







DBSCAN(具有噪声的基于密度的空间聚类应用)是一种非常有用的聚类算法,它的主要优点是不需要用户先验地设置簇的个数,可以划分具有复杂形状的簇,还可以找出不属于任何簇的点。DBSCAN比凝聚聚类和k均值稍慢,但仍可以扩展到比较大的数据集。
DBSCAN的原理是识别特征空间的“拥挤”区域中的点,在这些区域中许多数据点靠近在一起。这些区域被称为特征空间中密集的密集区域。DBSCAN背后的思想是,簇形成数据的密集区域,并由相对较空的区域分隔开。
在密集区域的点被称为核心样本,他们的定义:
DBSCAN有两个参数 min_samples和eps。如果在距一个给给定数据点eps的距离内至少有min_samples个数据点,那么这个数据点就是核心样本。
DBSCAN将彼此距离小于eps的核心样本放在同一个簇中。
算法首先选取任何一个点,然后找到距离这个点的距离小于等于eps的所有的点。如果距离起始点的距离在eps之内的数据点个数小于min_samples,那么这个点被标记为噪声,也就是说这个点不属于任何簇。如果距离在eps内的数据点大于min_samples,那么这个点被标记为核心样本,并被分配一个新的簇标签。然后访问该点的所有在eps距离之内的邻居。如果他们还没有被分配给一个簇,那么就将刚刚创建的新的簇标签分配给他们。如果他们是核心样本,那么就继续依次访问其邻居,以此类推。簇逐渐增大,知道在簇的eps距离内没有更多的样本为止。然后在选取另一个未被访问过的点,并重复相同的过程。
最后,一共有三种类型的点:核心点,与核心点的距离在eps之内的点(边界点)和噪声。如果DBSCAN算法在特定的数据集上多次运行,那么核心点的聚类始终相同,同样的点也始终被标记为噪声。
但边界点可能与不止一个簇的核心样本相邻,所以,边界点所属的簇依赖于数据点的访问顺序。一般来说只有很少的边界点,这种对访问顺序的轻度依赖并不重要。
与凝聚聚类相似,DBSCAN也不允许对新的测试数据进行预测,所以使用fit_predict方法来执行聚类并返回簇标签。
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_blobs
X,y=make_blobs(random_state=0,n_samples=12)
dbscan=DBSCAN()
clusters=dbscan.fit_predict(X)
print('簇标签:\n{}'.format(clusters))

所有数据点都被分配了标签 -1,这代表噪声。这是eps和min_samples默认参数设置的结果,对于小型的数据集并没有调节这些参数。两参数取不同值时的簇分类如下:
import mglearn.plots
import matplotlib.pyplot as plt
mglearn.plots.plot_dbscan()
plt.show()
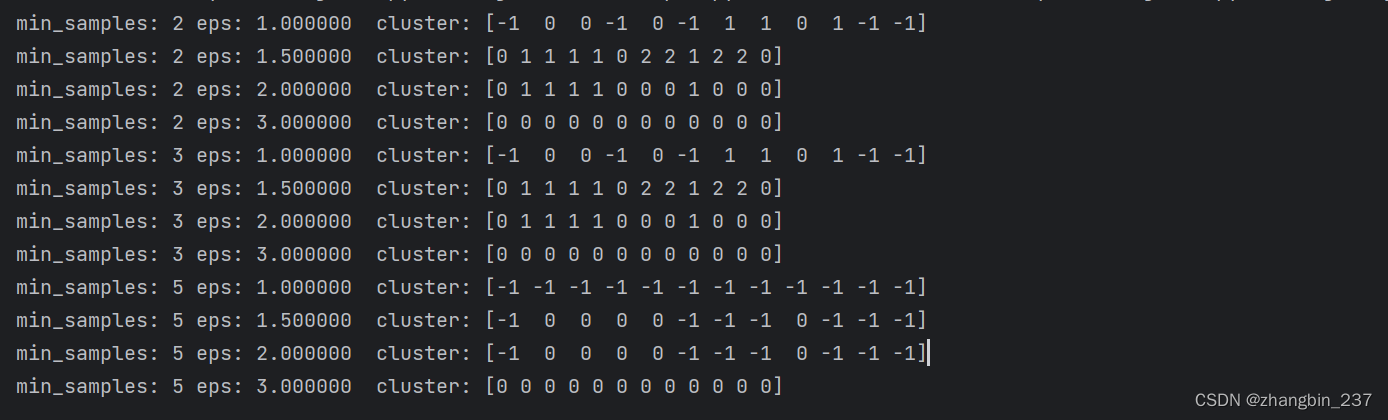
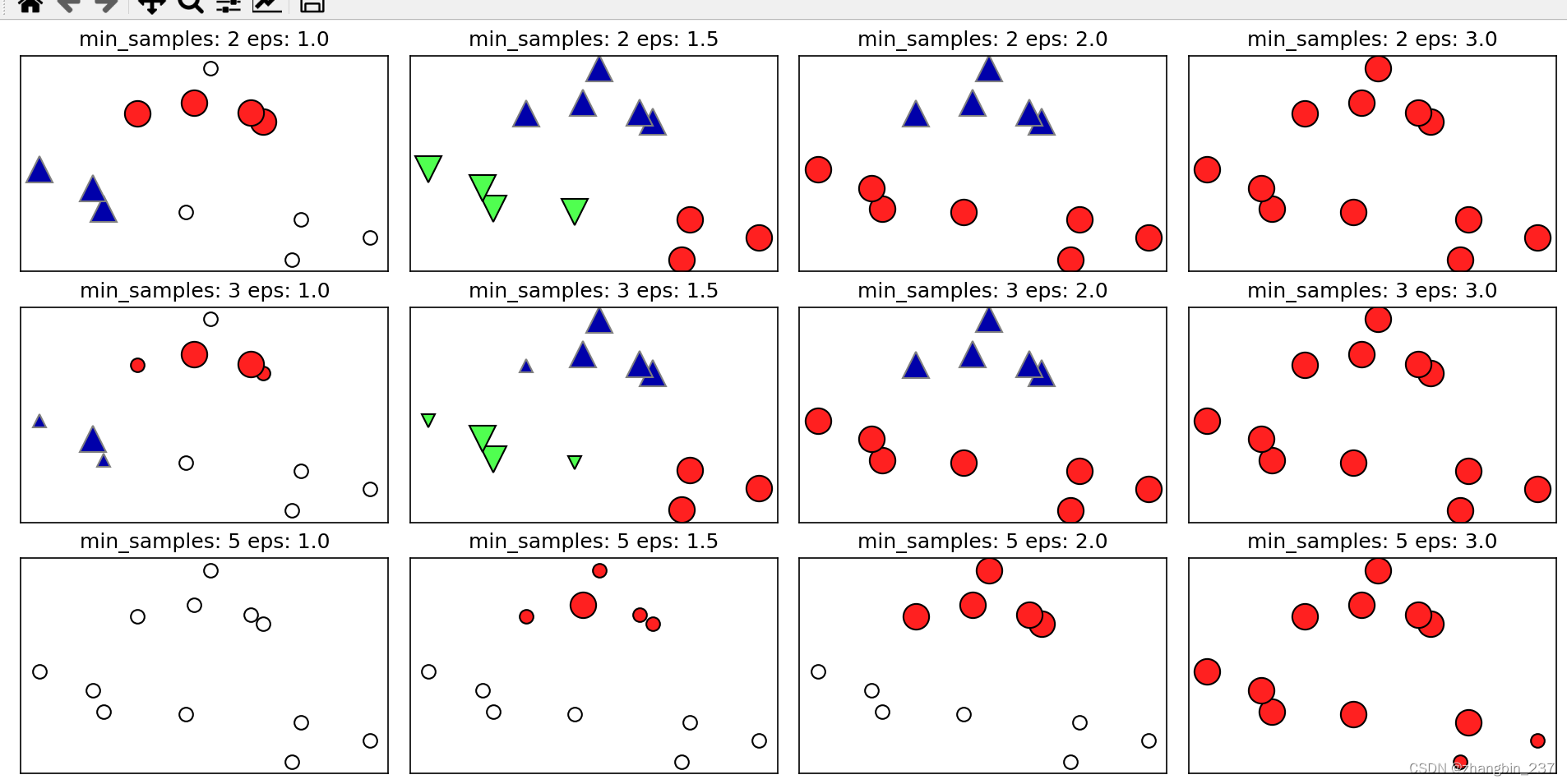
在这张图里,属于簇的点是实心的,而噪声是空心的。核心样本显示为较大的标记,边界点显示为较小的标记。增大eps,更多的点会被包含在一个簇中。这会让簇变大,但也可能会导致多个簇合并为一个。增大min_samples,核心点会变得更少,更多的点被标记为噪声。
参数eps在某种程度上更重要,因为它决定了点与点之间“接近”的含义,如果eps设置的过小,意味着没有核心样本,所有的点都被标记为噪声;eps设置的过大,可能所有的点形成同一个簇。
设置min_samples主要是为了判断稀疏区域内的点被标记为异常值还是形成自己的簇。如果增大min_samples,任何一个包含少于min_samples个样本的簇现在将被标记为噪声。因此min_samples决定了簇的最小尺寸。
虽然DBSCAN不需要显式地设置簇的个数,但设置eps可以隐式地控制找到的簇的个数。使用StandardScaler或者MinMaxScaler对数据进行缩放之后,有时会更容易找到eps的较好取值,因为使用这些缩放技术将确保所有特征具有相似的范围。
import mglearn.plots
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import DBSCAN
X,y=make_moons(n_samples=200,noise=0.05,random_state=0)
scaler=StandardScaler()
scaler.fit(X)
X_scaled=scaler.transform(X)
dbscan=DBSCAN()
cluters=dbscan.fit_predict(X_scaled)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(X_scaled[:,0],X_scaled[:,1],c=cluters,cmap=mglearn.cm2,s=60)
plt.xlabel('特征0')
plt.ylabel('特征1')
plt.show()
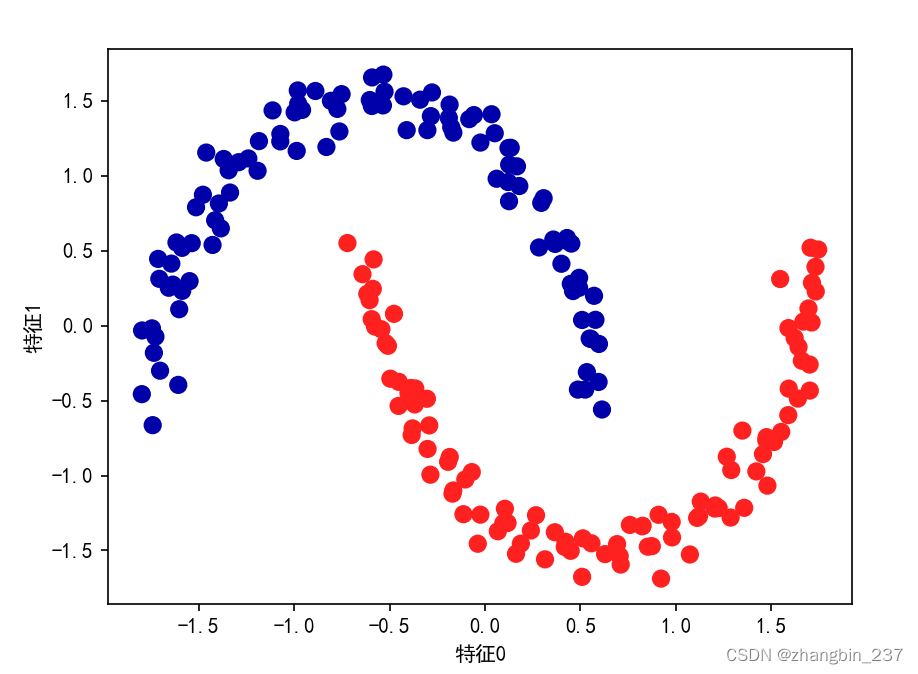
上图展示了在two_moons数据集上运行DBSCAN的结果。利用默认设置,算法找到了两个半圆形并将其分开。
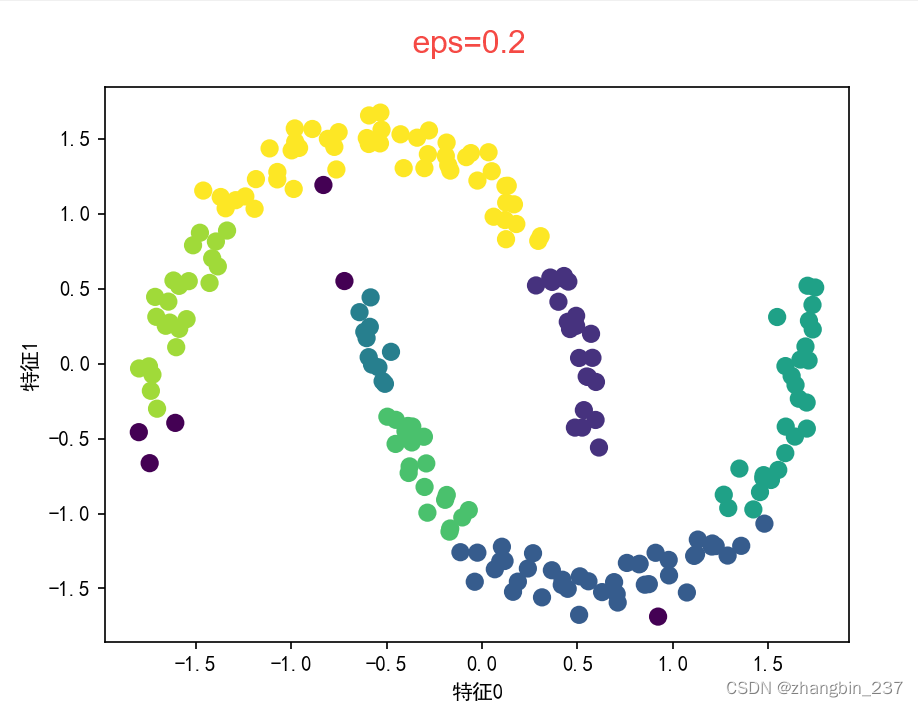
由于算法找到了我们想要的簇的个数,因此参数设置的效果似乎很好。如果将eps减小到0.2,(默认为0.5),我们将会得到8个簇;增大到0.7将导致只剩一个簇















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









