





TP、TN、FP、FN
对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。

准确率(accuracy)、查准率(precision)、查全率(recall)
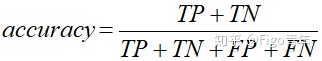
表示正确分类的比例
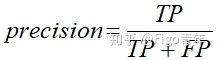
表示分类器断定为正例的那部分记录中,实际为正例的记录所占的比例。
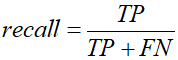
表示分类器正确预测的正例(实际为正类)的比例,它的值等于真阳性率。
混淆矩阵
如有150个样本数据,这些数据分成3类,每类50个。分类结束后得到的混淆矩阵为:
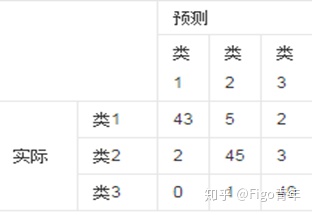
每一列的总数表示预测为该类的数据的数目
每一行的数据总数表示该类的数据实例的数目
本例中:
每一行之和为50,表示实际每个类都有50个样本。
第一行说明类1的50个样本有43个分类正确,5个错分为类2,2个错分为类3。
第一列表示有45个样本被预测成类1,43个正确预测,2个类2样本被错预测为类1。















 2764
2764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









