







| 论文题目 | Fw-fuzz: A code coverage-guided fuzzing framework for network protocols on firmware |
|---|---|
| 工具名称 | Fw-fuzz |
| 论文来源 | CONCURRENCY AND COMPUTATION-PRACTICE & EXPERIENCE 2020 |
| 一作 | Zicong Gao(Cyberspace Security Department, State Key Laboratory of Mathematical Engineering and Advanced Computing, Zhengzhou, China) |
| 文章链接 | https://doi.org/10.1002/cpe.5756 |
论文概要
这篇论文针提出一种覆盖率导向的固件协议fuzzing方法。在物理设备上进行动态插桩。能够获取MIPS, ARM,PPC等架构固件程序的代码覆盖率。我觉得这个论文的亮点在于它的host-device的架构,并且实现跨平台获取代码覆盖率,这个框架是很方便的。但是,对于feedback引导变异这一块其实只是引导种子选择,它的remove机制也没有影响变异策略的意思,感觉这一块有待改进。目前没有找到开源代码。
论文背景
IOT设备的固件将一系列的软件集成在设备上以实现硬件与软件之间的交互,然而这些固件上的程序通常存在很多漏洞,需要我们对这些漏洞进行检测。
动机
黑盒的fuzzing工具无法知道程序的内部结构,因此会浪费大量的资源在生成无用的测试用例上;
AFL等现有的灰盒fuzzing没有办法通过解空间小的路径,且插桩不支持固件程序运行的环境;
白盒fuzzing需要源代码,但是固件通常不是开源的。
挑战
对嵌入式系统固件的协议进行fuzzing有以下挑战:错误检测、性能以及拓展性、插桩。
一些研究对固件进行全仿真或者部分仿真,但是仿真环境下执行和实际执行的数据流经常是不相同的,而且仿真所支持的架构受Qemu的限制。
当前的工具Peach,Boofuzz等都是黑盒fuzzing,需要用户定义输入生成的规则。DELTA,SecFuzz和Ruiiter则侧重于通过神经网络学习来生成输入而不是依靠feedback。
本文中列出的挑战:
- 测试用例生成效率低。对于协议的每个字段都进行测试效率很低。因此测试用例生成不仅仅要考虑协议的格式也要根据运行时的反馈信息动态的调整。
- 跨架构插桩。嵌入式系统的架构多种多样,在无源代码的情况下进行跨架构插桩很重要。
- 错误检测。固件很少有保护措施,导致很难直接观察到crash,因此需要捕获fuzzing期间的异常。
模型设计
框架
模型框架如上图,有4部分组成。控制模块用于调度其他模块,在host和设备之间传递控制指令。插桩模块在物理设备上进行插桩,反馈程序运行状态。传输模块用于给目标程序发送和接收网络数据包。测试用例生成模块不断地生成新的测试用例。并且整个框架分为两个部分host和device。

workflow
- 用户定义协议的模板文件作为初始输入。
- 控制模块吧控制指令发送给agent来提醒插桩执行器(instrumentation actuator)连接目标程序。
- 控制模块开启插桩调试器(instrumentation debugger)连接插桩执行器(instrumentation actuator)。
- 传输模块发送数据包给目标程序,一轮fuzzing开始。
- fuzzing过程中不断反馈运行信息给host。
- 插桩模块不断地捕获crash和异常。
- 测试用例生成模块根据反馈的信息变异测试用例。
- 进入下一轮的fuzzing,重复5-7。
具体实现
1. 跨架构插桩
使用GDB和Capstone实现跨架构。GDB可以在server模式下远程对不同架构下的程序进行调试。Capstone可以对二进制进行逆向分析。它也支持多架构。
首先要在目标设备上编译GDB server,然后建立GDB Server和GDB debugger之间的联系,使得debugger可以远程调试程序,并且可以让程序停在某一设置好的断点处。然后GDB可以获取内存信息、寄存器的值以及栈和堆的结构。Capstone对目标程序逆向成汇编指令,FW-Fuzz在一些地址设置断点,然后能够让程序不断地运行。一旦程序到达了插桩的地址,GDB就可以把运行信息导出。

2. 错误检测
GDB会把错误信息以core的形式保存下来。
3. 优化插桩算法
- 首先从pc寄存器的地址对二进制进行反汇编得到反汇编后的指令集。
- 找到最近的一个分支。在分支跳转地址上插桩。
- 构建一个CFG,在CFG每个跳转的地址处插桩。
4.测试用例生成
测试用例的生成不仅和协议的格式有关,还和运行时获取到饿信息有关。
有两种模式:浅模式和深模式。
浅模式:
把输入的不同字段发送给目标程序,看哪个字段没有被处理,没有被处理的字段就不再变异。
深模式
根据代码覆盖率计算每个测试用例的适应度,用队列保存测试用例,选择高适应度的测试用例。
适应度计算原则:发现的新路径越多越好,一个testcase执行的新路径次数越多越好,越早发现新路径越好。
分母是执行这个testcase之前发现的所有分支,分子中New_branch是这个输入发现的所有新的分支,Hit_num(i)是k, 2 k < 实 际 覆 盖 次 数 < 2 k + 1 2^k <实际覆盖次数<2^k+1 2k<实际覆盖次数<2k+1。
Find_time是发现第一个新分支时执行的分支数除以这个测试用例总共执行的分支数,那么这个值越小说明发现的越早。(原文写的是大,感觉有点问题)
变异的方法用的是Sulley的变异方法,根据数据类型去变异。
调度策略会把分低的测试用例给去掉。

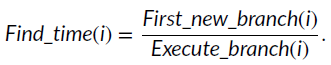
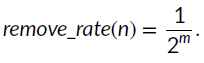
实验
目标程序:
 baseline: peach, boofuzz.
baseline: peach, boofuzz.
衡量指标:edge coverage、漏洞发现数量
部分原文摘抄
- On the one hand, as Marius Muench concluded, there are challenges of fuzzing firmware: fault detection, performance axsnd scalability, and instrumentation. These challenges limit the state-of-art greybox fuzzing techniques to gain the insight information of the firmware program to guide the generation of input cases. Some researchers attempt tofuzz thefirmware infull emulation or partial emulation environment. However, thedata flowof thesimulated execution is frequently different from the actual execution, whichmay fail to capture errors in the firmware program. And the type of architecture supported by the simulation is limited by Qemu.
其他相关论文
- Muench M, Stijohann J, Kargl F, Francillon A, Balzarotti D. What you corrupt is not what you crash: challenges in fuzzing embedded devices. NDSS. San Diego, California: The Internet Society; 2018.















 1998
1998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









