







SPFuzz: A Hierarchical Scheduling Framework for Stateful Network Protocol Fuzzing
| 论文题目 | SPFuzz: A Hierarchical Scheduling Framework for Stateful Network Protocol Fuzzing |
|---|---|
| 工具名称 | SPFuzz |
| 论文来源 | IEEE Access 2019 |
| 一作 | Congxi Song 国防科技大学计算机学院 |
| 文章链接 | https://ieeexplore.ieee.org/document/8626141 |
背景及相关工作
网络协议描述了网络数据包的格式以及网络断点之间的通信方式。网络协议的漏洞检测十分重要。目前很多研究使用fuzzing来检测网络协议的漏洞。
- Peachfuzz 可以通过XML文件定义协议的数据模型和状态模型等,并且能够解析响应。
- SNOOZE 根据XML中对协议的描述根据定义号的fuzzing场景生成测试用例。
- Boofuzz 是一个由Sulley拓展而来的基于python的fuzzing框架,他能够维护状态并识别故障。该框架实现了用于描述不同类型消息字段的原语以及用于生成测试用例的变异库。
Aspfuzz 基于RFC生成测试用例。
AutoFuzz 提取client和server之间的有限状态机,通过GMS模板查找并标记有价值的消息字段。
SecFuzz 从sequence, payload和field三个角度定义变异策略。
Ruiiter and Poll基于Learnlib state machine提取状态转移。
挑战
- 有状态的协议fuzzing很难维护一个状态。
fuzzing 类似于FTP这样的有状态的协议,fuzzer需要维护一个状态机,并且基于这个状态机去fuzz一个目标状态。- 很难处理依赖。
对于大部分的有状态的协议,它有很多内部或者消息之间的依赖。比如校验和字段和长度字段就取决于内容。之前收到的消息可能携带了之后所需要的认证或者加密的信息。这些依赖影响了我们能否生成有效的测试用例。- 很多框架都根据协议格式设置不同的变异方式,这个可能影响输入的非预期性和随机性导致一些代码不能被覆盖。
模型框架
由描述文档、解析器、调度模块、变异模块以及目标server组成。如下图所示。
描述文档描述message的每个字段的格式和字段之间的依赖,以及状态之间的转换。这个文档需要用户写。
解析器将描述文档的内容解释成测试用例对象以及消息队列。
调度模块调度fuzzing引擎去进行head,content以及sequence三个阶段进行变异,并且负责处理依赖以及交互。
变异引擎用AFL这样的工具来生成测试用例。
目标服务器用于接收测试用例然后发出响应。

描述文档
包括协议格式、协议状态、协议的依赖。
这个文档要描述协议的格式以及消息内部和消息之间的关系,但是不需要定义每个字段。他这里有个message weight可以定义这个message在协议中的重要性。他会影响这个message被fuzz的概率。还要描述状态之间的转移来构建消息序列。
协议涉及到两方面的依赖。一方面是消息的不同字段之间的依赖,比如length取决于content字段的长度。另一方面是消息之间的依赖。这里论文根据依赖给出了依赖的定义方式。

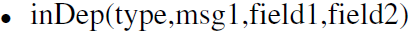
分层变异策略
论文提出了分层次的变异策略包括头部,内容,序列。
- head:这里的策略就是根据头的不同字段的数据类型给不同的变异范围。
- content:这里他就是用AFL的变异策略对content部分进行变异。然后根据content的数据,head的部分字段也应该更新。
- sequence:打乱消息序列来提高代码覆盖率。
模型实现
- 变异模块:就是根据分层变异策略去进行变异。
- 变异模块将head和content分开变异,所以后面需要将这两个字段连接起来并且做一些调整。
- 依赖处理:生成一个测试用例之后,根据用户定义的依赖把不合理的地方给改正确。消息之间的依赖,他会有一个cache存储之前的消息,然后根据依赖去修改当前的消息。
- 通讯调度模块:由一个socket和一个状态监控器组成。用于给server发送和接收server的消息。变异模块将消息进行变异,然后把消息发送给目标程序,目标程序返回response和traces of processes,来引导下一轮的变异。
实验
metrics: crashes, path coverage.
target program: FTP, TLS.
本文用于本人记录论文主要内容方便之后查看。















 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









