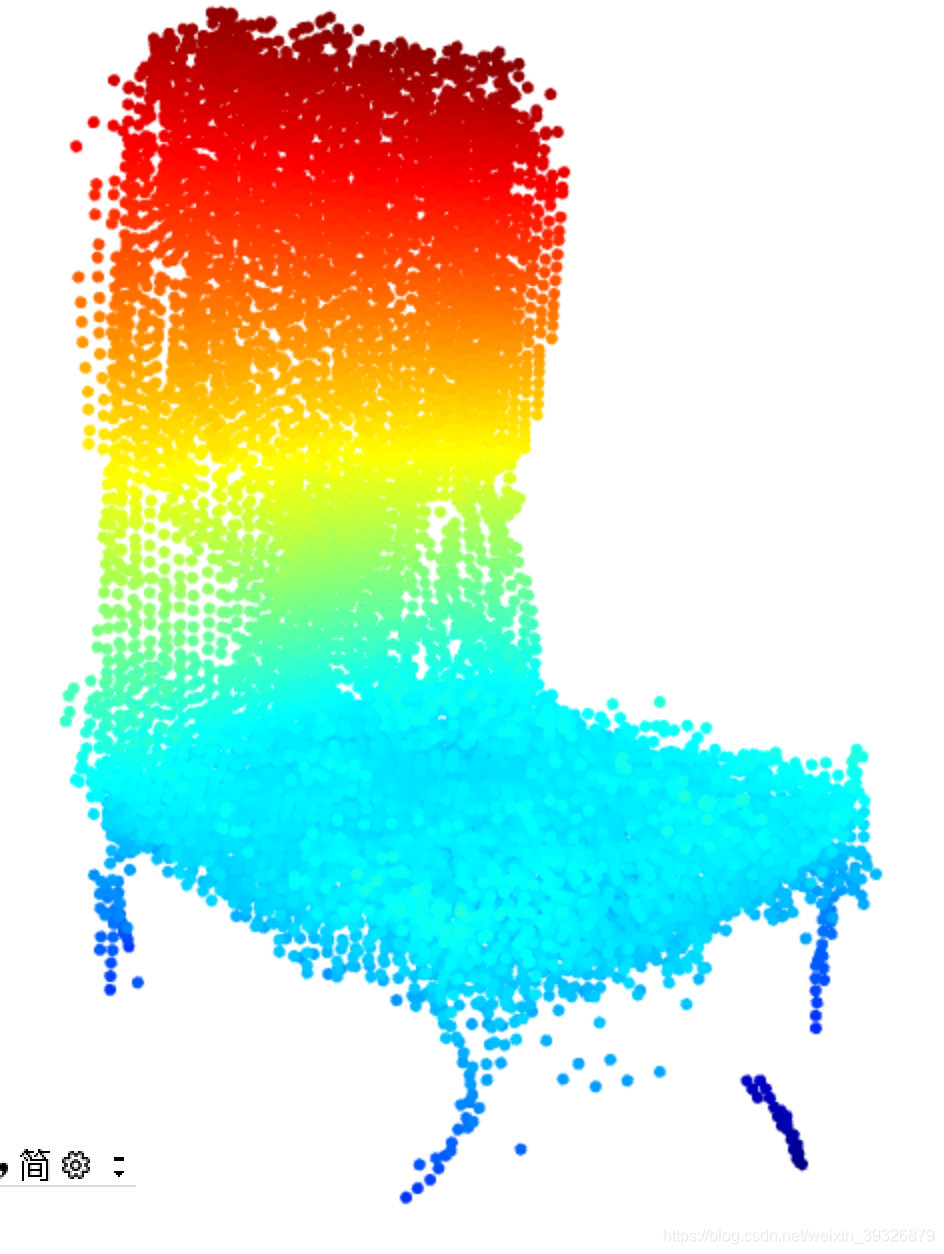
下图是真实的点云信息和生成的点云信息的对比:

最终的结果:

总结:
本文确实是从一系列的2D图像以及每张图片对应的映射矩阵生成3D模型,最聪明的举动在于融合和新角度的渲染生成,陈生了差异以及几何意义,利用这种差异我们才能从2D投影学习到3D点云。
代码地址:
Pytorch code: https://github.com/lkhphuc/pytorch-3d-point-cloud-generation
Tensorflow code: https://github.com/chenhsuanlin/3D-point-cloud-generation
Paper: https://arxiv.org/abs/1706.07036
Original project website: https://chenhsuanlin.bitbucket.io/3D-point-cloud-generation/

















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









