






读完《EnlightenGAN: Deep Light EnhancementWithout Paired Supervision》有一些自己的想法,随手而写,随性而想,以便此后自我纠正此刻的想法。
目的(作者为何提出EnlightenGAN):对于低光增强问题,给定低光图像可能没有唯一或明确定义的high-light ground truth(言外之意就是对一一张Input,没有明确的ground truth(可以是清晨,可以使中午,可以是下午3点等..))。例如,从黎明到黄昏拍摄的任何照片都可以被视为同一场景在午夜拍摄的照片的高光版本。受这两篇文章启发《Unpaired image-to-image translation using cycle-consistent adversarial networks》、《Unsupervised image-to-image translation networks》
相关工作:
图1-可知,主要是提出了EnlightenGAN,是一个U-Net生成器,Global-local做判别器的一种GAN网络,提出一种Self Feature Preserving Loss。
图2-只是作者对自己算法结果的一种展示,直观上看感觉还不错,但对日光强的一些地方增强较弱,对暗部区域增强效果不错。

图3是EnlightenGAN的整体结构,作者在这里提了一下没有使用cycleGAN(循环一致性,即input经过G生成、D判别,得到ouput之后再经过一个映射能否得到input)。
对整个网络结构,输入input ,获取其照明通道(应该是亮通道原理:LIME里有介绍)利用正则化将其归一化为[0,1],进行1-I进行图像反转,将照明像素反转,内容像素突出,突出局部案光特征,进行attention操作(同时也方便了对局部暗光处的处理),进行endocer-decoder操作,并进行网络中的skip-connection。最后与输出图像相称与input相加得到ouput。
ouput之后进入global-local模块,利用非监督图像进行光照训练学习,对ouput的光进行全局-局部的增强,并在增强过程中加入相应Perceptual Losses
一: Global-Local Discriminators
引入相对论判别器结构[1]估计真实数据比虚假数据更真实的概率,指导生成器合成比真实图像更真实的伪图像。
《The relativistic discriminator: A key element missing from standard GAN》
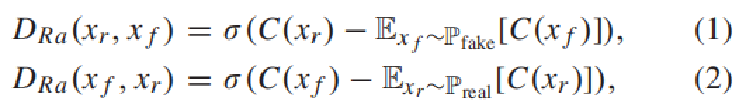
D(xr,xf)是判别器D分布,D(xf,xr)是生成器G分布,其中C表示判别器,xr和xf分别表示真和假的分布,σ 表示sigmoid激活函数。
为什么引入相对论判别器,因为使用非饱和Loss_G,相对判别器结构能在判别初期提供更好的梯度信息,训练初期 D(G(z))趋近于0(因为刚开始生成的图像很假,判别为真的概率为0),此时log(1-D(G(z)))≈ 0,梯度为0。 而对此公式取反,求图像为假的概率则为1,那么梯度就会存在。
之后为了进一步防止在计算过程中梯度消失问题,用最小二乘GAN(LSGAN)损失代替了sigmoid函数,最后全局判别器D和生成器G的损失函数为:
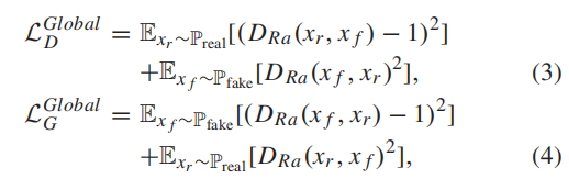

常数a、b分别表示真实图片和生成图片的标记;c是生成器为了让判别器认为生成图片是真实数据而定的值。可查看《Least Squares Generative Adversarial Networks》
本文作者认为以交叉熵作为损失,会使得生成器不会再优化那些被判别器识别为真实图片的生成图片,即使这些数据与真实数据的边缘有些距离,意味着还没干啥job finished。为什么生成器不再优化优化生成图片呢?是因为生成器已经完成我们为它设定的目标——尽可能地混淆判别器,所以交叉熵损失已经很小了。而最小二乘法就是尽可能拉近生成数据与真实数据之间的差距,尽可能的往决策边界拉近。
二:Self Feature Preserving Loss
Perceptual Losses来自这篇文章《Perceptual Losses for Real-Time Style Transfer__and Super-Resolution》
Perceptual Losses (感知损失)函数是将真实图片卷积得到的feature与生成图片卷积得到的feature作比较,本篇文章中将其加入U-net处作用是(限制输入的低光与其增强的正常光输出之间的VGG特征距离)。
提取VGG特征是因为当操纵输入像素强度范围时,VGG模型的分类结果不是很敏感,称其为自特征保留损失,是为了强调其自正则化的实用性,使图像内容特征在增强前后保持不变。(限制输入的低光与其增强的正常光输出之间的VGG特征距离)
为什么叫自正则化感知损失呢,
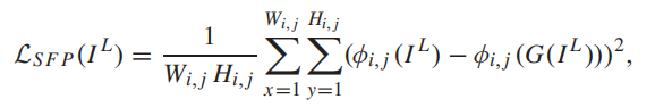
IL 表示输入的低光图像,G (IL)表示生成器的增强输出。ϕi,j表示预训练的特征图 i 表第i个最大池化,j 表示第i个最大池化之后的第j个卷积层。
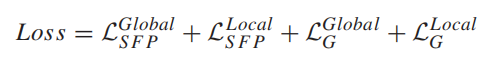
对局部判别器,从输入和输出图像中裁剪出的局部小块也通过类似定义的自特征保留损失L_SFP^Local进行正则化。 此外,在VGG特征映射后添加了一个实例归一化层,然后再将其加入到L_SFP和L_SFP^Local中, 以稳定训练。
图4作者做了几个模块的消融比较,可以看出图像对光照强烈的地方优化并不是太好,感觉可以适当优化调整照明通道的取值问题 。


最后作者做了一些对比实验。
总体来说,很优秀的一篇文章!
第一次写笔记,思路有点乱,理解错的地方会进行修改更新。
到此结束。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









