






self-attention简介
什么是self-attention?
self-attention顾名思义,就是自注意力机制,简单理解,就是将输入乘以一个矩阵(attention mask),获得输出的过程。那么这个attention mask怎么获得呢?attention mask也是根据输入本身得到的,1.可以通过对输入进行神经网络变换得到;2。大部分通过点积的方式(矩阵相乘,即经典的q,k,v);
self-attention的目的是什么?
其目的在于:1.融合全局信息对当前的像素信息进行编码;2.对于全局信息赋予不同权重;
本质self-attention在图像算法的应用是为了弥补CNN的不足;CNN是基于卷积的深度网络,其有哪些不足呢?1.卷积核的感受野是有限的,一定下采样范围内只能覆盖到局部像素的信息;2.卷积核是参数共享的,只能对卷积核大小范围内的像素做到不同注意力,整体范围内是参数共享的;当然不可否认,卷积这种方式也具有其天然的优势:1.参数量少,易于训练;2.平移不变性的特征很适合图像任务;
self-attention详细介绍
首先,将输入X乘以不同的系数,我们可以得到Q、K、V
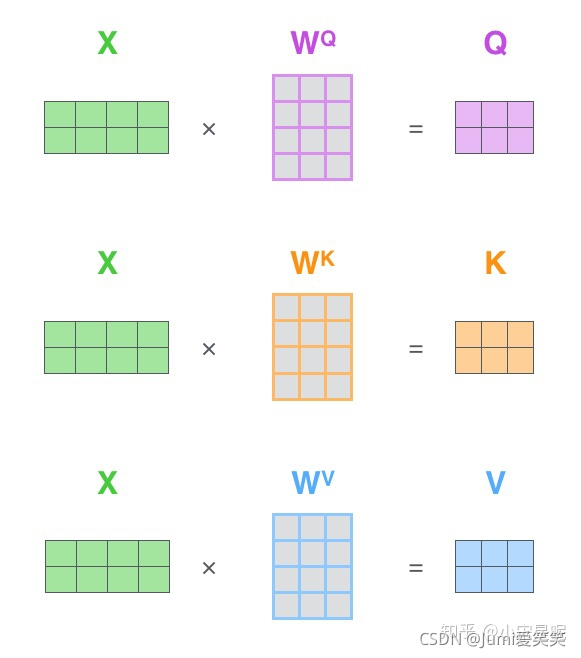
接下来,Q、K矩阵相乘以后,可以得到attention系数矩阵,将其进行缩放再进行softmax,得到的结果再乘以value值。
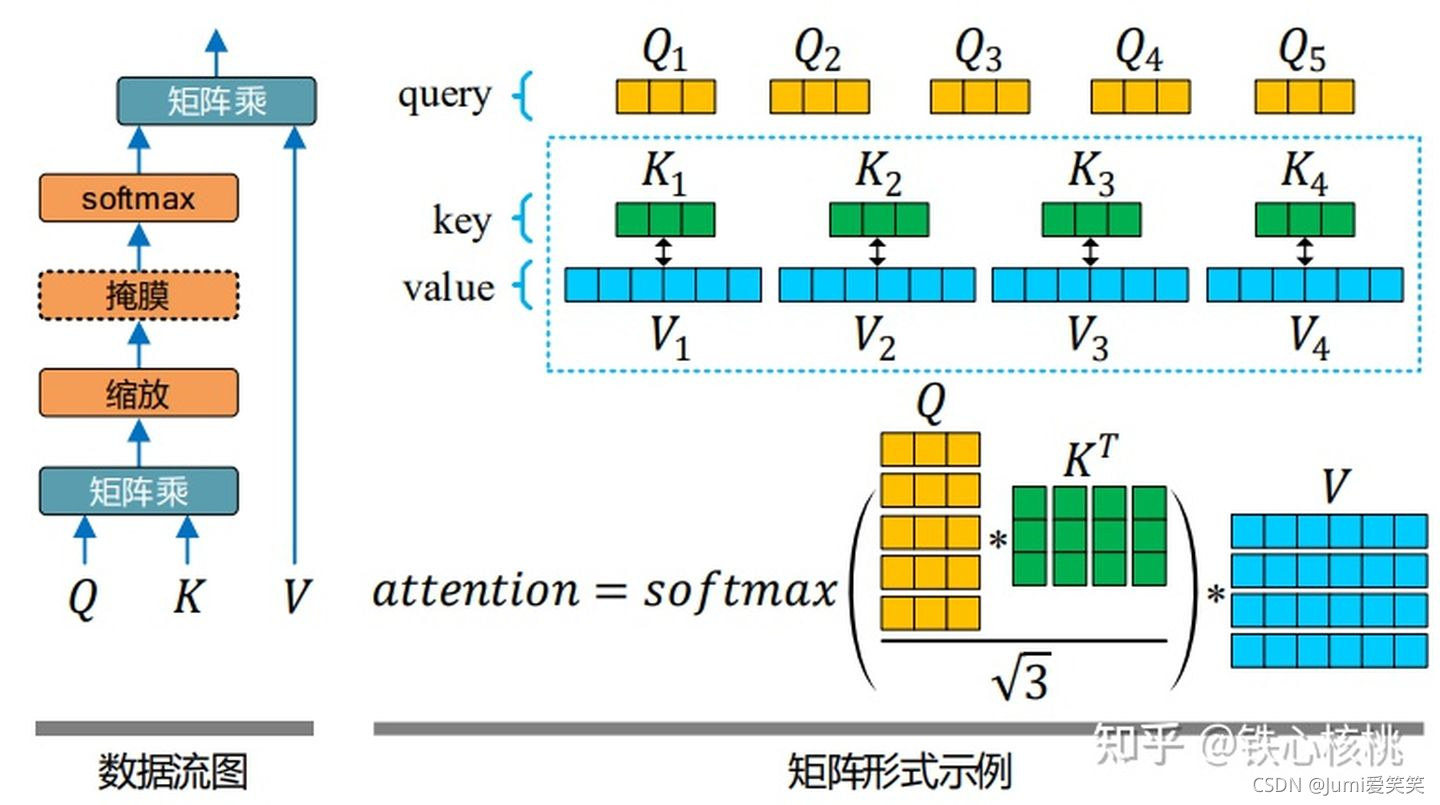
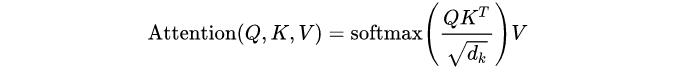
那么我们如何理解上述过程呢?
在机器翻译中,我们要根据当前词跟所有词之间的关系对该词进行编码,输出该词的翻译;
在图像任务中,我们要根据该像素与所有其他像素的关系对当前像素进行编码,输出分类;
所以本质上,我们需要找到当前单个输入与其他所有输入的关系,这个关系不一定对偶的,为了增加关系的丰富性,A相对于B的关系和B相对于A的关系可以是不同的;
其中Q是query,理解为索引,用query去寻找自己跟别人的关系,key是关键字,用来给别人寻找关系用的。Q、K为什么要相乘呢?
这个问题首先要有一个数学的先验知识,两个向量a和b同向,a.b=|a||b|;a和b垂直,a.b=0;a和b反向,a.b=-|a||b|。所以两个向量的点乘可以表示两个向量的相似度,越相似方向越趋于一致,a点乘b数值越大。Q、K相乘得到的是个系数,这个系数要乘上V,也就意味着二者相关性越强,加上这个value的权重值就越大。
求矩阵相关性的方式有:
1.求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值。
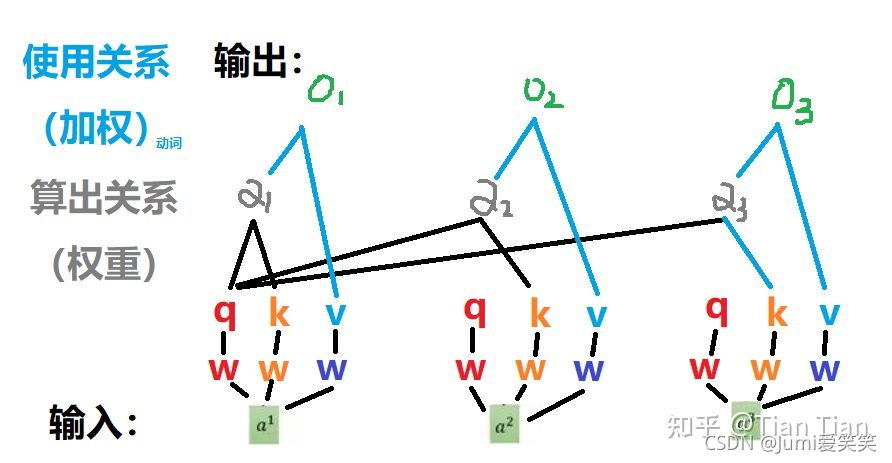
如下图所示:其中O1,O2,O3都是对输入a1的编码输出;
Q 、K相乘的结果为什么要除以scale?因为接下来要进行softmax,scale是为了让数据分布尽量在softmax梯度较大的位置;为什么要进行softmax呢?因为Q、K相乘可以得到系数矩阵,我们要将该系数矩阵进行归一化;
关于为什么要除以scale

















 2558
2558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









