





本文选自 《交易技术前沿》总第三十一期文章(2018年6月)
郑福来 / 恒生电子股份有限公司
1背景介绍
1.1NLP介绍
NLP (Natural Language Processing) 是人工智能(AI)的一个子领域,它致力于使用计算机理解人类语言中的句子或词语。NLP 以降低用户工作量并满足使用自然语言进行人机交互的愿望为目的。因为用户可能不熟悉机器语言,所以 NLP 就能帮助这样的用户使用自然语言和机器交流。 NLP在金融领域目前已经有广泛的使用场景,比如:
自动文摘–通过NLP技术对金融领域的新闻、研究报告、上市公司的公告进行分析,生成自动文摘和机器自动写作;
情感分析–对新闻、评论等文本中的主观性信息进行分析,来挖掘其态度和情绪,实现情感倾向性分析和观点挖掘;
事件分析–基于热点事件,然后结合行业产业链、知识图谱和推理决策系统的推理体系,针对个股和行业,生成研究报告和及时报告;
热点挖掘–基于最新的新闻资讯,聚类出当前的热点资讯,提取摘要;
智能客服–通过NLP的意图识别,问答相似度分析,语义理解等,可以用机器代替人工客服.
1.2意图识别
意图识别是通过分类的办法将句子或者我们常说的query分到相应的意图种类,这在搜索引擎以及智能问答中都起很重要的作用。简单来说,就是当用户输入一句话或者一段文本时,意图识别可以准确识别出它是哪个领域的问题,然后分配给相应的领域机器人进行二次处理,这在问题分类很多的情况,可以明显提升问题匹配的准确度。
举个例子说明一下:假设目前我们的客服机器人后端接有投资建议(advice)、投资教育(edu)、FAQ领域机器人(faq),它们对应的语料分别为:
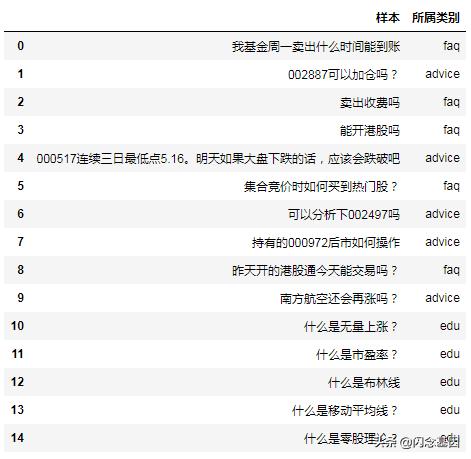
那么当用户提问后,通过意图识别模块后,就可以将当前问题交由相应后续的领域机器人处理,比如投资建议类会进一步进行语义分析,然后调用API接口返回结果,投资教育类的会调用百科类的API返回结果,FAQ类的问题可能直接转到人工客服的接口。
目前常用的意图识别的基本方法,有如下几种:
1.基于词典以及模版的规则方法
不同的意图会有的不同的领域词典,比如书名、歌曲名、商品名等等。我们根据用户的意图和词典的匹配程度或者重合程度来进行判断,最简单的一个规则是将该query判别给与词典重合程度高的domain。这个工作的重点便是领域词典必须得做地足够好。
2.基于机器学习模型来对用户的意图进行判别
这种主要是通过机器学习及深度学习的方式,对已标注好的领域的语料进行训练学习,得到一个意图识别的模型。利用该模型,当再输入一个测试集时,它能快速地预测出该语料对应的分类,并提供对应的置信度。使用这种方式的一个好处就是,在语料不断丰富后,模型的准确度会不断提升。 本文主要介绍的就是采用这种方式进行意图识别。
1.3fastText介绍
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够在10分钟之内训练10亿词级别语料库的词向量,在1分钟之内分类有着30万多类别的50多万句子。
fastText 模型架构如下图所示。fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
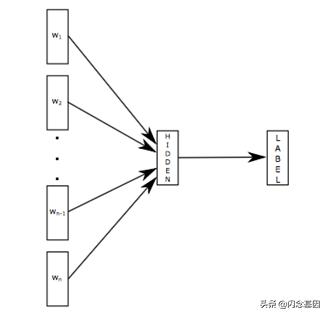
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。fastText使用到两个tricks,一是通过构建一个霍夫曼编码树来加速softmax layer的计算,从而降低算法的时间复杂度,所以它在分类特别多的时候效果会更加明显。二是通过加入N-gram features进行补充,然后用hashing来减少N-gram的存储。
2意图识别框架
2.1整体说明
为了更好地把fastText应用到意图识别中,所以对官方的fastText进行了工程化的封装,提供意图识别的一体化训练与预测的工具,可支持后续新项目的快速上线使用,每个项目只需要关注本项目的问答语料以及参数的调整与优化,关于模型的上线发布与训练,由该框架统一处理。
目前该框架目前主要支持以下特性:
1.快速新增以及调整语料的分类,不需要修改代码
2.模型参数调优,可自由调整,不需要修改代码
3.可以输出不同类别的分类性能,进行针对性调优
4.依赖包集成化,解决包依赖问题,可以快速客户现场部署而不需要提供原代码
5.提供验证集入口,可以快速评估模型的性能
2.2架构原理介绍
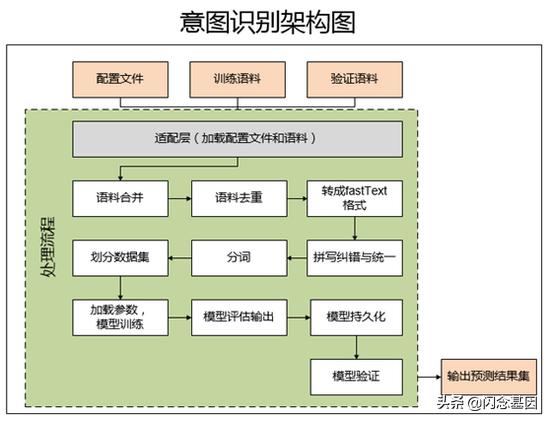
项目中的配置文件,训练语料以及验证语料都是在整个意图识别的框架之外,通过适配层进行加载进入框架中。这样的好处就是进行了资源的隔离,同时增加了配置的灵活性,不同的项目只要准备好本项目相关的训练资源就可以快速启动。
开启模型训练时,会进行语料的处理,包含了语料的合并、语料去重、转成fastText格式、拼写纠错与统一、分词、划分数据集等操作,并将生成的清洗后的语料存在本地磁盘,供验证预处理结果是否准确。由于每次训练前都会经过预处理的操作,所以调整了训练语料都会及时处理,提高实时性。
模型训练过程中,会加载预置的模型参数,以及清洗后的语料,生成模型,并持久化到磁盘中,使用其在测试集上得出相应的f1值作为模型文件名。持久化后的模型可以直接加载,减少训练过程,提高效率。
为了更好评估模型的性能,可以直接准备验证集(未参与过训练的语料),然后调过模型的验证接口得到预测的结果集,如果不满足要求,可以重新调整参数与语料进一步优化模型。
2.3项目演示
这里以某智能客服的案例进行演示,说明如何使用该框架:
2.3.1语料的准备
每一个分类存储一个csv文件,文件名为该分类的英文名,这些原始语料不需要进行额外的预处理,框架启动训练时,会自动完成语料的合并,去重,以及分词等操作,并生成一个完整的训练语料。同时支持新的分类语料直接加入,可以同步增加新分类的意图识别,无须修改代码,提高框架可扩展性。
以下是advice分类样本的原始语料的示例说明:

以下是将advice,faq,edu三个类别的语料进行预处理,合并后的训练语料的示例说明:
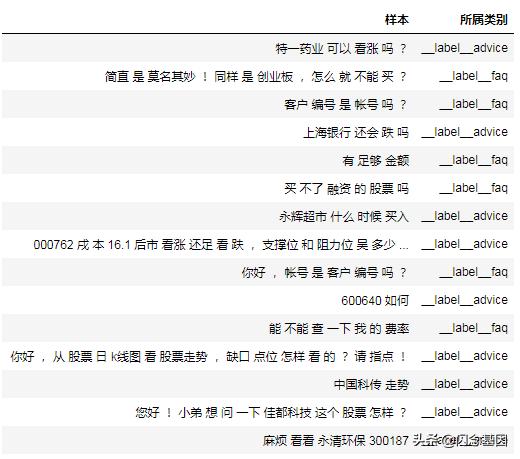
2.3.2配置文件说明
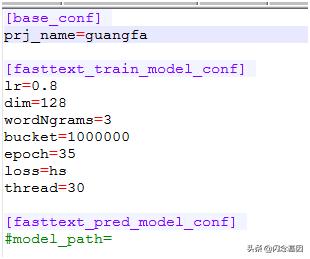
其中fasttext_ fasttext_train_model_conf_conf包含了fastText模型的一些模型参数配置。
主要参数说明及建议:
lr:学习率,调小时,训练时间会变长,效果会有提升
dim:词向量的维度
wordNgrams:n-gram语言模型(几元语法)
bucket:桶数量,如果词数不是很多,可以把bucket设置的小一点,否则预留会预留太多bucket使模型太大
epoch:训练次数,根据需要调整
loss:损失函数,推荐选用hs(hierarchical softmax)要比ns(negative sampling) 训练速度要快很多倍,并且准确率也更高
thread:并行的线程数,根据机器配置,可以调大该数值
2.3.3模型训练
训练前项目路径:
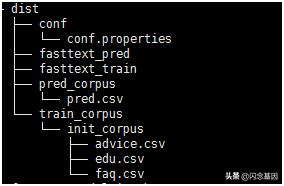
其中fasttext_train即为本文提及的意图识别的框架,当把语料与配置文件按约定的路径放好后,执行./fasttext_train即可开启训练;调用./fasttext_pred即可执行验证集的预测。
执行训练后的项目路径如下:
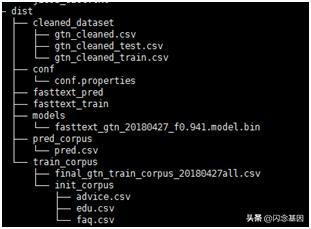
其中cleaned_dataset存放预处理后的语料,同时包含了训练集和测试集。由于该文件夹每次训练都会重新生成新的,可以保证语料的同步更新。 其中models存放着每次训练生成的模型文件,以供下次可以直接加载,不需要重新训练生成。
2.3.4模型评估
本次一共采用了124450条样本,然后按1:3的比例划分测试集与训练集,因为采用的是分层采样,基本上每个分类也满足该比例,具体分布如下图所示:
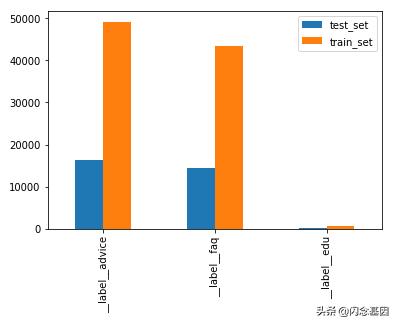
在训练集上跑出模型在测试集上的效果如下:
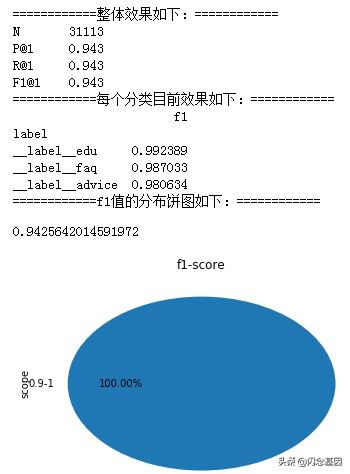
另外提供了317条的验证集,该模型在验证集上的效果,如下的混淆矩阵:
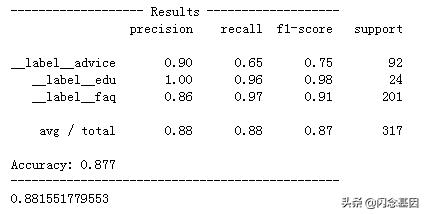
除了在advice标签上的召回率和f1值相对低了一些,其它的标签测试效果都比较理想,基本都在95%以上,能满足初步预期的结果。
3经验总结
3.1关于语料标注
当前意图识别工作的难点有很多,最大的难点在于标注数据的获取。可采用的方式:
1.专门的数据标注团队对数据进行标注
2.通过对语料进行泛化,手动造出更多相似的语料
3.通过半监督的方式自动生成标注数据,然后再人工审核
3.2关于模型调优
模型的调优主要可以从以下几个方面入手:
1.如果清洗完的训练语料有分词不准的情况,需要增加相应的词林
2.对于分不准的类别,重着观察这一块的语料是否在训练语料中被分错了类别
3.模型的训练参数的调整
4.考虑增加其它模型进行模型的融合,保障最后的意图识别的性能
4参考文献
1) 《超快的 fastText》















 8184
8184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









